本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon Redshift 数据仓库的架构组件
我们建议您对 Amazon Redshift 数据仓库中的核心架构组件有基本的了解。这些知识可以帮助您更好地了解如何设计查询和表以实现最佳性能。
Amazon Redshift 中的数据仓库由以下核心架构组件组成:
-
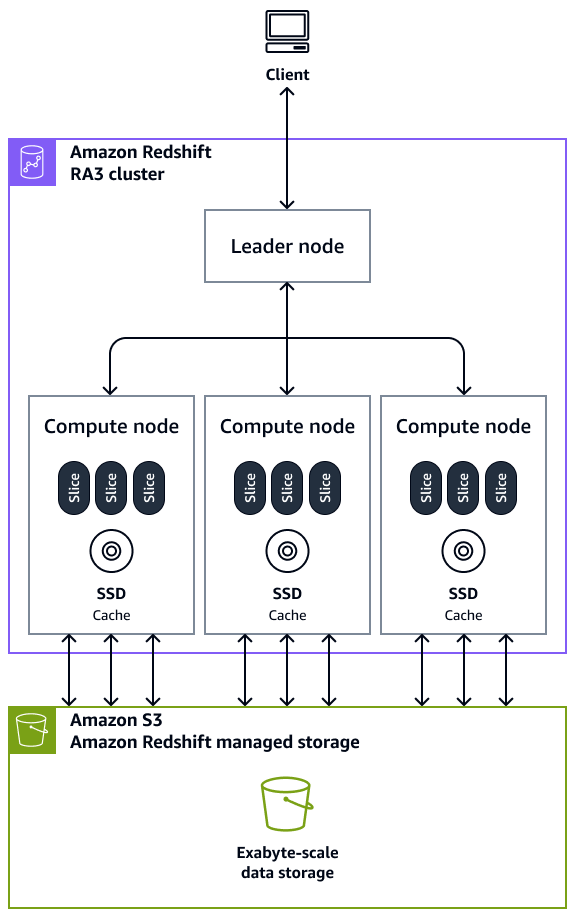
集群:集群由一个或多个计算节点组成,是 Amazon Redshift 数据仓库的核心基础设施组件。计算节点对外部应用程序是透明的,但您的客户端应用程序仅与领导节点直接交互。一个典型的集群包含两个或多个计算节点。计算节点通过领导节点进行协调。
-
领导节点:领导节点管理客户端程序和所有计算节点的通信。每当向集群提交查询时,领导节点还会准备运行查询的计划。计划准备好后,领导节点编译节点、将编译后的节点分发给计算节点,然后将数据切片分配给每个计算节点以处理查询结果。
-
计算节点:计算节点运行查询。领导节点为运行查询的计划的单个元素编译代码并将代码分配给各个计算节点。计算节点运行编译后的代码,并将中间结果发送回领导节点以便最终聚合。每个计算节点均拥有自己的专用 CPU、内存和连接的磁盘存储。当您的工作负载增加时,您可以通过增加节点数和/或升级节点类型来增加集群的计算容量和存储容量。
-
节点切片:一个计算节点会分成多个称为切片的单元。将为计算节点中的每个切片分配节点的内存和磁盘空间的一部分,用于处理分配给节点的工作负载的一部分。然后,切片将并行工作以完成操作。数据根据特定表的分配方式和分配键在切片之间分配。数据的均匀分布使 Amazon Redshift 能够将工作负载均匀分配给切片,并最大限度地发挥并行处理的优势。每个计算节点的切片数是根据节点的类型决定的。有关更多信息,请参阅 Amazon Redshift 文档中的 Amazon Redshift 中的集群和节点。
-
大规模并行处理(MPP):Amazon Redshift 使用 MPP 架构来快速处理数据,甚至处理复杂的查询和海量的数据。多个计算节点对数据的各部分运行相同的查询代码,以最大限度地提升并行处理效率。
-
客户端应用程序:Amazon Redshift 与各种提取、转换、加载(ETL)、商业智能(BI)报告、数据挖掘和分析工具集成。所有客户端应用程序均仅通过领导节点与集群通信。
下图显示 Amazon Redshift 数据仓库的架构组件如何协同工作以加快查询速度。