本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
最大限度减少规划开销
正如 Apache Spark 中的关键主题一节所述,Spark 驱动程序会生成执行计划。根据该计划,将任务分配给 Spark 执行程序进行分布式处理。但是,如果存在大量小文件或 AWS Glue Data Catalog 包含大量分区,Spark 驱动程序可能会成为瓶颈。要确定高昂的规划开销,请评测以下指标。
CloudWatch 指标
检查以下情况的 CPU 负载和内存利用率:
-
Spark 驱动程序 CPU 负载和内存利用率记录为高。通常,Spark 驱动程序不会处理您的数据,因此 CPU 负载和内存利用率不会激增。但是,如果 Amazon S3 数据来源有过多小文件,则列出所有 S3 对象并管理大量任务可能会导致资源利用率过高。
-
在 Spark 执行程序中开始处理之前存在较长的空闲时间。在以下示例屏幕截图中,Spark 执行器的 CPU 负载在 10:57 之前一直太低,尽管 AWS Glue 任务从 10:00 开始。这表明 Spark 驱动程序可能需要很长时间才能生成执行计划。在此示例中,检索数据目录中的大量分区并列出 Spark 驱动程序中大量的小文件需要很长时间。
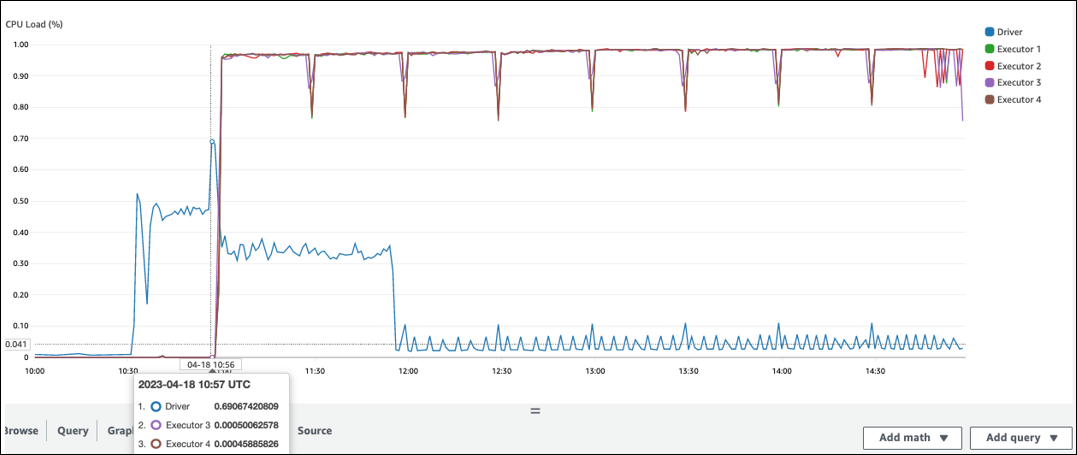
火花用户界面
在 Spark UI 的作业选项卡上,您可以看到提交时间。在以下示例中,Spark 驱动程序在 10:56:46 启动了 job0,尽管该作业从 10:00:00 开始。 AWS Glue

您还可以在 J ob 选项卡上查看 T asks(适用于所有阶段): Succeeded/Total时间。在这种情况下,任务数记录为 58100。如并行处理任务页面的 Amazon S3 部分所述,任务数量与 S3 对象的数量大致对应。这意味着 Amazon S3 中有约 58100 个对象。
有关此作业和时间线的更多详细信息,请查看阶段选项卡。如果您发现 Spark 驱动程序存在瓶颈,请考虑以下解决方案:
-
当 Amazon S3 的文件过多时,请考虑并行处理任务页面分区过多部分中有关并行度过大的指导。
-
当 Amazon S3 的分区过多时,请考虑减少数据扫描量页面 Amazon S3 分区过多部分中有关分区过多的指导。如果有许多分区,请启用 AWS Glue 分区索引,以降低从数据目录检索分区元数据的延迟。有关更多信息,请参阅使用 AWS Glue 分区索引提高查询性能
。 -
当 JDBC 有过多分区时,请降低
hashpartition值。 -
当 DynamoDB 的分区过多时,请降低
dynamodb.splits值。 -
当流作业的分区过多时,请减少分片的数量。
