本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
檢視被動異常
在洞見中,您可以檢視 Amazon RDS 資源的異常。在被動洞察頁面上,在彙總指標區段中,您可以檢視具有對應時間軸的異常清單。也有部分顯示與異常相關的日誌群組和事件資訊。被動洞察中的因果異常各有對應的頁面,其中包含異常的詳細資訊。
檢視 RDS 反應異常的詳細分析
在此階段,深入探討異常狀況,以取得 Amazon RDS 資料庫執行個體的詳細分析和建議。
詳細分析僅適用於已開啟績效詳情的 Amazon RDS 資料庫執行個體。
向下切入異常詳細資訊頁面
-
在洞見頁面上,尋找資源類型為 AWS/RDS 的彙總指標。
-
請選擇檢視詳細資料。
出現異常詳細資訊頁面。標題開頭為資料庫效能異常,以及資源顯示的名稱。無論異常何時發生,主控台都會預設為嚴重性最高的異常。
-
(選用) 如果多個資源受到影響,請從頁面頂端的清單中選擇不同的資源。
您可以在下面找到詳細資訊頁面元件的說明。
資源概觀
詳細資訊頁面的頂端區段是資源概觀。本節摘要說明 Amazon RDS 資料庫執行個體遇到的效能異常情況。
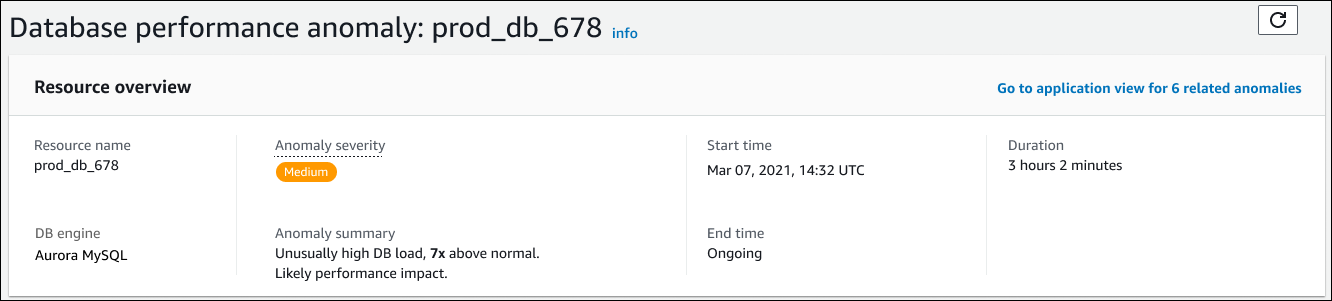
本節包含下列欄位:
-
資源名稱 – 遇到異常的資料庫執行個體名稱。在此範例中,資源名為 prod_db_678。
-
資料庫引擎 – 遇到異常的資料庫執行個體名稱。在此範例中,引擎為 Aurora MySQL。
-
異常嚴重性 – 異常對執行個體的負面影響度量。可能的嚴重性為高、中和低。
-
異常摘要 – 問題的簡短摘要。典型的摘要是異常高的資料庫負載。
-
開始時間和結束時間 – 異常開始和結束的時間。如果結束時間為進行中,表示仍發生異常。
-
持續時間 – 異常行為的持續時間。在此範例中,異常持續發生 3 小時又 2 分鐘。
主要指標
主要指標區段摘要說明意外異常,這是洞見中最上層的異常。您可以將因果異常視為資料庫執行個體遇到的一般問題。
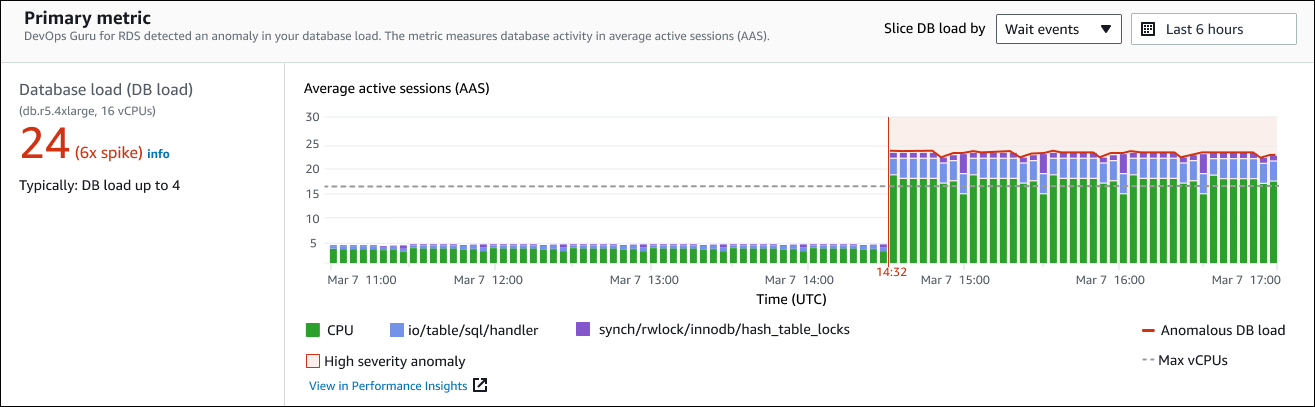
左側面板提供有關問題的更多詳細資訊。在此範例中,摘要包含下列資訊:
-
資料庫載入 (資料庫載入) – 異常分類為資料庫載入問題。績效詳情中的對應指標為
DBLoad。此指標也會發佈至 Amazon CloudWatch。 -
db.r5.4xlarge – 資料庫執行個體類別。vCPUs 的數量,在此範例中為 16,對應至平均作用中工作階段 (AAS) 圖表中的虛線。
-
24 (6 倍峰值) – 資料庫負載,在洞見中報告的時間間隔內以平均作用中工作階段 (AAS) 測量。因此,在異常期間的任何指定時間,資料庫中平均有 24 個工作階段處於作用中狀態。資料庫負載是此執行個體正常資料庫負載的 6 倍。
-
一般而言:資料庫負載最多 4 – 在一般工作負載期間,以 AAS 測量的資料庫負載基準。值 4 表示在正常操作期間,資料庫上在任何指定時間平均有 4 個或更少的工作階段處於作用中狀態。
根據預設,負載圖表會依等待事件進行分割。這表示圖表中每個長條的最大彩色區域代表對總資料庫負載貢獻最大的等待事件。圖表顯示問題開始的時間 (紅色)。將您的注意力集中在長條中佔用最多空間的等待事件上:
-
CPU -
IO:wait/io/sql/table/handler
此 Aurora MySQL 資料庫出現的上述等待事件超過正常值。若要了解如何使用 Amazon Aurora 中的等待事件調校效能,請參閱《Amazon Aurora 使用者指南》中的使用 Aurora MySQL 的等待事件調校和使用 Aurora PostgreSQL 的等待事件調校。若要了解如何使用 RDS for PostgreSQL 中的等待事件來調校效能,請參閱《Amazon RDS 使用者指南》中的使用 RDS for PostgreSQL 的等待事件進行調校。
相關指標
相關指標區段列出情境異常,這是因果異常中的特定問題清單。這些調查結果提供有關效能問題的其他資訊。
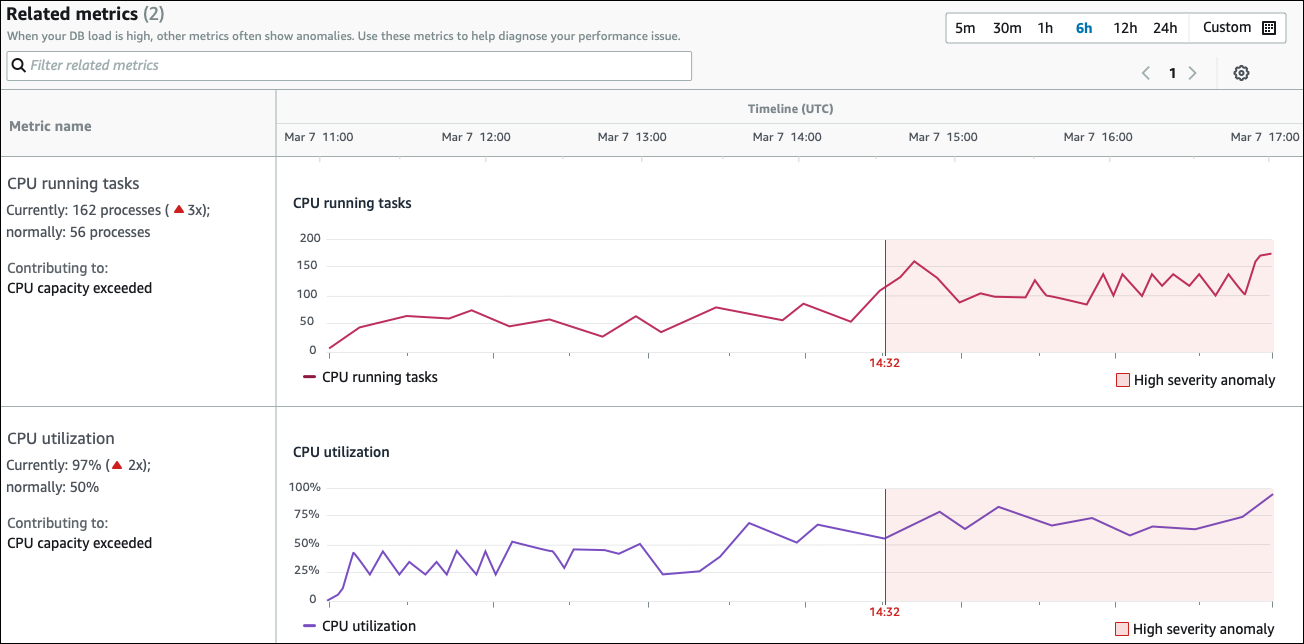
相關指標資料表有兩個資料欄:指標名稱和時間軸 (UTC)。資料表中的每一列都對應至特定指標。
每一列的第一欄包含下列資訊:
-
名稱– 指標的名稱。第一列會將指標識別為 CPU 執行中的任務。 -
目前 – 指標的目前值。在第一列中,目前值為 162 個處理程序 (3x)。
-
正常 – 此資料庫正常運作時,此指標的基準。DevOps Guru for RDS 會將基準計算為 1 週內的第 95 個百分位數值。第一列指出 56 個程序通常在 CPU 上執行。
-
貢獻至 - 與此指標相關聯的調查結果。在第一列中,CPU 執行中的任務指標與超過異常的 CPU 容量相關聯。
時間軸欄會顯示指標的折線圖。陰影區域會顯示 DevOps Guru for RDS 將調查結果指定為高嚴重性時的時間間隔。
分析和建議
雖然因果異常描述了整體問題,但情境異常描述了需要調查的特定調查結果。每個調查結果對應於一組相關指標。
在分析和建議區段的下列範例中,高資料庫負載異常有兩個問題清單。
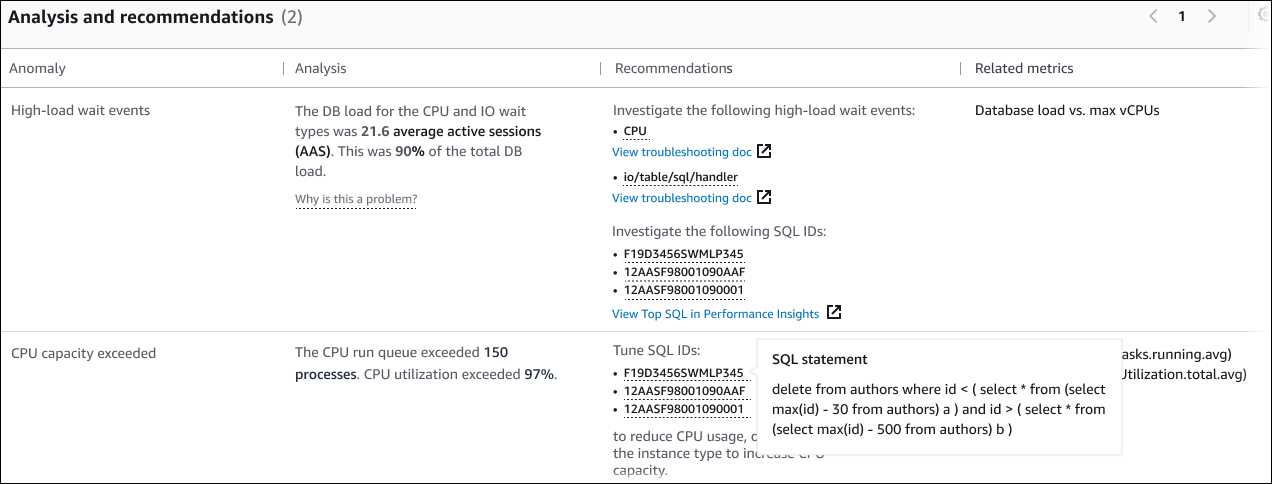
資料表包含以下資料行:
-
異常 – 此情境異常的一般描述。在此範例中,第一個異常是高負載等待事件,第二個是超過 CPU 容量。
-
分析 – 異常的詳細說明。
在第一個異常中,三種等待類型會導致 90% 的資料庫負載。在第二個異常中,CPU 執行佇列超過 150,這表示在任何指定時間,超過 150 個工作階段正在等待 CPU 時間。CPU 使用率超過 97%,這表示在問題發生期間,CPU 有 97% 的時間忙碌。因此,CPU 幾乎持續佔用,而平均有 150 個工作階段等待在 CPU 上執行。
-
建議 – 建議的使用者對異常的回應。
在第一個異常中,DevOps Guru for RDS 建議您調查等待事件
cpu和io/table/sql/handler。若要了解如何根據這些事件調整資料庫效能,請參閱《Amazon Aurora 使用者指南》中的 cpu 和 io/table/sql/handler。在第二個異常中,DevOps Guru for RDS 建議您透過調校三個 SQL 陳述式來減少 CPU 使用量。您可以將滑鼠游標暫留在連結上以查看 SQL 文字。
-
相關指標 – 為您提供異常特定測量的指標。如需這些指標的詳細資訊,請參閱《Amazon Aurora 使用者指南》中的 Amazon Aurora 指標參考或《Amazon RDS 使用者指南》中的 Amazon RDS 指標參考。
在第一個異常中,DevOps Guru for RDS 建議將資料庫負載與執行個體的最大 CPU 進行比較。在第二個異常中,建議查看 CPU 執行佇列、CPU 使用率和 SQL 執行率。
