本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
Amazon RDS 零 ETL 整合的資料篩選
Amazon RDS 零 ETL 整合支援資料篩選,可讓您控制要將哪些資料從來源 Amazon RDS 資料庫複寫到目標資料倉儲。您可以套用一或多個篩選條件來選擇性地包含或排除特定資料表,而不是複寫整個資料庫。這可協助您透過確保僅傳輸相關資料來最佳化儲存和查詢效能。目前,篩選僅限於資料庫和資料表層級。不支援資料欄層級和資料列層級篩選。
當您想要執行下列操作時,資料篩選很有用:
-
從兩個或多個不同的來源資料庫聯結特定資料表,且您不需要任何一個資料庫的完整資料。
-
僅使用資料表子集而非整個資料庫機群執行分析,以節省成本。
-
從特定資料表篩選掉敏感資訊,例如電話號碼、地址或信用卡詳細資訊。
您可以使用 AWS 管理主控台、 AWS Command Line Interface (AWS CLI) 或 Amazon RDS API,將資料篩選條件新增至零 ETL 整合。
如果整合具有佈建叢集做為其目標,則叢集必須在修補程式 180 或更高版本,才能使用資料篩選。
主題
資料篩選的格式
您可以為單一整合定義多個篩選條件。每個篩選條件都會包含或排除符合篩選條件運算式中其中一個模式的任何現有和未來資料庫資料表。Amazon RDS 零 ETL 整合使用 Maxwell 篩選條件語法
每個篩選條件都有下列元素:
| Element | Description |
|---|---|
| 篩選條件類型 |
|
| 篩選條件表達式 |
模式的逗號分隔清單。運算式必須使用 Maxwell 篩選條件語法 |
| 模式 |
RDS for MySQL 的 注意對於 RDS for MySQL,資料庫和資料表名稱都支援規則運算式。對於 RDS for PostgreSQL,僅結構描述和資料表名稱支援規則運算式,資料庫名稱不支援。 您無法包含資料欄層級篩選條件或拒絕清單。 單一整合最多可有 99 個模式。在主控台中,您可以在單一篩選條件運算式內輸入模式,或將其分散在多個運算式中。單一模式的長度不可超過 256 個字元。 |
重要
如果您選取 RDS for PostgreSQL 來源資料庫,則必須至少指定一個資料篩選條件模式。模式至少必須包含單一資料庫 (database-name.*.*
下圖顯示主控台中 RDS for MySQL 資料篩選條件的結構:

重要
請勿在您的篩選條件模式中包含個人身分識別、機密或敏感資訊。
中的資料篩選條件 AWS CLI
使用 AWS CLI 新增資料篩選條件時,語法與主控台略有不同。您必須個別為每個模式指派篩選條件類型 (Include 或 Exclude),因此您無法在一個篩選條件類型下群組多個模式。
例如,在主控台中,您可以在單一 Include 陳述式下群組下列逗號分隔模式:
RDS for MySQL
mydb.mytable,mydb./table_\d+/
RDS for PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
不過,使用 時 AWS CLI,相同的資料篩選條件必須採用下列格式:
RDS for MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS for PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
篩選條件邏輯
如果您未在整合中指定任何資料篩選條件,Amazon RDS 會假設 include:*.* 的預設篩選條件,這會將所有資料表複寫到目標資料倉儲。不過,如果您新增至少一個篩選條件,預設邏輯會切換為 exclude:*.*,預設會排除所有資料表。這可讓您明確定義複寫中要包含哪些資料庫和資料表。
例如,如果您定義下列篩選條件:
'include: db.table1, include: db.table2'
Amazon RDS 會評估篩選條件,如下所示:
'exclude:*.*, include: db.table1, include: db.table2'
因此,Amazon RDS 只會從名為 db 的資料庫將 table1 和 table2 複寫到目標資料倉儲。
篩選條件優先順序
Amazon RDS 會依您指定的順序評估資料篩選條件。在 中 AWS 管理主控台,它會處理從左到右以及從上到下的篩選條件表達式。第二個篩選條件或第一個篩選條件後面的個別模式可以覆寫它。
例如,如果第一個篩選條件是 Include books.stephenking,它只會包含 books 資料庫中的 stephenking 資料表。不過,如果您新增第二個篩選條件 Exclude books.*,則會覆寫第一個篩選條件。這可防止 books 索引中的任何資料表複寫到目標資料倉儲。
當您指定至少一個篩選條件時,邏輯會從預設假設 exclude:*.* 開始,這會自動排除所有資料表進行複寫。最佳實務是定義從最廣泛到最具體的篩選條件。從一或多個 Include 陳述式開始,指定要複寫的資料,然後新增 Exclude 篩選條件以選擇性地移除特定資料表。
相同的原則適用於您使用 AWS CLI定義的篩選條件。Amazon RDS 會依您指定的順序評估這些篩選條件模式,因此模式可能會覆寫您在之前指定的模式。
RDS for MySQL 範例
下列範例示範資料篩選如何適用於 RDS for MySQL 範例零 ETL 整合:
-
包含所有資料庫和所有資料表:
'include: *.*' -
包含
books資料庫中的所有資料表:'include: books.*' -
排除任何名為
mystery的資料表:'include: *.*, exclude: *.mystery' -
包含
books資料庫中的兩個特定資料表:'include: books.stephen_king, include: books.carolyn_keene' -
包含
books資料庫中的所有資料表,但包含子字串mystery的資料表除外:'include: books.*, exclude: books./.*mystery.*/' -
包含
books資料庫中的所有資料表,但以mystery開頭的資料表除外:'include: books.*, exclude: books./mystery.*/' -
包含
books資料庫中的所有資料表,但以mystery結尾的資料表除外:'include: books.*, exclude: books./.*mystery/' -
包含
books資料庫中以table_開頭的所有資料表,但名為table_stephen_king的資料表除外。例如,會複寫table_movies或table_books,但不會複寫table_stephen_king。'include: books./table_.*/, exclude: books.table_stephen_king'
RDS for PostgreSQL 範例
下列範例示範資料篩選如何適用於 RDS for PostgreSQL 零 ETL 整合:
-
包含
books資料庫中的所有資料表:'include: books.*.*' -
排除
books資料庫中名為mystery的任何資料表:'include: books.*.*, exclude: books.*.mystery' -
包含
books資料庫的mystery結構描述中的一個資料表,以及employee資料庫的finance結構描述的一個資料表:'include: books.mystery.stephen_king, include: employee.finance.benefits' -
包含
books資料庫的science_fiction結構描述中的所有資料表,但包含子字串king的資料表除外:'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
包含
books資料庫中的所有資料表,但具有以sci開頭的結構描述名稱的資料表除外:'include: books.*.*, exclude: books./sci.*/.*' -
包含
books資料庫中的所有資料表,但以king結尾的mystery結構描述中的資料表除外:'include: books.*.*, exclude: books.mystery./.*king/' -
包含
books資料庫中以table_開頭的所有資料表,但名為table_stephen_king的資料表除外。例如,會複寫fiction結構描述中的table_movies和mystery結構描述中的table_books,但不會複寫任一結構描述中的table_stephen_king:'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
RDS for Oracle 範例
下列範例示範資料篩選如何適用於 RDS for Oracle 零 ETL 整合:
-
包含 books 資料庫中的所有資料表:
'include: books.*.*' -
排除 books 資料庫中名為 mystery 的任何資料表:
'include: books.*.*, exclude: books.*.mystery' -
包含 books 資料庫的 mystery 結構描述中的一個資料表,以及 employee 資料庫的 finance 結構描述中的一個資料表:
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
包含 books 資料庫的 mystery 結構描述中的所有資料表:
'include: books.mystery.*'
區分大小寫考量
Oracle Database 和 Amazon Redshift 以不同的方式處理物件名稱大小寫,這會影響資料篩選條件組態和目標查詢。注意下列事項:
-
除非在
CREATE陳述式中明確加上引號,否則 Oracle Database 會以大寫形式儲存資料庫、結構描述和物件名稱。例如,如果您建立mytable(無引號),Oracle 資料字典會將資料表名稱儲存為MYTABLE。如果您將物件名稱加上引號,資料字典會保留大小寫。 -
零 ETL 資料篩選條件區分大小寫,且必須符合物件名稱在 Oracle 資料字典中顯示的確切大小寫。
-
除非明確加上引號,否則 Amazon Redshift 查詢預設為小寫物件名稱。例如,查詢
MYTABLE(無引號) 會搜尋mytable。
當您建立 Amazon Redshift 篩選條件並查詢資料時,請注意大小寫差異。
建立大寫整合
當您在不以雙引號指定名稱的情況下建立資料表時,Oracle 資料庫會將名稱以大寫形式儲存在資料字典中。例如,您可以使用下列任何 SQL 陳述式來建立 MYTABLE。
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
由於您未在上述陳述式中為資料表名稱加上引號,Oracle 資料庫會將物件名稱以大寫形式儲存為 MYTABLE。
若要將此資料表複寫至 Amazon Redshift,您必須在 create-integration 命令的資料篩選條件中指定大寫名稱。零 ETL 篩選條件名稱和 Oracle 資料字典名稱必須相符。
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
根據預設,Amazon Redshift 會以小寫儲存資料。若要在 Amazon Redshift 的複寫資料庫中查詢 MYTABLE,您必須將大寫名稱 MYTABLE 加上引號,使其符合 Oracle 資料字典中的大小寫。
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
下列查詢不使用引號機制。它們都會傳回錯誤,因為它們搜尋名為 mytable 的 Amazon Redshift 資料表,其使用預設小寫名稱,但資料表在 Oracle 資料字典中命名為 MYTABLE。
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
下列查詢使用引號機制來指定混合大小寫名稱。這些查詢都會傳回錯誤,因為它們會搜尋未命名為 MYTABLE 的 Amazon Redshift 資料表。
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
建立小寫整合
在下列替代範例中,您可以使用雙引號將資料表名稱以小寫形式儲存在 Oracle 資料字典中。您可以建立 mytable,如下所示。
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle 資料庫會將資料表名稱以小寫形式儲存為 mytable。若要將此資料表複寫到 Amazon Redshift,您必須在零 ETL 資料篩選條件中指定小寫名稱 mytable。
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
當您在 Amazon Redshift 的複寫資料庫中查詢此資料表時,您可以指定小寫名稱 mytable。查詢成功,因為它會搜尋名為 mytable 的資料表,這是 Oracle 資料字典中的資料表名稱。
SELECT * FROM targetdb1."REINVENT".mytable;
由於 Amazon Redshift 預設為小寫物件名稱,下列查詢也會成功找到 mytable。
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
下列查詢針對物件名稱使用引號機制。它們都會傳回錯誤,因為它們會搜尋名稱與 mytable 不同的 Amazon Redshift 資料表。
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
建立具有混合大小寫整合的資料表
在下列範例中,您可以使用雙引號將資料表名稱以小寫形式儲存在 Oracle 資料字典中。您可以建立 MyTable,如下所示。
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle 資料庫會將此資料表名稱以混合大小寫形式儲存為 MyTable。若要將此資料表複寫到 Amazon Redshift,您必須在資料篩選條件中指定混合大小寫名稱。
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
當您在 Amazon Redshift 的複寫資料庫中查詢此資料表時,您必須藉由將物件名稱加上引號,來指定混合大小寫名稱 MyTable。
SELECT * FROM targetdb1."REINVENT"."MyTable";
由於 Amazon Redshift 預設為小寫物件名稱,下列查詢找不到物件,因為它們會搜尋小寫名稱 mytable。
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
注意
您無法在 RDS for Oracle 整合的資料庫名稱、結構描述或資料表名稱的篩選條件值中使用規則運算式。
將資料篩選條件新增至整合
您可以使用 AWS 管理主控台、 AWS CLI或 Amazon RDS API 設定資料篩選。
重要
如果您在建立整合之後新增篩選條件,Amazon RDS 會將其視為一律存在。它會移除目標資料倉儲中不符合新篩選條件的任何資料,並重新同步所有受影響的資料表。
將資料篩選條件新增至零 ETL 整合
登入 AWS 管理主控台 ,並在 https://console.aws.amazon.com/rds/
:// 開啟 Amazon RDS 主控台。 -
在導覽窗格中,選擇零 ETL 整合。選取您要新增資料篩選條件的整合,然後選擇修改。
-
在來源下,新增一或多個
Include和Exclude陳述式。下圖顯示 MySQL 整合的資料篩選條件範例:
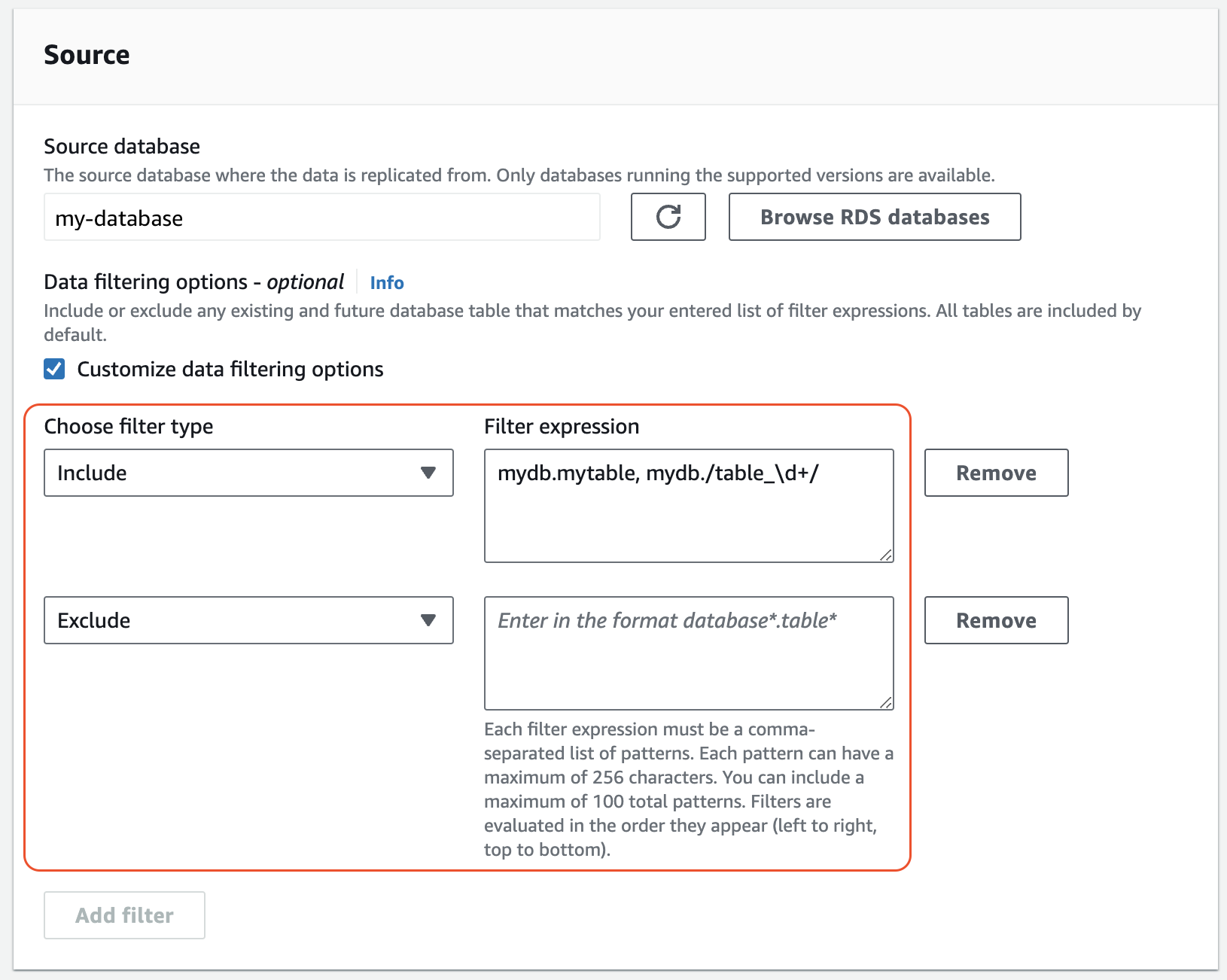
-
當您對變更感到滿意時,請選擇繼續和儲存變更。
若要使用 將資料篩選條件新增至零 ETL 整合 AWS CLI,請呼叫 modify-integrationInclude 和 Exclude Maxwell 篩選條件清單指定 --data-filter 參數。
範例
下列範例會將篩選條件模式新增至 my-integration。
針對 Linux、macOS 或 Unix:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
在 Windows 中:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
若要使用 RDS API 修改零 ETL 整合,請呼叫 ModifyIntegration 操作。指定整合識別符,並提供以逗號分隔的篩選條件模式清單。
從整合中移除資料篩選條件
當您從整合中移除資料篩選條件時,Amazon RDS 會重新評估剩餘的篩選條件,就好像移除的篩選條件從未存在一樣。然後,它會將目前符合條件的任何先前排除的資料複寫到目標資料倉儲。這會觸發所有受影響資料表的重新同步。
