要获得与亚马逊 Timestream 类似的功能 LiveAnalytics,可以考虑适用于 InfluxDB 的亚马逊 Timestream。适用于 InfluxDB 的 Amazon Timestream 提供简化的数据摄取和个位数毫秒级的查询响应时间,以实现实时分析。点击此处了解更多信息。
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用计划查询和原始数据进行深入分析
您可以使用整个实例集的汇总统计数据来确定需要深入研究的领域,然后使用原始数据分析精细数据,以获得更深入的见解。
在此示例中,您将了解如何使用聚合控制面板识别任何部署(部署指特定区域、单元格、筒仓和可用区内某个微服务的部署),这些部署的 CPU 利用率似乎高于其他部署。您可通过原始数据进行深入分析,从而获得更深入的理解。由于这些深入研究可能很少见,且只能访问与部署相关的数据,因此您可以使用原始数据进行分析,无需使用计划查询。
每次部署深入挖掘
下方控制面板提供对给定部署中更精细服务器级统计数据的深入分析。为帮助您深入分析实例集的不同部分,此控制面板使用区域、单元格、筒仓、微服务和可用区等变量。随后显示该部署的汇总统计数据。


在下面的查询中,您可以看到,在变量下拉列表中选择的值用作查询中 WHERE 子句的谓词,这使您能够仅关注部署的数据。该面板绘制该部署中实例的聚合 CPU 指标。您可以使用原始数据,就交互式查询延迟进行深入分析,以获得更深入的见解。
SELECT bin(time, 5m) as minute, ROUND(AVG(cpu_user), 2) AS avg_value, ROUND(APPROX_PERCENTILE(cpu_user, 0.9), 2) AS p90_value, ROUND(APPROX_PERCENTILE(cpu_user, 0.95), 2) AS p95_value, ROUND(APPROX_PERCENTILE(cpu_user, 0.99), 2) AS p99_value FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099476) AND from_milliseconds(1636613499476) AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND microservice_name = 'demeter' AND availability_zone = 'eu-west-1-3' AND measure_name = 'metrics' GROUP BY bin(time, 5m) ORDER BY 1
实例级统计信息
此仪表板进一步计算另一个变量,该变量还列出了 CPU 利用率较高的变量,按使用率降序排序。 servers/instances 用于计算此变量的查询如下所示。
WITH microservice_cell_avg AS ( SELECT AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE $__timeFilter AND measure_name = 'metrics' AND region = '${region}' AND cell = '${cell}' AND silo = '${silo}' AND availability_zone = '${availability_zone}' AND microservice_name = '${microservice}' ), instance_avg AS ( SELECT instance_name, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE $__timeFilter AND measure_name = 'metrics' AND region = '${region}' AND cell = '${cell}' AND silo = '${silo}' AND microservice_name = '${microservice}' AND availability_zone = '${availability_zone}' GROUP BY availability_zone, instance_name ) SELECT i.instance_name FROM instance_avg i CROSS JOIN microservice_cell_avg m WHERE i.instance_avg_metric > (1 + ${utilization_threshold}) * m.microservice_avg_metric ORDER BY i.instance_avg_metric DESC
在上述查询中,该变量会根据其他变量所选取值的动态变化而重新计算。在为部署填充变量后,您可以从列表中选择单个实例,以进一步可视化该实例的指标。您可以从实例名称的下拉列表中选择不同的实例,如下方快照所示。
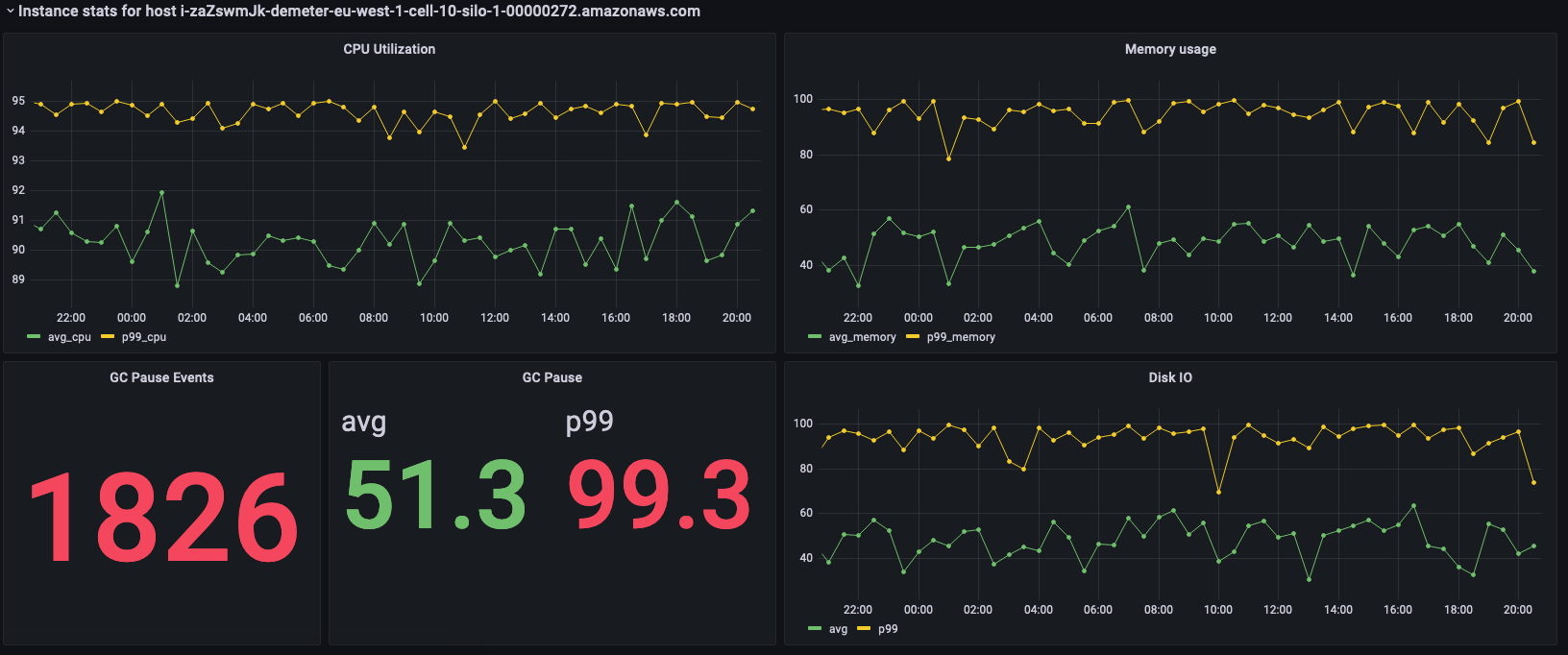
前面的面板显示所选实例的统计信息,而下方则是用于获取这些统计信息的查询。
SELECT BIN(time, 30m) AS time_bin, AVG(cpu_user) AS avg_cpu, ROUND(APPROX_PERCENTILE(cpu_user, 0.99), 2) as p99_cpu FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099477) AND from_milliseconds(1636613499477) AND measure_name = 'metrics' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com' GROUP BY BIN(time, 30m) ORDER BY time_bin desc
SELECT BIN(time, 30m) AS time_bin, AVG(memory_used) AS avg_memory, ROUND(APPROX_PERCENTILE(memory_used, 0.99), 2) as p99_memory FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099477) AND from_milliseconds(1636613499477) AND measure_name = 'metrics' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com' GROUP BY BIN(time, 30m) ORDER BY time_bin desc
SELECT COUNT(gc_pause) FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099477) AND from_milliseconds(1636613499478) AND measure_name = 'events' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com'
SELECT avg(gc_pause) as avg, round(approx_percentile(gc_pause, 0.99), 2) as p99 FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099478) AND from_milliseconds(1636613499478) AND measure_name = 'events' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com'
SELECT BIN(time, 30m) AS time_bin, AVG(disk_io_reads) AS avg, ROUND(APPROX_PERCENTILE(disk_io_reads, 0.99), 2) as p99 FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636527099478) AND from_milliseconds(1636613499478) AND measure_name = 'metrics' AND region = 'eu-west-1' AND cell = 'eu-west-1-cell-10' AND silo = 'eu-west-1-cell-10-silo-1' AND availability_zone = 'eu-west-1-3' AND microservice_name = 'demeter' AND instance_name = 'i-zaZswmJk-demeter-eu-west-1-cell-10-silo-1-00000272.amazonaws.com' GROUP BY BIN(time, 30m) ORDER BY time_bin desc
