本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数据仓库架构
数据仓库
业务分析师、数据工程师、数据科学家和决策者可通过商业智能(BI)工具、SQL 客户端及其他分析应用程序访问数据仓库。架构包含多个层:用于呈现结果的前端客户端、用于数据访问与分析的分析引擎,以及用于数据加载与存储的数据库服务器。
数据以表和列的形式存储在数据库中,并按模式进行组织。数据仓库整合来自多个来源的数据,支持历史数据分析,并确保数据质量、一致性和准确性。将分析处理与事务数据库分开可以增强两个系统的性能,通过高效存储数据来支持报告、仪表板和分析工具,从而最大限度地减少 I/O 查询结果并将其快速提供给大量并发用户。
主要特征
-
整合:将来自不同来源(例如,CRM、ERP)的数据整合到统一的模式中,解决格式或命名规范不一致的问题。
-
Time-variant:跟踪历史数据,允许对数月或数年的趋势进行分析。
-
Subject-oriented: 围绕销售或库存等业务领域而不是运营流程进行组织。
-
Non-volatile:数据存储后保持静态;更新是通过预定的提取、转换、加载 (ETL) 过程进行的,而不是通过实时更改进行的。
-
Price-optimized:SAP 和非 SAP 数据存储在成本优化的架构中。
架构组件
-
ETL 工具:自动完成从来源提取数据、转换(清洗与标准化)数据并将数据加载至仓库这一流程。
-
存储层:
-
结构化数据的关系数据库
-
用于多维分析的 OLAP(联系分析处理)立方体
-
-
元数据:描述数据来源、转换和关系。
-
访问工具:SQL 客户端、BI 平台和机器学习接口。
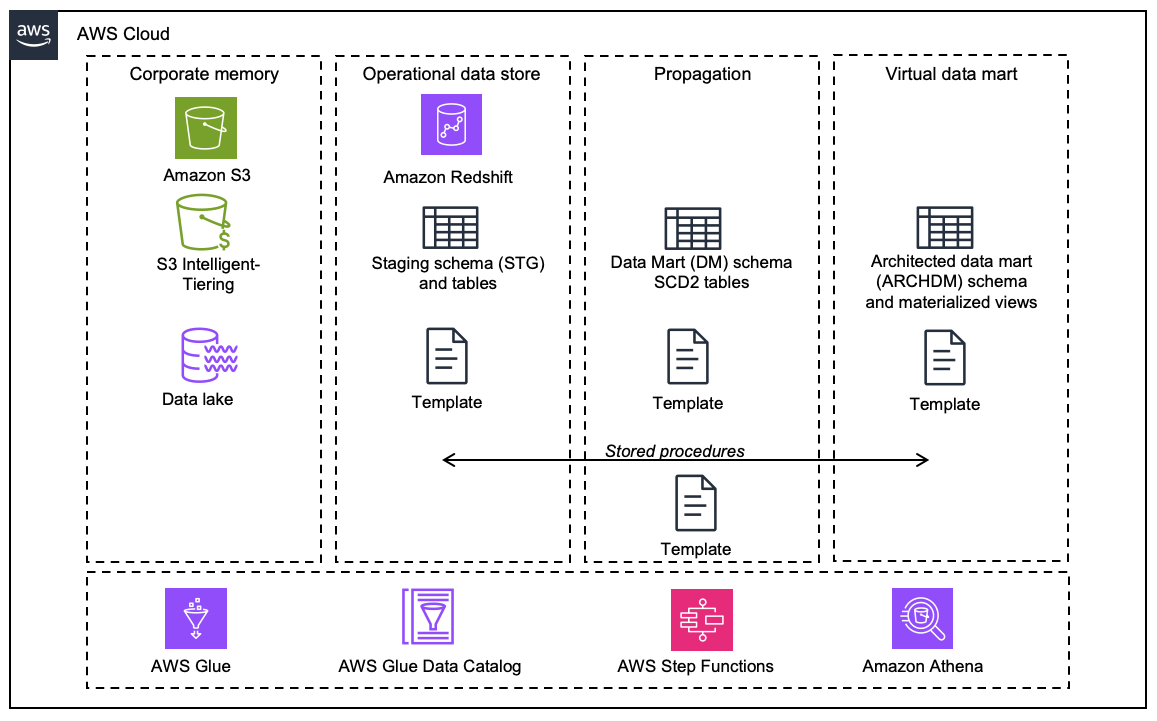
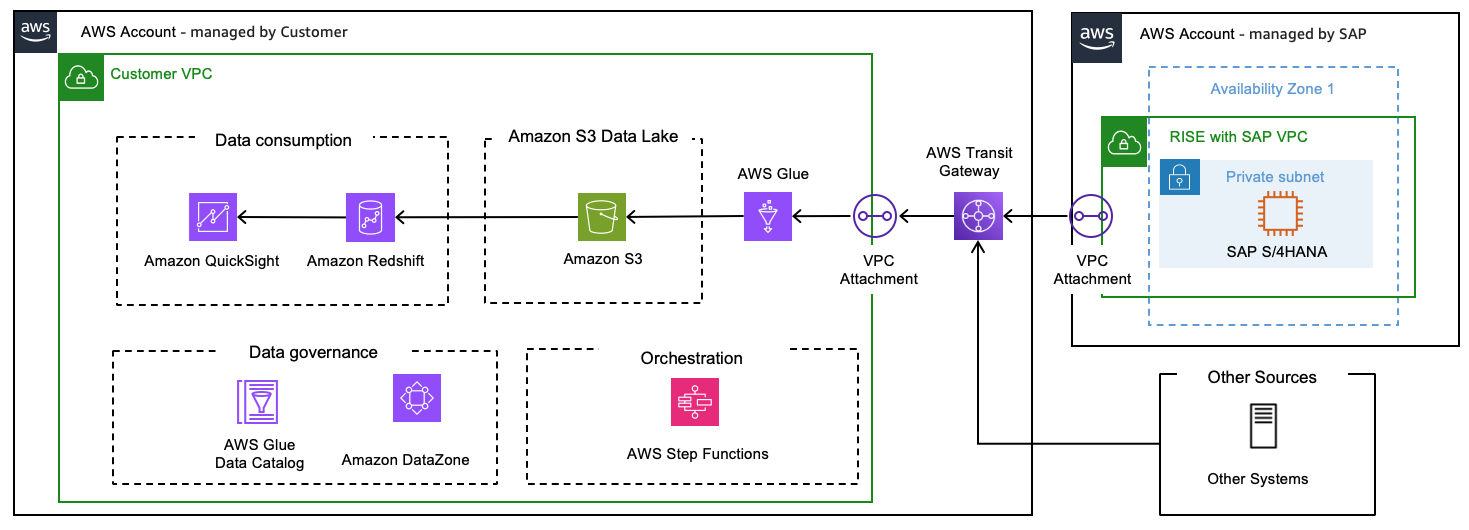
数据仓库利用分层架构对不同粒度的数据进行组织,这有助于确保数据的一致性和灵活性。最常见的数据仓库架构层包括源层、暂存层、仓库层和使用层。SAP 系统的数据仓库同样采用基于层的架构。在构建 SAP 云数据仓库的背景下 AWS。该架构涉及用于数据采集、存储、转换和消费的几个关键层和组件。
企业级存储
Amazon S3 Intelligent-Tiering 是一种存储类,它根据不断变化的访问模式在访问层之间移动数据,从而自动优化存储成本。这可确保频繁访问的数据随时可用,同时将访问频率较低的数据或“冷”数据存储在成本更低的层中。有关更多详细信息,您可以参阅 Amazon S3 存储类别
操作型数据存储层
Amazon Redshift 用于实现操作型数据存储、传播和数据集市功能。提供脚本以创建数据模式并部署数据定义语言(DDL),且包含加载 SAP 源数据所需的结构。可以对这些 DDL 进行自定义,使其包含 SAP-specific 字段。
数据传播层
通过 Glue 作业加载到 S3 中的增量数据可用于生成 Slowly Changing Dimension Type 2(SCD2)表,此表将保留完整变更历史记录。
数据集市层
利用 Redshift 中的实体化视图构建结构化的数据集市模型。事务数据通过主数据(属性和文本)进行扩充,从而构建出可直接用于数据使用的分析模型。
《在 AWS 解决方案基础上构建 SAP 数据仓库指南
