本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon MQ for RabbitMQ 中效能最佳化和效率的最佳實務
您可以將 Amazon MQ for RabbitMQ 代理程式效能最佳化,方法是將輸送量最大化、將延遲降至最低,並確保有效率的資源使用率。完成下列最佳實務以最佳化您的應用程式效能。
步驟 1:將訊息大小保持在 1 MB 以下
我們建議將訊息保持在 1 MB (MB) 以下,以獲得最佳效能和可靠性。
RabbitMQ 3.13 預設支援高達 128 MB 的訊息大小,但大型訊息可能會觸發無法預測的記憶體警示,封鎖發佈並可能建立高記憶體壓力,同時跨節點複寫訊息。過大的訊息也可能會影響代理程式重新啟動和復原程序,這會提高服務持續性的風險,並可能導致效能降低。
使用宣告檢查模式存放和擷取大型承載
若要管理大型訊息,您可以將訊息承載存放在外部儲存體中,並僅透過 RabbitMQ 傳送承載參考識別符,以實作宣告檢查模式。消費者使用承載參考識別符來擷取和處理大型訊息。
下圖示範如何使用 Amazon MQ for RabbitMQ 和 Amazon S3 實作宣告檢查模式。
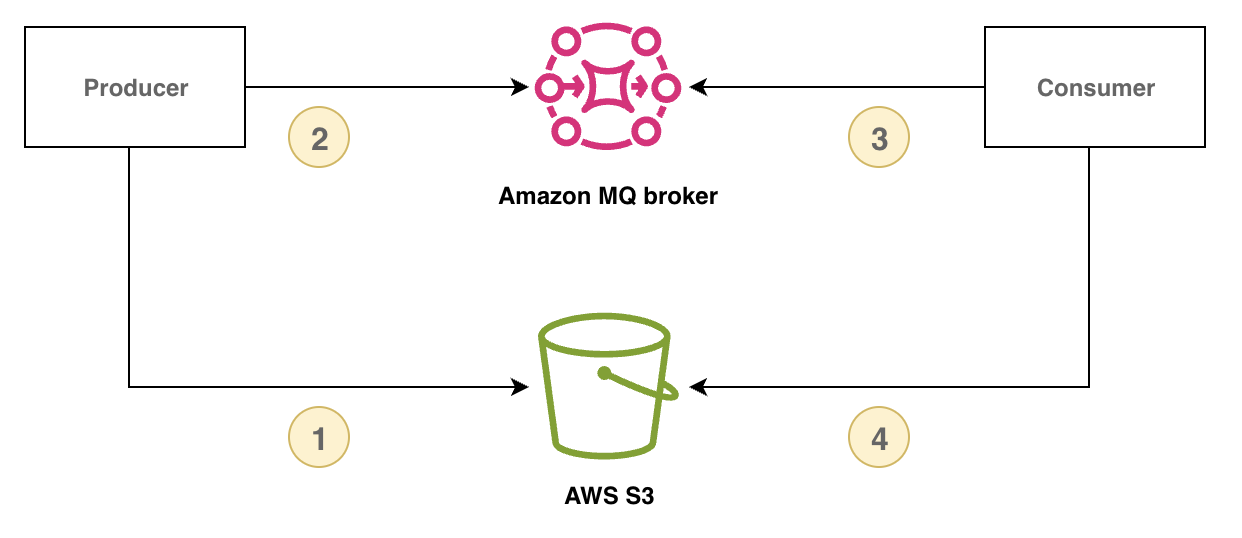
下列範例示範此模式使用 Amazon MQ、AWS 適用於 Java 的 SDK 2.x 和 Amazon S3:
-
首先,定義將保留 Amazon S3 參考識別符的訊息類別。
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
建立發佈者方法,將承載存放在 Amazon S3 中,並透過 RabbitMQ 傳送參考訊息。
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
實作取用者方法,從 Amazon S3 擷取承載、處理承載,以及刪除 Amazon S3 物件。
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
步驟 2:使用 basic.consume和長期消費者
basic.consume 搭配長期消費者使用 比使用 輪詢個別訊息更有效率basic.get。如需詳細資訊,請參閱輪詢個別訊息
步驟 3:設定預先擷取
您可以使用 RabbitMQ 預先擷取值來最佳化消費者取用訊息的方式。RabbitMQ 可將預先擷取計數應用到取消費者而不是通道,以實作 AMQP 0-9-1 提供的通道預先擷取機制。預先擷取值用於指定在任何給定的時間傳送給消費者的訊息數量。根據預設,RabbitMQ 會為用戶端應用程式設定不受限的緩衝區大小。
為 RabbitMQ 消費者設定預先擷取計數時,需要考量各種因素。首先,請考量消費者的環境和組態。因為消費者需要在處理時讓所有訊息保留在記憶體中,因此高預先擷取值可能會對消費者的效能產生負面影響,在某些情況下,可能會導致消費者可能一起當機。同樣地,RabbitMQ 代理程式本身會讓其傳送的所有訊息保持在記憶體中快取,直到其收到消費者認可為止。如果沒有為消費者設定自動認可,且消費者花相對長的時間來處理訊息,則高預先擷取值可能會導致 RabbitMQ 伺服器快速耗盡記憶體。
考慮到上述考量,我們建議一律設定預先擷取值,以防止 RabbitMQ 代理程式或其消費者因大量未處理或未認可的訊息而耗盡記憶體的情況。如果您需要將代理程式最佳化以處理大量訊息,您可使用一系列預先擷取計數來測試代理程式和消費者,以判斷相較於消費者處理訊息所需的時間,網路負荷在哪個時候變得非常微不足道的值。
注意
如果用戶端應用程式已設定為自動認可訊息傳遞給消費者,則設定預先擷取值沒有作用。
所有預先擷取的訊息會從佇列中移除。
以下範例示範如何使用 RabbitMQ Java 用戶端程式庫,為單一消費者設定 10 的預先擷取值。
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
注意
在 RabbitMQ Java 用戶端程式庫中,global 旗標的預設值會設為 false,所以上述範例可以簡單地撰寫為 channel.basicQos(10)。
步驟 4:搭配規定人數佇列使用 Celery 5.5 或更新版本
Python Celery
對於所有 Celery 版本
-
關閉
task_create_missing_queues以減輕佇列流失。 -
然後,關閉
worker_enable_remote_control以停止動態建立celery@...pidbox佇列。這將減少代理程式上的佇列流失。worker_enable_remote_control = false -
若要進一步減少非關鍵訊息活動,請在啟動 Celery 應用程式時,透過不包含
-E或--task-events旗標來關閉 Celery worker-send-task-events。 -
使用下列參數啟動您的 Celery 應用程式:
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
對於 Celery 5.5 版及更新版本
-
升級至 Celery 5.5 版
、支援規定人數佇列的最低版本,或更新版本。若要檢查您正在使用的 Celery 版本,請使用 celery --version。如需規定人數佇列的詳細資訊,請參閱 Amazon MQ 上 RabbitMQ 的配額佇列 Amazon MQ。 -
升級至 Celery 5.5 或更新版本後,
task_default_queue_type將 設定為「規定人數」。 -
然後,您還必須在中介裝置傳輸選項
中開啟發佈確認: broker_transport_options = {"confirm_publish": True}
