本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon Redshift 中的查询计划
查询计划是执行引擎在对数据执行查询时必须遵循的指令列表。您可以通过运行 EXPLAIN 命令,后跟实际查询文本来创建查询计划,如以下示例查询所示:
EXPLAIN select s.s_name, sum(li.l_quantity) as quantity from tpch.lineitem li join tpch.orders o on o.o_orderkey = li.l_orderkey and o.o_orderdate > '1992-05-01' join tpch.supplier s on s.s_suppkey = li.l_suppkey group by s.s_name order by quantity desc limit 10;
如果您对上述查询示例运行 EXPLAIN 命令,则会得到以下输出:
XN Limit (cost=1004400430902.15..1004400430902.17 rows=10 width=39) -> XN Merge (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Merge Key: sum(li.l_quantity) -> XN Network (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Send to leader -> XN Sort (cost=1004400430902.15..1004400430926.97 rows=9928 width=39) Sort Key: sum(li.l_quantity) -> XN HashAggregate (cost=4400430218.24..4400430243.06 rows=9928 width=39) -> XN Hash Join DS_BCAST_INNER (cost=21489.58..4400401726.35 rows=5698378 width=39) Hash Cond: ("outer".l_suppkey = "inner".s_suppkey) -> XN Hash Join DS_DIST_NONE (cost=21364.58..273387.85 rows=5698378 width=14) Hash Cond: ("outer".l_orderkey = "inner".o_orderkey) -> XN Seq Scan on lineitem li (cost=0.00..60012.15 rows=6001215 width=22) -> XN Hash (cost=17803.81..17803.81 rows=1424306 width=8) -> XN Seq Scan on orders o (cost=0.00..17803.81 rows=1424306 width=8) Filter: (o_orderdate > '1992-05-01'::date) -> XN Hash (cost=100.00..100.00 rows=10000 width=33) -> XN Seq Scan on supplier s (cost=0.00..100.00 rows=10000 width=33)
注意
示例查询计划输出是查询执行的简化概要介绍。示例计划未说明并行查询处理的详细信息。有关详细信息,请运行该查询,然后使用 SVL_QUERY_SUMMARY 或 SVL_QUERY_REPORT 视图获取查询摘要信息。
Amazon Redshift 查询编辑器 v2
您还可以使用查询编辑器 v2 中的解释选项查看 Amazon Redshift 中的查询计划。有关说明,请参阅 Amazon Redshift 文档中的使用查询编辑器 v2。
查询编辑器 v2 生成的查询计划包含以下信息:
-
执行引擎将执行的操作,自下而上地阅读结果
-
每个操作所执行步骤的类型
-
每个操作中使用的表和列
-
每个操作中处理的数据量(以字节为单位),以行数和数据宽度计
-
操作的相对成本(成本是比较计划内各步骤相对执行时间的衡量指标。成本不提供有关实际执行时间或内存消耗的精确信息,也不提供各执行计划之间有意义的比较。但是,成本可以指示查询中的哪些操作消耗最多的资源。)
EXPLAIN 计划
您可以使用 STL_EXPLAIN 系统表显示已提交供执行的查询的 EXPLAIN 计划。总体而言,使用 STL_EXPLAIN 可以帮助提升 Amazon Redshift 查询的性能、效率和成本效益。
使用 STL_EXPLAIN 的优势包括:
-
性能优化:
STL_EXPLAIN可帮助识别查询中可以进行优化以获得更好性能的区域。 -
查询规划:
STL_EXPLAIN可提供有关 Amazon Redshift 如何执行查询的信息,并可帮助识别查询中的潜在瓶颈。 -
调试:通过显示 Amazon Redshift 执行查询所采取的步骤,
STL_EXPLAIN可帮助诊断查询的问题。 -
了解 Amazon Redshift 行为:
STL_EXPLAIN可以深入了解 Amazon Redshift 如何处理查询,帮助您更好地理解 Amazon Redshift 行为。 -
成本优化:
STL_EXPLAIN可以提供有关查询估计成本的信息,帮助您识别可以优化成本的领域。
以下查询是如何返回给定查询计划节点的示例:
select nodeid as id, plannode, info from stl_explain where query=1042904 order by nodeid;
上述查询返回以下输出。
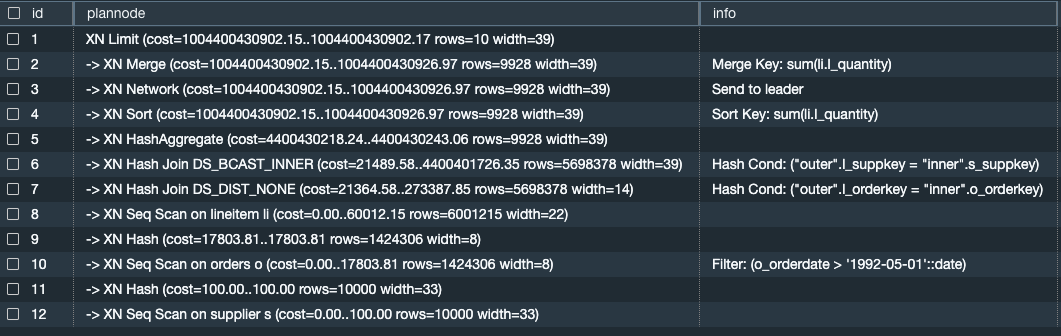
EXPLAIN 计划会返回每个操作的有用指标,包括成本、行数和宽度指标。例如,上述查询的第 7 行返回以下内容:
-> XN Hash Join DS_DIST_NONE (cost=21364.58..273387.85 rows=5698378 width=14)
成本
成本是对于比较计划内的操作非常有用的相对值。成本由被两个圆点分隔的十进制值组成。在此示例中,成本等于 21364.58..273387.85。请考虑以下事项:
-
第一个值(在本例中为
21364.58)提供返回此操作的第一行的相对成本。 -
第二个值(在本例中为
273387.85)提供完成操作的相对成本。
查询计划中的成本是累积的,并从较低的行向较高的行累积。在上面的示例输出中,第 7 行包括自身下方各行(即第 8-12 行及以后各行)中其他操作的成本。
行
行数是要返回的估计行数。在此示例中,扫描预计将返回 5698378 行。行数估算基于 ANALYZE 命令生成的可用统计数据。如果最近未运行过 ANALYZE,则估算的可靠性会降低。
宽度
宽度是平均行的估计宽度(以字节为单位)。在此示例中,平均行的宽度应为 14 个字节。
