本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
註釋 PDF 檔案
在 SageMaker AI Ground Truth 中註釋訓練 PDFs 之前,請先完成下列先決條件:
-
安裝 python3.8.x
-
安裝 jq
-
安裝 AWS CLI
如果您使用的是 us-east-1 區域,則可以略過安裝 AWS CLI,因為它已與您的 Python 環境一起安裝。在此情況下,您會建立虛擬環境以在 Cloud9 中使用 AWS Python 3.8。
-
設定您的AWS 登入資料
-
建立私有 SageMaker AI Ground Truth 人力資源以支援註釋
請務必在安裝期間使用新的私有人力資源時,記錄您選擇的工作團隊名稱。
設定您的環境
-
如果使用 Windows,請安裝 Cygwin
;如果使用 Linux 或 Mac,請略過此步驟。 -
從 GitHub 下載註釋成品
。解壓縮檔案。 -
從終端機視窗中,導覽至解壓縮資料夾 (amazon-comprehend-semi-structured-documents-annotation-tools-main)。
-
此資料夾包含您執行
Makefiles以安裝相依性、設定 Python virtualenv 和部署所需資源的 選項。檢閱讀我檔案以做出您的選擇。 -
建議選項使用單一命令將所有相依性安裝到 Virtualenv 中,從範本建置 CloudFormation 堆疊,並使用 AWS 帳戶 互動式指導將堆疊部署到 。執行以下命令:
make ready-and-deploy-guided此命令提供一組組態選項。請確定您的 AWS 區域 正確無誤。對於所有其他欄位,您可以接受預設值或填入自訂值。如果您修改 CloudFormation 堆疊名稱,請在後續步驟中視需要將其寫下來。
CloudFormation 堆疊會建立和管理註釋工具所需的 AWS lambda
、AWS IAM 角色和 AWS S3 儲存貯體。 您可以在 CloudFormation 主控台的堆疊詳細資訊頁面中檢閱這些資源。
-
命令會提示您開始部署。CloudFormation 會在指定的區域中建立所有資源。
當 CloudFormation 堆疊狀態轉換為 create-complete 時,資源即可使用。
將 PDF 上傳至 S3 儲存貯體
在設定區段中,您部署了 CloudFormation 堆疊,該堆疊會建立名為 comprehend-semi-structured-documents-${AWS::Region}-${AWS::AccountId} 的 S3 儲存貯體。您現在將來源 PDF 文件上傳至此儲存貯體。
注意
此儲存貯體包含標記任務所需的資料。Lambda 執行角色政策會授予 Lambda 函數存取此儲存貯體的許可。
您可以使用 S3Bucket' 金鑰,在 CloudFormation 堆疊詳細資訊中找到 S3 儲存貯體名稱。SemiStructuredDocumentsS3Bucket
-
在 S3 儲存貯體中建立新的資料夾。將此新資料夾命名為 'src'。
-
將 PDF 來源檔案新增至您的 'src' 資料夾。在後續步驟中,您會註釋這些檔案以訓練您的辨識器。
-
(選用) 以下 CLI AWS 範例可用來將來源文件從本機目錄上傳至 S3 儲存貯體:
aws s3 cp --recursivelocal-path-to-your-source-docss3://deploy-guided/src/或者,使用您的區域和帳戶 ID:
aws s3 cp --recursivelocal-path-to-your-source-docss3://deploy-guided-Region-AccountID/src/ 您現在擁有私有 SageMaker AI Ground Truth 人力資源,並將來源檔案上傳至 S3 儲存貯體 deploy-guided/src/;您已準備好開始註釋。
建立註釋任務
bin 目錄中的 comprehend-ssie-annotation-tool-cli.py 指令碼是一種簡單的包裝函式命令,可簡化 SageMaker AI Ground Truth 標籤工作的建立。python 指令碼會從 S3 儲存貯體讀取來源文件,並建立對應的單一頁面資訊清單檔案,每行一個來源文件。然後指令碼會建立標記任務,需要資訊清單檔案做為輸入。
python 指令碼使用您在設定區段中設定的 S3 儲存貯體和 CloudFormation 堆疊。指令碼所需的輸入參數包括:
-
input-s3-path:S3 Uri 到您上傳到 S3 儲存貯體的來源文件。例如:
s3://deploy-guided/src/。您也可以將您的區域和帳戶 ID 新增至此路徑。例如:s3://deploy-guided-Region-AccountID/src/。 -
cfn-name:CloudFormation 堆疊名稱。如果您使用堆疊名稱的預設值,您的 cfn-name 是 sam-app。
-
work-team-name:您在 SageMaker AI Ground Truth 中建置私有人力資源時建立的人力資源名稱。
-
job-name-prefix:SageMaker AI Ground Truth 標籤工作的字首。請注意,此欄位有 29 個字元的限制。時間戳記會附加至此值。例如:
my-job-name-20210902T232116。 -
entity-types:您希望在標記任務期間使用的實體,以逗號分隔。此清單必須包含您要在訓練資料集中註釋的所有實體。Ground Truth 標記任務只會顯示這些實體,以供註釋器在 PDF 文件中標記內容。
若要檢視指令碼支援的其他引數,請使用 -h選項來顯示說明內容。
使用輸入參數執行下列指令碼,如上一份清單所述。
python bin/comprehend-ssie-annotation-tool-cli.py \ --input-s3-path s3://deploy-guided-Region-AccountID/src/ \ --cfn-namesam-app\ --work-team-namemy-work-team-name\ --regionus-east-1\ --job-name-prefixmy-job-name-20210902T232116\ --entity-types "EntityA,EntityB,EntityC" \ --annotator-metadata "key=info,value=sample,key=Due Date,value=12/12/2021"指令碼會產生下列輸出:
Downloaded files to temp local directory /tmp/a1dc0c47-0f8c-42eb-9033-74a988ccc5aa Deleted downloaded temp files from /tmp/a1dc0c47-0f8c-42eb-9033-74a988ccc5aa Uploaded input manifest file to s3://comprehend-semi-structured-documents-us-west-2-123456789012/input-manifest/my-job-name-20220203-labeling-job-20220203T183118.manifest Uploaded schema file to s3://comprehend-semi-structured-documents-us-west-2-123456789012/comprehend-semi-structured-docs-ui-template/my-job-name-20220203-labeling-job-20220203T183118/ui-template/schema.json Uploaded template UI to s3://comprehend-semi-structured-documents-us-west-2-123456789012/comprehend-semi-structured-docs-ui-template/my-job-name-20220203-labeling-job-20220203T183118/ui-template/template-2021-04-15.liquid Sagemaker GroundTruth Labeling Job submitted: arn:aws:sagemaker:us-west-2:123456789012:labeling-job/my-job-name-20220203-labeling-job-20220203t183118 (amazon-comprehend-semi-structured-documents-annotation-tools-main) user@3c063014d632 amazon-comprehend-semi-structured-documents-annotation-tools-main %
使用 SageMaker AI Ground Truth 註釋
現在您已設定所需的資源並建立標籤工作,您可以登入標籤入口網站並註釋 PDFs。
-
使用 Chrome 或 Firefox Web 瀏覽器登入 SageMaker AI 主控台
。 -
選取標記人力資源,然後選擇私有。
-
在私有人力資源摘要下,選取您使用私有人力資源建立的標記入口網站登入 URL。使用適當的登入資料登入。
如果您沒有看到任何列出的任務,請不要擔心,更新可能需要一些時間,具體取決於您上傳用於註釋的檔案數量。
-
選取您的任務,然後在右上角選擇開始工作以開啟註釋畫面。
您會在註釋畫面中看到其中一個文件開啟,並在上面看到您在設定期間提供的實體類型。在實體類型右側有一個箭頭,您可以用來導覽文件。
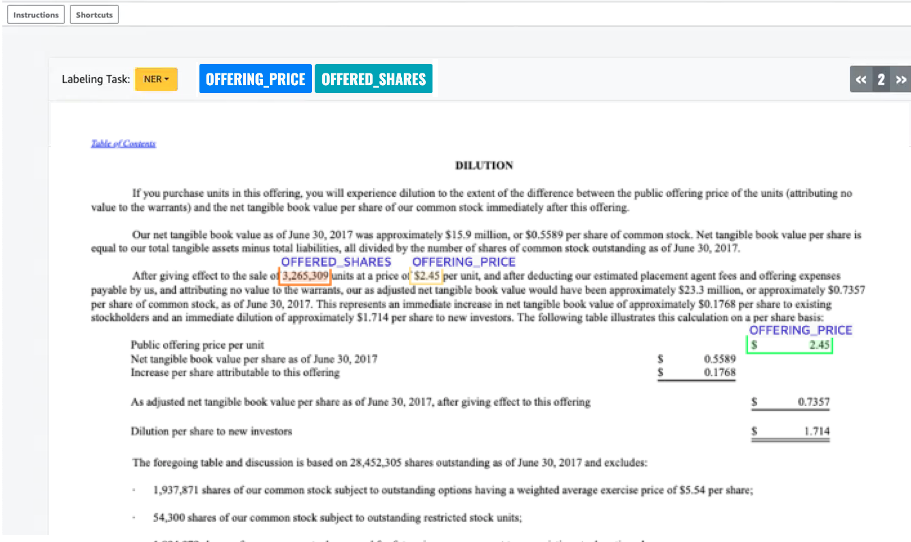
註釋開啟的文件。您也可以在每個文件上移除、復原或自動標記註釋;這些選項可在註釋工具的右側面板中使用。
若要使用自動標籤,請為其中一個實體的執行個體加上註釋;然後,該特定字詞的所有其他執行個體都會自動以該實體類型加上註釋。
完成後,請選取右下角的提交,然後使用導覽箭頭移至下一個文件。重複此操作,直到您已註釋所有 PDFs 為止。
註釋所有訓練文件後,您可以在此位置的 Amazon S3 儲存貯體中找到 JSON 格式的註釋:
/output/your labeling job name/annotations/
輸出資料夾也包含輸出資訊清單檔案,其中列出訓練文件中的所有註釋。您可以在下列位置找到輸出資訊清單檔案。
/output/your labeling job name/manifests/
