本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
数据湖架构
数据湖
利用数据湖,客户可以处理结构化数据和非结构化数据。数据湖架构基于“读时模式”方法设计,这意味着数据可以原始格式存储,仅在使用时(例如,创建财务报表时)才应用模式或结构。结构在从数据来源读取数据时进行定义,此时会确定数据类型和长度。因此,存储与计算实现解耦,依托低成本存储方案来扩展至 PB 级规模,且成本仅为传统数据库成本的一小部分。
借助数据湖,组织可以执行各类分析任务,例如创建交互式控制面板、生成可视化见解、处理大规模数据、开展实时分析,以及在各类数据来源中实施机器学习算法。
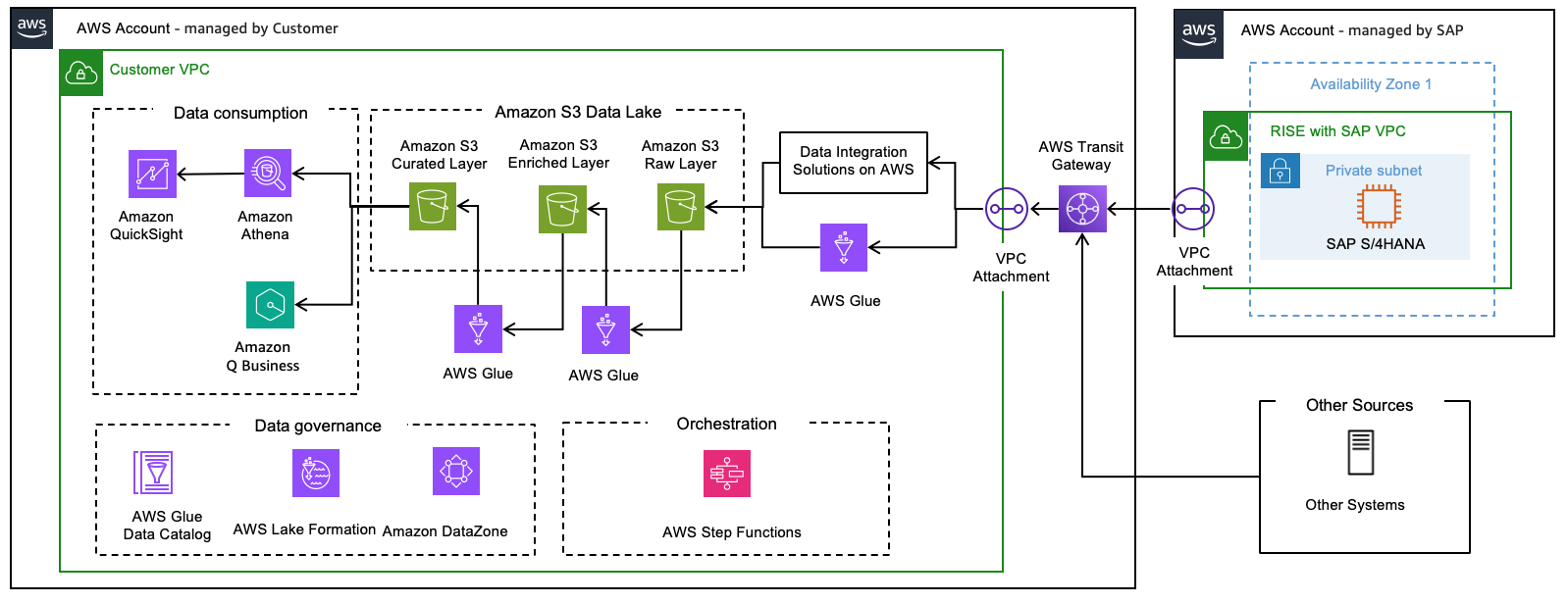
数据湖参考架构提供了三个不同的层,可将原始数据转化为有价值的见解:
原始层
原始层是数据湖中的初始层,基于 Amazon S3
从 SAP 中提取的数据(通过 SAP ODP OData
扩充层
扩充层基于 Amazon S3
来自原始层的数据会基于表键按正确顺序插入或更新至扩充层,并以原始格式保留(不进行任何转换或修改)。每条记录均需补充特定属性,例如提取时间和记录编号,此操作可通过 AWS Glue 作业实现。
精选层
精选层用于存储数据以供使用。在此层上,将物理删除已从来源中删除的记录。任何计算结果(如平均值、日期间隔等)或数据操作(如格式更改、从其他表中查找等)均可存储在此层以供使用。使用 AWS Glue 作业更新此层中的数据。基于这些数据表创建的 Amazon Athena 视图可通过 Amazon Quick Sight 或类似工具以供下游使用。
《包含 SAP Non-SAP 的数据湖和 AWS 解决方案数据指南》
