協助改進此頁面
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
若要為本使用者指南貢獻內容,請點選每個頁面右側面板中的在 GitHub 上編輯此頁面連結。
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 Amazon EKS 上載入並提供模型
提示
註冊
本節中的步驟會在 Amazon EKS 上部署大型語言模型 (LLM)、提供 vLLM,以及與推論端點互動。
演練使用下列工具:
-
vLLM
— 針對 LLM 服務和 GPU 記憶體管理進行最佳化的高輸送量推論引擎。 -
Run:ai 模型串流器
— 將模型權重直接從 Amazon S3 串流到 GPU 記憶體,將載入時間從幾分鐘縮短到幾秒鐘。 -
開啟 WebUI
— 連接至 vLLM OpenAI 相容 API 的自我託管聊天前端。
本節使用 Ministral-3-8B-Instruct-2512 模型
重要
使用您在 為 AI/ML 工作負載設定 Amazon EKS 叢集區段中建立的叢集。此演練中的指示適用於 EKS Auto Mode 和自我管理 Karpenter。
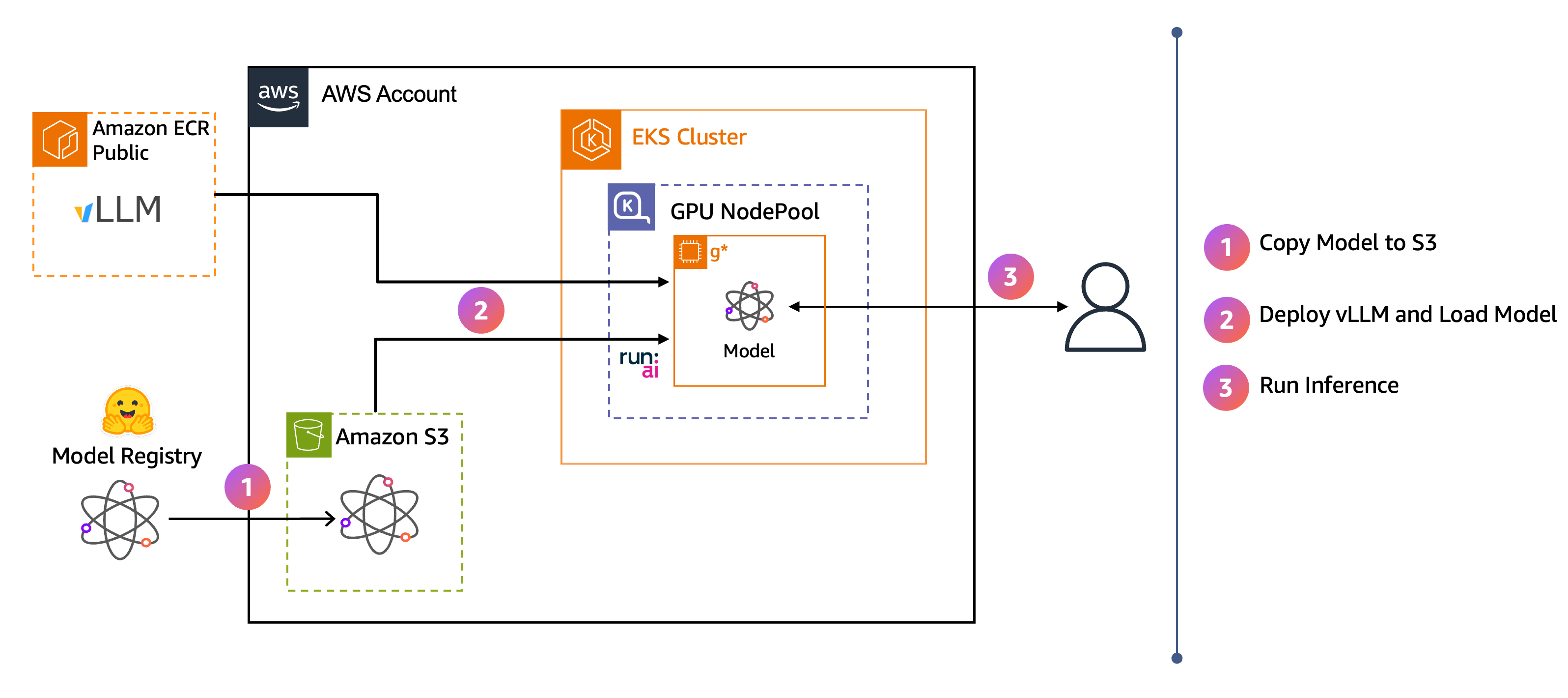
架構圖顯示end-to-end流程:
-
模型權重會從 Hugging Face 下載到 Amazon S3。
-
vLLM 使用 Run:ai Model Streamer,將模型直接從 S3 串流到 GPU 記憶體。
-
使用者將推論請求傳送至 vLLM 端點。
當您完成這些步驟時,您會有一個 vLLM 推論端點,可用來透過聊天前端應用程式與 Ministral 模型互動。
先決條件
完成叢集設定區段中的步驟。
如果您開啟新的終端機,請透過 CLI 區段設定您在叢集設定中使用的叢集名稱和區域:
export CLUSTER_NAME=ai-eks-docs export AWS_REGION=us-east-2
查詢您在模型權重 S3 儲存貯體步驟中建立的模型權重儲存貯體:
MODEL_BUCKET=$(aws s3api list-buckets \ --query "Buckets[?starts_with(Name, '${CLUSTER_NAME}-models-')].Name | [0]" \ --output text) echo "Model bucket: ${MODEL_BUCKET}"
步驟 1:從 Hugging Face 下載模型
在此步驟中,您會部署從 Hugging Face 下載模型的 Kubernetes 任務,並將其上傳至您在先決條件區段中建立的 S3 儲存貯體。
若要下載模型,請套用下列任務資訊清單:
cat << EOF | kubectl apply -f - apiVersion: batch/v1 kind: Job metadata: name: model-download namespace: default labels: guide: ai-eks-docs spec: backoffLimit: 10 activeDeadlineSeconds: 3600 ttlSecondsAfterFinished: 86400 template: spec: restartPolicy: Never serviceAccountName: model-storage-sa containers: - name: downloader image: python:3.11-slim command: ["/bin/bash", "-c"] args: - | set -e pip install -q huggingface_hub boto3 echo "Downloading Ministral-3-8B-Instruct-2512 from Hugging Face..." python3 -c "from huggingface_hub import snapshot_download; snapshot_download('mistralai/Ministral-3-8B-Instruct-2512', local_dir='/tmp/mistral', allow_patterns=['*.json', '*.txt', '*.md', 'consolidated.safetensors'], ignore_patterns=['model-*.safetensors', 'model.safetensors.index.json'])" echo "Uploading to S3 bucket: \${MODEL_BUCKET}" python3 << 'PYTHON' import boto3 import os from pathlib import Path s3 = boto3.client('s3') bucket = os.environ.get('MODEL_BUCKET') local_dir = Path("/tmp/mistral") for file_path in local_dir.rglob("*"): if file_path.is_file(): if '.cache' in file_path.parts: continue s3_key = f"Ministral-3-8B-Instruct-2512/{file_path.relative_to(local_dir)}" print(f"Uploading {file_path.name}...") s3.upload_file(str(file_path), bucket, s3_key) print("Upload complete!") PYTHON env: - name: MODEL_BUCKET value: "${MODEL_BUCKET}" - name: HF_HUB_DISABLE_XET value: "1" resources: requests: memory: "2Gi" cpu: "1" limits: memory: "4Gi" cpu: "2" EOF
等待任務完成。模型權重 (consolidated.safetensors) 約為 10.4 GB,此步驟通常需要 3-5 分鐘。
kubectl wait --for=condition=complete job/model-download --timeout=600s
預期的輸出結果:
job.batch/model-download condition met
確認模型權重已上傳至 S3:
aws s3 ls s3://$(kubectl get job model-download -o jsonpath='{.spec.template.spec.containers[0].env[?(@.name=="MODEL_BUCKET")].value}')/Ministral-3-8B-Instruct-2512/ --recursive
預期的輸出結果:
2026-05-18 10:29:53 20311 Ministral-3-8B-Instruct-2512/README.md 2026-05-18 10:29:53 2361 Ministral-3-8B-Instruct-2512/SYSTEM_PROMPT.txt 2026-05-18 10:29:53 1903 Ministral-3-8B-Instruct-2512/config.json 2026-05-18 10:29:54 10420633176 Ministral-3-8B-Instruct-2512/consolidated.safetensors 2026-05-18 10:29:53 131 Ministral-3-8B-Instruct-2512/generation_config.json 2026-05-18 10:29:53 1185 Ministral-3-8B-Instruct-2512/params.json 2026-05-18 10:29:53 976 Ministral-3-8B-Instruct-2512/processor_config.json 2026-05-18 10:29:53 16753777 Ministral-3-8B-Instruct-2512/tekken.json 2026-05-18 10:29:53 17077402 Ministral-3-8B-Instruct-2512/tokenizer.json 2026-05-18 10:29:53 21168 Ministral-3-8B-Instruct-2512/tokenizer_config.json
consolidated.safetensors 檔案包含模型權重 (約 10.4 GB)。其餘檔案是 vLLM 提供模型所需的組態和權杖化工具檔案。
步驟 2:部署推論容器
在本節中,您將 vLLM 部署為 Kubernetes 部署,以提供您上傳至 Amazon S3 的模型。
本節使用AWS 深度學習容器
此部署針對具有 SOCI 支援的 vLLM 0.21.0
public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci
映像標籤指出具有 GPU 支援的 vLLM 0.21.0、Python 3.12、CUDA 13.0、Ubuntu 22.04、針對 EC2-based工作負載最佳化,以及啟用 SOCI 的容器啟動速度更快。
此資訊清單會建立在 GPU 節點上執行 vLLM 的部署,並使用 Run:ai Model Streamer 將模型直接從 S3 串流至 GPU 記憶體。資訊清單也會建立 ClusterIP 服務,公開連接埠 8000 上的 vLLM 端點,以進行叢集內存取。
套用資訊清單:
cat << EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app labels: guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app guide: ai-eks-docs spec: serviceAccountName: model-storage-sa tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule nodeSelector: karpenter.sh/nodepool: gpu-inf containers: - name: vllm-inference image: public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci ports: - containerPort: 8000 args: - "--model=s3://${MODEL_BUCKET}/Ministral-3-8B-Instruct-2512/" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" - "--load-format=runai_streamer" - "--enforce-eager" - "--tokenizer_mode=mistral" - "--config_format=mistral" - "--enable-auto-tool-choice" - "--tool-call-parser=mistral" resources: limits: nvidia.com/gpu: 1 requests: memory: "40Gi" cpu: "8" --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc namespace: default labels: app: vllm-inference-app spec: selector: app: vllm-inference-app ports: - name: http port: 8000 targetPort: 8000 protocol: TCP EOF
檢查 vLLM Pod 是否處於就緒狀態:
kubectl get pod -l app=vllm-inference-app -w
預期的輸出結果:
NAME READY STATUS RESTARTS AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 Running 0 86s
容器映像提取 和 vLLM 將模型權重從 S3 串流到 GPU 記憶體可能需要約 2 分鐘。請等到 Pod 在 READY 1/1 欄中顯示後再繼續。
EKS、SOCI 和 Run:ai Model Streamer 的組合可快速啟動 Pod。若要檢查每個階段的啟動時間,請檢視 Pod 事件:
kubectl describe pod -l app=vllm-inference-app | grep -A 20 "Events:"
預期的輸出結果:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 86s default-scheduler 0/2 nodes are available: 2 node(s) had untolerated taint(s). Normal Nominated 85s eks-auto-mode/compute Pod should schedule on: nodeclaim/gpu-inf-kqkq6 Normal Scheduled 55s default-scheduler Successfully assigned default/vllm-inference-app-d9d54586d-csmd7 to i-04f8792414384d2d3 Normal Pulling 52s kubelet Pulling image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" Normal Pulled 4s kubelet Successfully pulled image "public.ecr.aws/deep-learning-containers/vllm:0.21.0-gpu-py312-cu130-ubuntu22.04-ec2-v1.0-soci" in 48.376s (48.376s including waiting). Image size: 8802823997 bytes. Normal Created 4s kubelet Created container vllm-inference Normal Started 4s kubelet Started container vllm-inference
在此範例中,GPU 節點佈建為 30 秒,並使用 SOCI 在大約 48 秒內提取 8.8 GB 容器映像。快速映像提取可減少大型推論容器的冷啟動時間,這可讓您動態擴展 GPU Pod,而不是過度佈建閒置 GPU 容量。
接著,檢查 vLLM 日誌以驗證模型載入時間:
kubectl logs $(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') | grep -i 'Model loading took'
預期的輸出結果:
INFO 05-18 18:41:49 [gpu_model_runner.py:4959] Model loading took 9.81 GiB memory and 5.023344 seconds
日誌確認 Run:ai Model Streamer 在大約 5 秒內將 10.4 GB 模型權重直接從 S3 載入 GPU 記憶體,耗用 9.8 GiB 的 GPU 記憶體。
此範例中的映像下載時間是使用 g6e.4xlarge 執行個體,其具有 20 Gbps 的持續網路頻寬。映像提取和模型載入時間會因其他執行個體類型而有所不同,具體取決於可用的網路頻寬。
步驟 3:執行推論
執行 vLLM 部署後,驗證推論端點並部署聊天前端以與模型互動。
執行模型驗證測試
透過連接埠轉送公開推論端點:
kubectl port-forward svc/vllm-inference-svc 8000:8000
開啟新的終端機視窗,然後驗證推論容器是否正在回應:
curl -sI -X GET http://localhost:8000/health
預期的輸出結果:
HTTP/1.1 200 OK date: Fri, 18 May 2026 00:39:23 GMT server: uvicorn content-length: 0
步驟 4:監控 vLLM
vLLM 開箱即用地公開 Prometheus 指標,包括請求率、字符輸送量、end-to-end延遲和 GPU KV 快取使用率。在本節中,您可以將這些指標與您在叢集設定步驟中設定的監控堆疊搭配使用,並在預先佈建的 Grafana 儀表板上檢視它們。
重要
您必須透過 CLI 完成叢集設定的監控子區段,才能繼續。此步驟取決於安裝的 kube-prometheus-stack,以及值檔案中已佈建的 vLLM Grafana 儀表板。
套用 vLLM ServiceMonitor
ServiceMonitor 會告知 Prometheus 在何處抓取 vLLM 指標。
cat << EOF | kubectl apply -f - apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: vllm-inference-app namespace: default labels: release: kube-prometheus-stack spec: selector: matchLabels: app: vllm-inference-app endpoints: - port: http path: /metrics interval: 15s EOF
確認 ServiceMonitor 已建立:
kubectl get servicemonitor vllm-inference-app
預期的輸出結果:
NAME AGE vllm-inference-app 5s
若要將指標填入儀表板,請針對您在驗證步驟中已透過連接埠向前公開的 vLLM 端點產生推論流量。
探索提供的模型名稱:
MODEL_NAME=$(curl -s http://localhost:8000/v1/models | jq -r '.data[0].id') echo "Using model: $MODEL_NAME"
平行傳送 50 個聊天完成請求:
for i in $(seq 1 50); do curl -s -X POST http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d "{\"model\": \"$MODEL_NAME\", \"messages\": [{\"role\": \"user\", \"content\": \"Write a short poem about Kubernetes.\"}], \"max_tokens\": 128}" \ > /dev/null & done wait
當流量正在流動時 (或之後),請直接從 vLLM /metrics端點檢查字符輸送量指標:
curl -s http://localhost:8000/metrics | grep -E '^vllm:(prompt_tokens_total|generation_tokens_total|avg_generation_throughput_toks_per_s|avg_prompt_throughput_toks_per_s)' | head
vllm:prompt_tokens_total 和 vllm:generation_tokens_total指標單調增加提供的輸入和輸出字符計數器。vllm:avg_prompt_throughput_toks_per_s 和 vllm:avg_generation_throughput_toks_per_s指標是滾動平均輸送量計量。這些相同的指標為您在下列小節中開啟的 Grafana 儀表板提供支援。
檢視 vLLM Grafana 儀表板
來自監控區段的 kube-prometheus-stack 值檔案已在 GPU 監控資料夾下佈建社群 vLLM 儀表板 (gnetId 25263)
若要存取 Grafana,請啟動連接埠轉送至 Grafana 服務:
kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n monitoring
在瀏覽器http://localhost:3000
vLLM Grafana 儀表板

儀表板會顯示 vLLM 推論端點的請求率、提示和產生字符輸送量、延遲百分位數和 GPU KV 快取使用率。
步驟 5:部署聊天應用程式
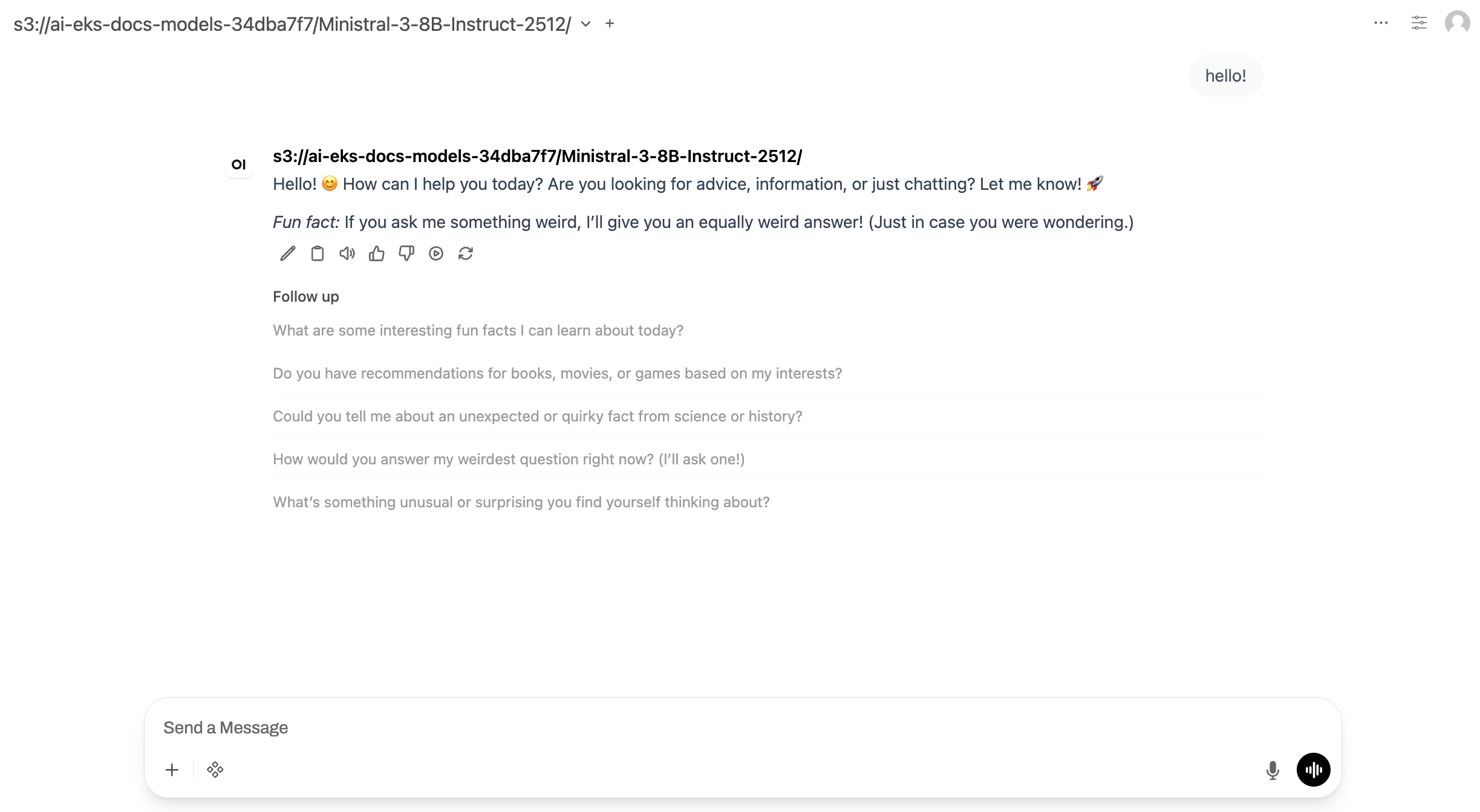
在此步驟中,您將 Open WebUI 部署為聊天前端,以與模型互動。Open WebUI 是一種開放原始碼、自我託管的 AI 介面,支援 OpenAI 相容 APIs,並提供具有對話歷史記錄和 Markdown 轉譯的聊天介面。由於 vLLM 公開與 OpenAI 相容的 API,因此 Open WebUI 會以後端直接與其連線。
若要部署 Open WebUI 應用程式,請套用下列資訊清單:
cat << 'EOF' | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: open-webui namespace: default labels: app: open-webui guide: ai-eks-docs spec: replicas: 1 selector: matchLabels: app: open-webui template: metadata: labels: app: open-webui guide: ai-eks-docs spec: containers: - name: open-webui image: ghcr.io/open-webui/open-webui:v0.9.2 ports: - containerPort: 8080 resources: requests: cpu: "500m" memory: "500Mi" limits: cpu: "1000m" memory: "1Gi" env: - name: OPENAI_API_BASE_URLS value: "http://vllm-inference-svc:8000/v1" - name: OPENAI_API_KEY value: "dummy" - name: WEBUI_AUTH value: "False" - name: ENABLE_OLLAMA_API value: "False" - name: ENABLE_EVALUATION_ARENA_MODELS value: "False" volumeMounts: - name: webui-volume mountPath: /app/backend/data volumes: - name: webui-volume emptyDir: {} --- apiVersion: v1 kind: Service metadata: name: open-webui namespace: default labels: app: open-webui spec: type: ClusterIP selector: app: open-webui ports: - protocol: TCP port: 80 targetPort: 8080 EOF
等待開放 WebUI Pod 就緒:
kubectl wait --for=condition=ready pod -l app=open-webui --timeout=300s
預期的輸出結果:
pod/open-webui-6cbfc9867f-jf9w9 condition met
若要存取應用程式,請在瀏覽器中設定連接埠轉送並開啟應用程式:
kubectl port-forward svc/open-webui 8080:80 & sleep 5 echo "Open WebUI: http://localhost:8080"
在瀏覽器http://localhost:8080
聊天介面隨即顯示,您可以在其中與 Ministral 模型互動。
當您完成測試時,請執行 kill %1 %2(或執行 jobs 以列出每個 和 ) 來停止背景連接埠轉送程序kill %<jobspec>。
清除
若要移除您在本節中建立的工作負載資源,請刪除 Open WebUI 應用程式、vLLM 推論伺服器和模型下載任務:
kubectl delete deployment open-webui kubectl delete service open-webui kubectl delete deployment vllm-inference-app kubectl delete service vllm-inference-svc kubectl delete servicemonitor vllm-inference-app kubectl delete job model-download
如需移除叢集、NodePool 和 S3 儲存貯體等基礎設施資源的說明,請參閱叢集設定清除。
