本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
减少数据扫描量
首先,请考虑仅加载所需的数据。只需减少每个数据来源加载到 Spark 集群中的数据量,即可提升性能。要评测此方法是否合适,请使用以下指标。
您可以在 Spark 用户界面中查看从 Amazon S3 读取的字节的CloudWatch指标和更多详细信息,如 Spark 用户界面部分所述。
CloudWatch 指标
您可以在 ETL 数据移动(字节数)中查看从 Amazon S3 读取的大致数据量。该指标显示自上次报告以来所有执行程序从 Amazon S3 读取的字节数。您可以使用它监控来自 Amazon S3 的 ETL 数据移动,也可以将读取率与来自外部数据来源的摄取速率进行比较。
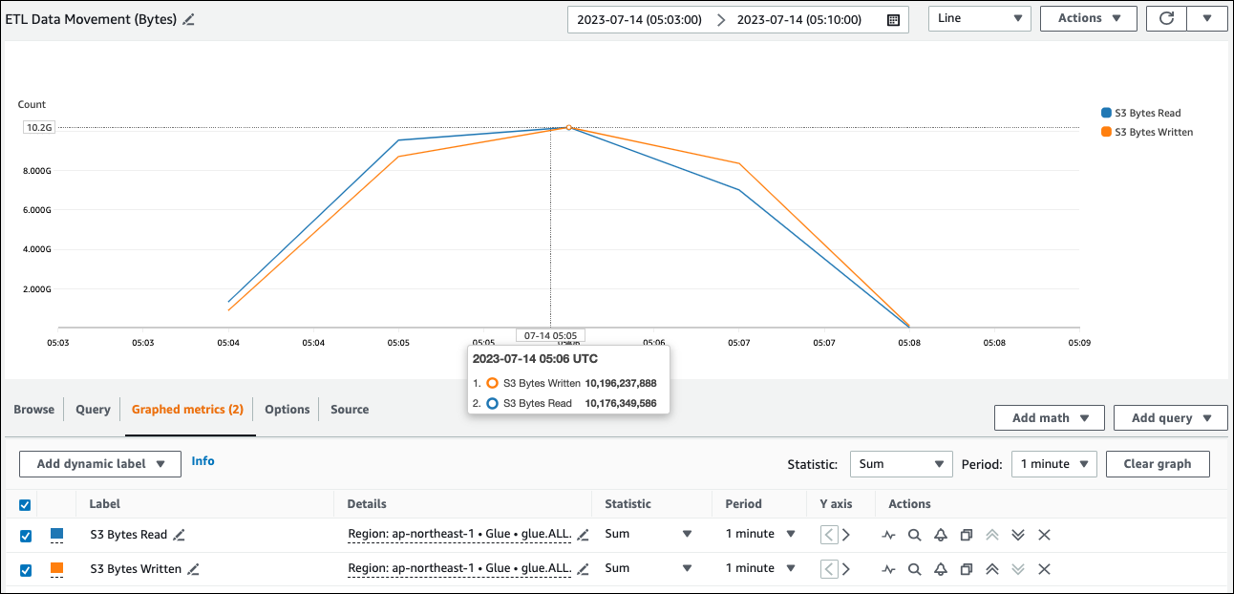
如果您观察到的 S3 字节读取数据点大于预期,请考虑以下解决方案。
火花用户界面
在 for Spark 用户界面的舞台选项卡上,你可以看到输入和输出的大小。 AWS Glue 在以下示例中,第二阶段读取 47.4 GiB 输入和 47.7 GiB 输出,而第五阶段读取 61.2 MiB 输入和 56.6 MiB 输出。

当您在 AWS Glue 作业中使用 Spark SQL 或 DataFrame 方法时,SQL/DataFrame选项卡会显示有关这些阶段的更多统计信息。在本例中,第二阶段显示读取的文件数:430、读取的文件大小:47.4 GiB 和输出行数:160,796,570。
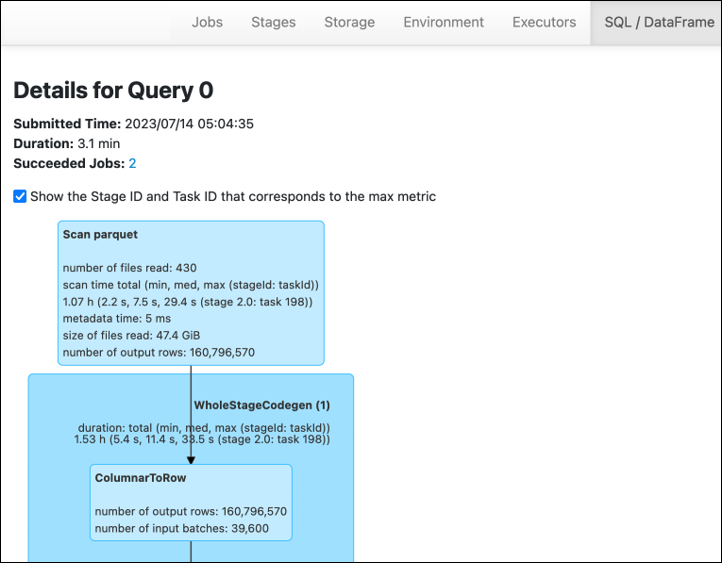
如果您发现正在读取的数据和正在使用的数据在规模上存在很大差异,请尝试以下解决方案。
Amazon S3
要减少从 Amazon S3 读取数据时加载到任务中的数据量,请考虑数据集的文件大小、压缩、文件格式和文件布局(分区)。 AWS Glue for Spark 作业通常用于原始数据的 ETL,但是为了实现高效的分布式处理,您需要检查数据源格式的特征。
-
文件大小:我们建议将输入和输出的文件大小保持在适中的范围内(例如 128 MB)。文件过小和文件过大都可能会导致问题。
大量小文件会导致以下问题:
-
Amazon S3 的网络负 I/O 载很大,这是因为向许多对象发出请求(例如
ListGet、或Head)需要开销(相比之下,只有少数对象存储相同数量的数据)。 -
Spark 驱动程序承受繁重 I/O 的处理负载,这将生成许多分区和任务,并导致并行度过高。
另一方面,如果您的文件类型不可分割(例如 gzip),并且文件太大,则 Spark 应用程序必须等待,直到单个任务完成读取整个文件。
要减少为每个小文件创建 Apache Spark 任务时产生的过多并行度,请使用文件分组。 DynamicFrames此方法降低了 Spark 驱动程序出现 OOM 异常的几率。要配置文件分组,请设置
groupFiles和groupSize参数。以下代码示例使用带有这些参数的 ETL 脚本中的 AWS Glue DynamicFrame API。dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
压缩:如果您的 S3 对象大小达到数百兆字节,请考虑对其进行压缩。有多种压缩格式,大致可以分为两类:
-
不可分割的压缩格式(例如 gzip),需要由一个 Worker 解压缩整个文件。
-
可分割的压缩格式(例如 bzip2 或 LZO(已编索引)),允许对文件进行部分解压缩,从而实现并行处理。
对于 Spark(以及其他常见的分布式处理引擎),您需要将源数据文件分割成引擎可以并行处理的块。这些单元通常称为分割单元。在您的数据采用可拆分格式后,经过优化的 AWS Glue 读取器可以通过向
GetObjectAPI 提供仅检索特定区块的Range选项来检索 S3 对象的拆分。请参考下图以了解实际工作原理。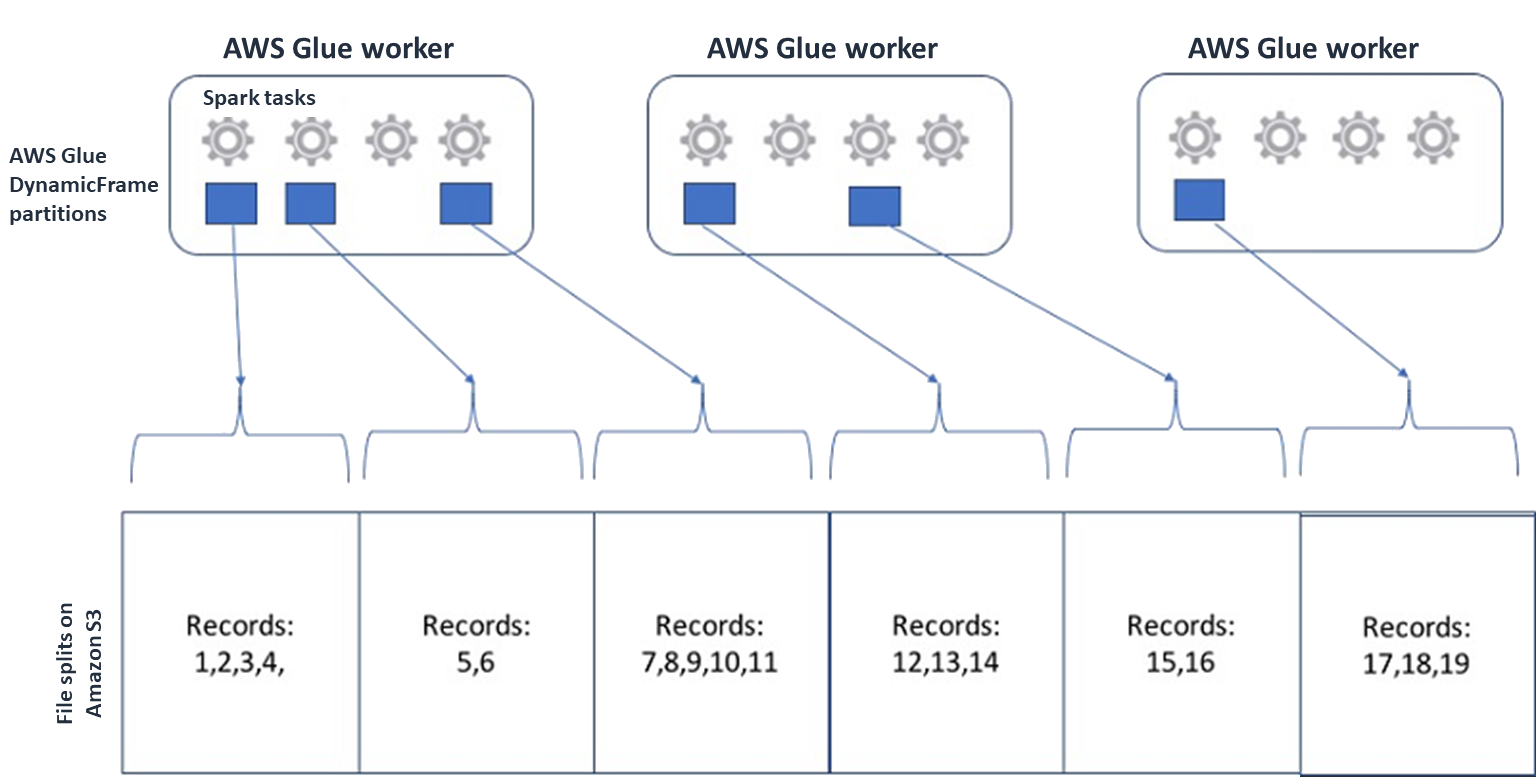
只要文件为最佳大小或者文件可分割,压缩数据便可显著加快应用程序的速度。较小的数据大小会减少从 Amazon S3 扫描的数据量以及从 Amazon S3 到 Spark 集群的网络流量。另一方面,压缩和解压缩数据需要更多的 CPU。所需的计算量与压缩算法的压缩率成正比。在选择可分割的压缩格式时,请考虑这种权衡取舍。
注意
虽然 gzip 文件通常不可分割,但您可以使用 gzip 压缩单个 parquet 块,并且这些块可以并行处理。
-
-
文件格式:使用列式格式。Apache Parquet
和 Apache ORC 是常见的列式数据格式。Parquet 和 ORC 通过采用基于列的压缩、根据每列的数据类型对其进行编码和压缩,从而高效地存储数据。有关 Parquet 编码的更多信息,请参阅 Parquet encoding definitions 。Parquet 文件也可分割。 列式格式按列对值进行分组,并将其一起存储在数据块中。使用列式格式时,您可以跳过对应不打算使用的列的数据块。Spark 应用程序只能检索您需要的列。通常,更好的压缩率或跳过数据块意味着从 Amazon S3 读取更少的字节,从而获得更好的性能。这两种格式还支持以下下推方法来减少 I/O:
-
投影下推:投影下推是一种仅检索应用程序中指定列的技术。您可以在 Spark 应用程序中指定列,如以下示例所示:
-
DataFrame 示例:
df.select("star_rating") -
Spark SQL 示例:
spark.sql("select start_rating from <table>")
-
-
谓词下推:谓词下推是一种高效处理
WHERE和GROUP BY子句的技术。两种格式都有表示列值的数据块。每个数据块都包含该块的统计信息,例如最大值和最小值。根据应用程序中使用的筛选条件值,Spark 可以使用这些统计信息来确定应该读取还是跳过该数据块。要使用此功能,请在条件中添加更多筛选条件,如以下示例所示:-
DataFrame 示例:
df.select("star_rating").filter("star_rating < 2") -
Spark SQL 示例:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
文件布局:通过根据数据的使用方式将 S3 数据存储到不同路径的对象中,您可以高效地检索相关数据。有关更多信息,请参阅 Amazon S3 文档中的使用前缀组织对象。 AWS Glue 支持以
key=value格式将密钥和值存储到 Amazon S3 前缀中,按照 Amazon S3 路径对数据进行分区。通过分区数据,您可以限制每个下游分析应用程序扫描的数据量,从而提升性能并降低成本。有关更多信息,请参阅中的 AWS Glue管理 ETL 输出的分区。分区将表分成不同的部分,并根据年、月和日等列值将相关数据保存在分组文件中,如以下示例所示。
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...您可以使用 AWS Glue Data Catalog中的表进行建模,定义数据集的分区。然后,您可以使用分区修剪来限制数据扫描量,如下所示:
-
对于 AWS Glue DynamicFrame,设置
push_down_predicate(或catalogPartitionPredicate)。dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
对于 Spark DataFrame,请设置一个固定的路径来修剪分区。
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
对于 Spark SQL,您可以将 where 子句设置为从数据目录修剪分区。
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
要在写入数据时按日期进行分区 AWS Glue,请在 DynamicFrame 中设置 p artitionKeys 或 partitionBy (),并在列 DataFrame 中设置日期信息,如下所
示。 -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
这可以提高输出数据使用者的性能。
如果您无权更改创建输入数据集的管线,则无法选择分区。相反,您可以使用 glob 模式排除不需要的 S3 路径。在 DynamicFrame读入时设置排除项。例如,以下代码不包括 2023 年 1 月到 9 月的日期。
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )您还可以在数据目录的表属性中设置排除项:
-
键:
exclusions -
值:
["**year=2023/month=0[1-9]/**"]
-
-
-
Amazon S3 分区过多:避免在包含大量值的列上对 Amazon S3 数据进行分区,例如包含数千个值的 ID 列。这可能会大大增加存储桶中的分区数量,因为可能的分区数量是您分区所依据的所有字段的乘积。分区过多可能会导致以下情况:
-
从数据目录中检索分区元数据的延迟增加
-
小文件数量增加,这需要更多的 Amazon S3 API 请求(
List、Get和Head)
例如,当您在
partitionBy或partitionKeys中设置日期类型时,yyyy/mm/dd等日期级分区适用于许多使用案例。但是,yyyy/mm/dd/<ID>可能会生成太多的分区,以至于对整体性能产生负面影响。另一方面,某些使用案例(例如实时处理应用程序)需要
yyyy/mm/dd/hh等许多分区。如果您的使用案例需要大量分区,请考虑使用 AWS Glue 分区索引来降低从数据目录检索分区元数据的延迟。 -
数据库和 JDBC
要减少从数据库检索信息时的数据扫描,可以在 SQL 查询中指定 where 谓词(或子句)。不提供 SQL 接口的数据库将提供自己的查询或筛选机制。
使用 Java 数据库连接(JDBC)的连接时,请提供包含以下参数的带 where 子句的 select 查询:
-
对于 DynamicFrame,请使用 sampleQuery 选项。使用
create_dynamic_frame.from_catalog时,按如下方式配置additional_options参数。query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )using create_dynamic_frame.from_options时,按如下方式配置connection_options参数。query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
对于 DataFrame,请使用查询
选项。 query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
对于亚马逊 Redshift,请使用 AWS Glue 4.0 或更高版本来利用亚马逊 Redshift Spark 连接器中的下推支持。
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
对于其他数据库,请查阅该数据库的文档。
AWS Glue 选项
