本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将 SAP BDC 中的数据与AWS数据源集成
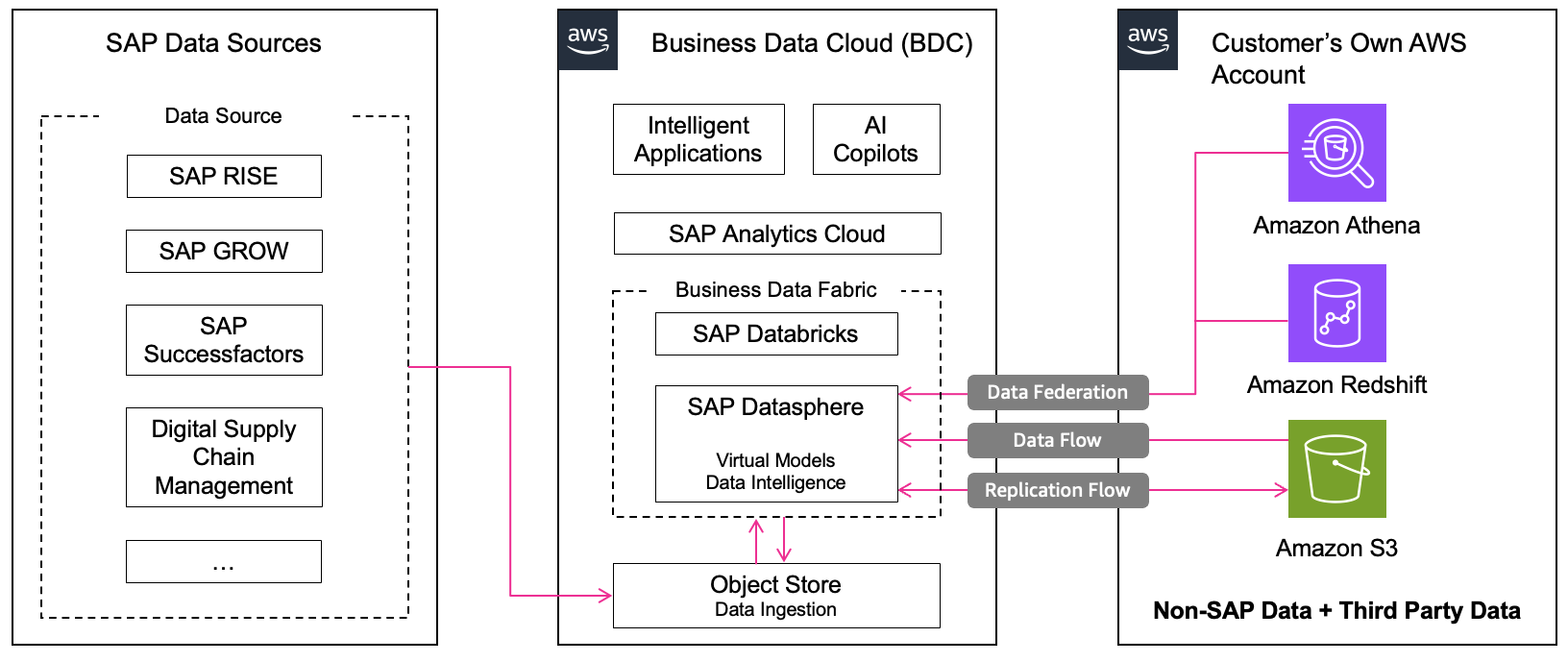
通过带有 SAP BDC 的 SAP Datasphere 数据结构架构,可以将来自AWS数据源的非 SAP 数据与 SAP 数据进行协调。集成架构支持多种AWS服务,每种服务都有基于实时数据或复制的特定集成模式:
A. 与 Amazon Athena 的集成
集成模式:将数据实时联合至 SAP Datasphere
Amazon Athena 是 Amazon 推出的交互式查询服务,可帮助查询和分析 S3 中的数据。来自 Athena 的非 SAP 数据能够实时联合至 SAP Datasphere 的远程表中,并与 SAP 数据相结合,以便在 SAP Analytics Cloud
以下是将 Athena 与 SAP Datasphere 集成的步骤:
-
准备包含非 SAP 数据和第三方数据的来源
-
配置 Athena
-
配置必要的 IAM 用户和授权
-
设置 SAP Datasphere 与 Athena 的连接
-
在 SAP Datasphere 中构建模型
通过此流程,可以进行实时数据联合而无需复制数据,从而降低成本、快速提供见解,并实现企业级安全。有关详细的分步说明,请访问 Federating Queries from SAP Datasphere to Amazon S3 via Amazon Athena
B. 与 Amazon Redshift 的集成
集成模式:将数据实时联合至 SAP Datasphere
Amazon Redshift 是一项完全托管的 PB 级数据仓库服务,已针对分析工作负载进行优化。通过 SAP Datasphere 的数据联合架构,可将 Redshift 数据与 SAP 数据相结合,以在 SAP Analytics Cloud 中构建统一的数据模型和分析。智能数据集成(SDI)
以下是将 Redshift 与 SAP Datasphere 集成的步骤:
-
在 SAP Datasphere 中创建本地代理
-
设置 Redshift 访问权限
-
配置 SAP SDI DP 代理
-
在 SAP Datasphere 中注册 Camel JDBC 适配器
-
在 SAP Datasphere 中上传第三方驱动程序
-
在 SAP Datasphere 中创建与 Redshift 的本地连接
-
从 Redshift 导入远程表
此设置支持从 SAP Datasphere 向 Redshift 发起实时联合查询,而无需复制数据。优势包括实时访问 Redshift 数据、通过下推查询优化性能,以及避免 SAP Datasphere 中出现数据重复情况。有关详细的分步说明,请访问 Data Federation between SAP Datasphere and Amazon Redshift
C. 与 Amazon S3 的集成
集成模式:使用复制流复制数据,使用数据流将数据导入 SAP Datasphere
Amazon S3 提供高度可扩展、持久、可用和安全的对象存储服务。S3 存储桶中的非 SAP 数据可通过数据流功能导入 SAP Datasphere,供 SAP Analytics Cloud 中的财务规划或业务分析等应用程序使用。
以下是将 Amazon S3 与 SAP Datasphere 集成的步骤:
-
在 S3 存储桶中准备源数据
-
配置必要的 IAM 用户和授权
-
在 SAP Datasphere 中创建 S3 连接
-
创建数据流
通过此流程,SAP Datasphere 可连接到 S3、访问非 SAP 数据,并借助数据流将这些数据与内部 SAP 数据集结合使用。有关详细的分步说明,请访问 Data integration between SAP Datasphere and in Amazon S3
您可以在 “与AWS数据源集成
