本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
灾难恢复协调器框架概述
DR Orchestrator Framework 提供一键式解决方案,用于协调和自动执行数据库的跨区域灾难恢复。 AWS 它使用AWS Step Functions和AWS Lambda来执行故障切换和故障恢复期间所需的步骤。Step Functions 状态机为协调器设计中的决策提供了基础。用于执行故障转移或故障恢复操作的 API 操作被编码到从状态机内部调用的 Lambda 函数中。Lambda 函数运行 适用于 Python (Boto3) 的 AWS SDK
DR Orchestrator Framework 包含两台主状态机,分别对应于故障转移和故障恢复阶段。
对于 Amazon RDS,故障转移阶段将跨区域 RDS 只读副本提升为独立数据库实例。对于 Amazon Aurora 来说,当主区域在罕见的意外中断期间出现故障时,其写入节点不可用。写入器节点和辅助群集之间的复制将停止。您必须将辅助群集与全局数据库分离,并将其提升为独立群集。应用程序可以连接并向独立集群发送写入流量。您可以使用相同的过程将全球数据库的主数据库集群切换到辅助区域。 对于受控场景,请使用此方法,例如:
-
运营维护
-
计划中的操作程序
-
将亚马逊 ElastiCache (Redis OSS) 辅助集群提升为新的主集群
故障恢复阶段在活动主区域和新的辅助区域之间建立数据的实时复制。
重要的是要明白 DR Orchestrator 仅适用于数据库。所有引用这些数据库且位于同一区域的应用程序可能需要单独的串联故障转移解决方案。在数据库故障转移到辅助区域后,需要更新应用程序以连接到将用作数据源的新数据库实例。
故障转移过程
要执行故障转移,请运行DR Orchestrator FAILOVER状态机。在此阶段,辅助区域中已经存在辅助数据库,可以作为只读副本 (Amazon RDS),也可以作为辅助集群 (Amazon Aurora)。当您运行DR Orchestrator
FAILOVER状态机时,它会将辅助数据库提升为主数据库。
灾难恢复协调器故障转移架构
下图显示了使用 DR Orchestrator 时 Amazon Aurora 的故障转移过程的概念。Amazon Aurora 和亚马逊 ElastiCache 使用相同的工作流程,但使用不同的状态机和 Lambda 函数。
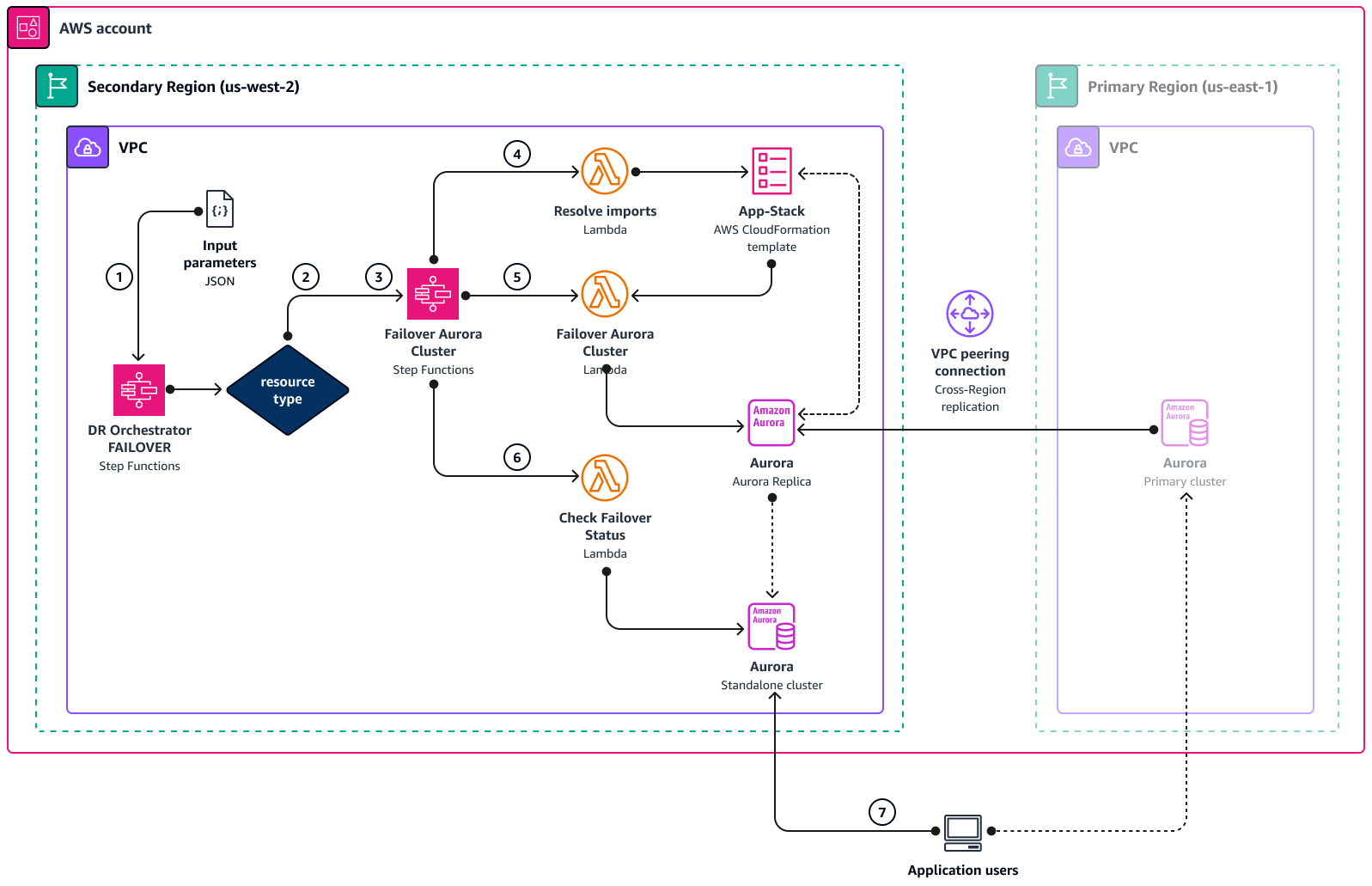
-
DR Orchestrator FAILOVER状态机读取输入的 JSON 参数。 -
根据
resourceType参数,状态机调用其他状态机:Promote RDS Read ReplicaFailover Aurora Cluster、或Failover ElastiCache。如果在输入中传递了多个资源,则这些状态机将并行运行。 -
Failover Aurora Cluster状态机在以下三个步骤中分别调用 Lambda 函数。 -
L
Resolve importsambda 函数使用模板中的实际值"! import <export-variable-name>"进行解析。App-StackAWS CloudFormation -
Failover Aurora ClusterLambda 函数将只读副本提升为独立数据库实例。 -
L
Check Failover Statusambda 函数检查已推广的数据库实例的状态。状态变为 “可用” 后,Lambda 函数将成功令牌发送回调用状态机并完成。 -
您可以将应用程序重定向到灾难恢复区域 (
us-west-2) 中的独立数据库,该数据库现在是主数据库。
故障恢复过程
在您以前的主区域 (us-east-1) 再次启动后,您可以回切到该区域,以便中的数据库再次us-east-1成为主区域。要启动故障恢复,请运行DR Orchestrator FAILBACK状态机。顾名思义,此状态机开始将您的新主区域 (us-west-2) 中的更改复制回以前的主区域 (us-east-1),后者充当当前的辅助区域。
在两个区域之间建立复制后,您可以启动故障恢复。要回切并返回到您的原始主区域 (us-east-1),请在当前辅助区域 (us-east-1) 中运行DR Orchestrator FAILOVER状态机以将其升级到主区域。
DR Orchestrator 故障恢复架构
下图显示了使用 DR Orchestrator 时 Amazon Aurora 的故障恢复过程的概念。
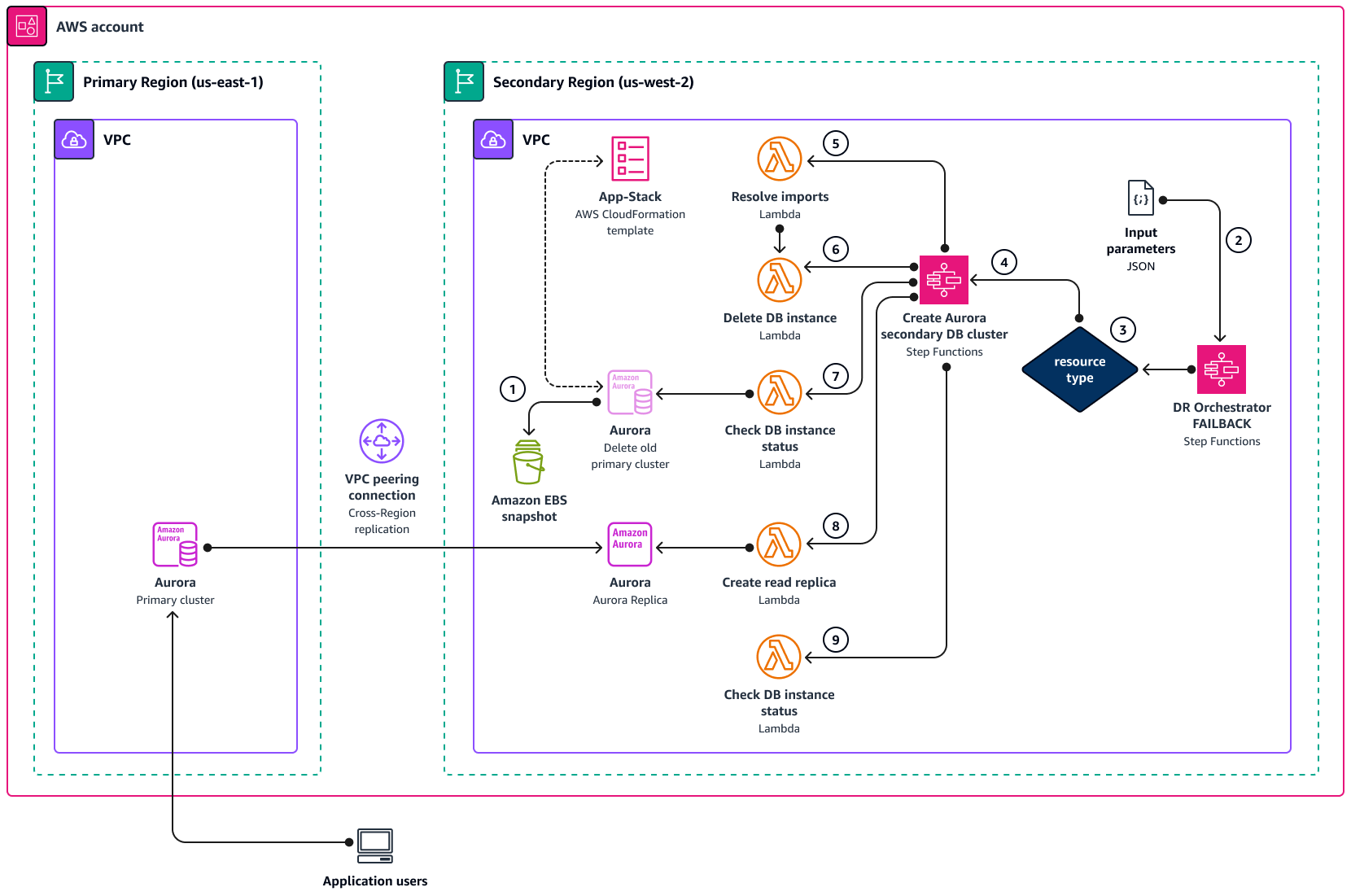
-
在开始故障恢复之前,请手动拍摄数据库快照,以便在执行根本原因分析 (RCA) 时使用。
此外,在之前的主区域 (
us-east-1) 中对 Aurora 集群禁用。DeletionProtection -
DR Orchestrator FAILBACK状态机读取输入的 JSON 参数。 -
基于此
resourceType,DR Orchestrator FAILBACK状态机调用Create Aurora Secondary DB Cluster状态机。 -
Create Aurora Secondary DB Cluster状态机通过以下五个步骤中的每一个步骤调用 Lambda 函数。 -
L
Resolve importambda 函数使用模板中的实际值"! import <export-variable-name>"进行解析。App-StackCloudFormation -
L
Delete DB Instanceambda 函数会删除以前的主实例。 -
Check DB instance statusLambda 函数会进行检查,Delete DB Instance status直到数据库被删除。 -
Create Read ReplicaLambda 函数从新的主区域中的数据库实例在辅助区域中创建只读副本。 -
Check DB instance statusLambda 函数检查只读副本数据库实例的状态。当状态为 “可用” 时,Lambda 函数将成功令牌发送回调用状态机,调用状态机已完成。
灾难恢复协调器故障转移
在主区域 (us-east-1) 关闭时或计划内事件(例如操作维护)期间,在灾难恢复事件中使用DR Orchestrator FAILOVER状态机。
可以调用该函数并行地对单个或多个数据库进行故障切换。
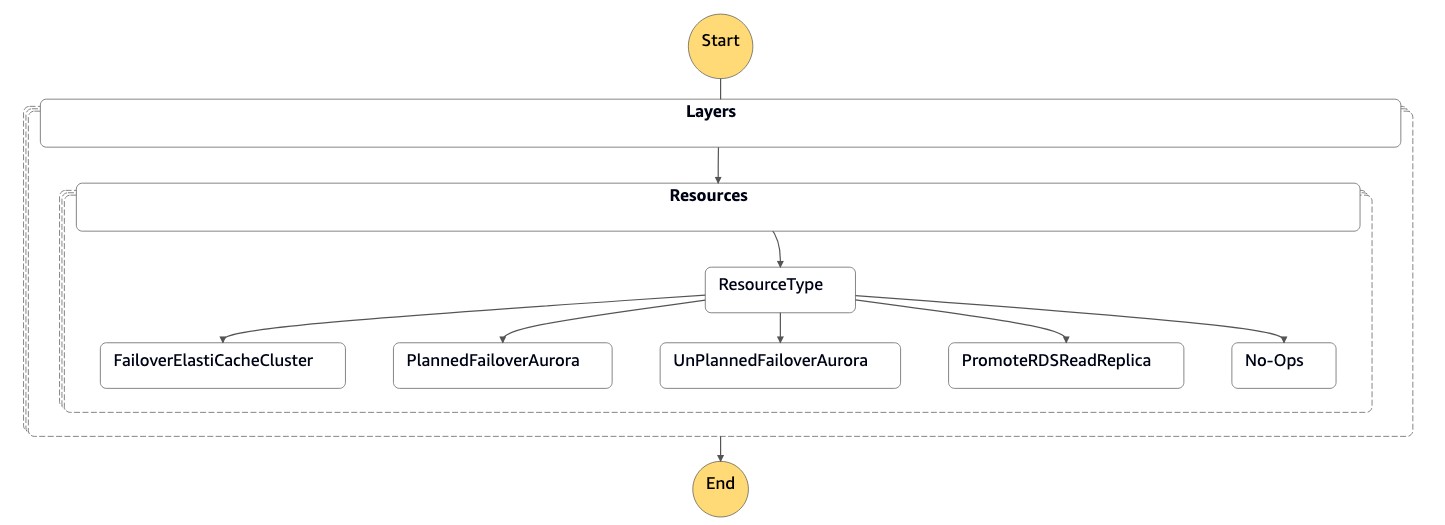
状态机接受 JSON 格式的参数,如以下代码所示:
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PromoteRDSReadReplica", "resourceName": "Promote RDS MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn" } }, { "resourceType": "FailoverElastiCacheCluster", "resourceName": "Failover ElastiCache Cluster", "parameters": { "GlobalReplicationGroupId": "!Import demo-redis-cluster-global-replication-group-id", "TargetRegion": "!Import demo-redis-cluster-target-region", "TargetReplicationGroupId": "!Import demo-redis-cluster-target-replication-group-id" } } ] } ] }
参数详细信息
下表显示了DR Orchestrator
FAILOVER状态机使用的参数。
| 参数名称 | 说明 | 预期值 |
|---|---|---|
layer(必填:数字) |
处理顺序。第 1 层中定义的所有资源都必须先运行,然后才能运行第 2 层资源。 | 1 或 2,依此类推 |
| 资源(必填:字典数组) | 单层中的所有资源并行运行。 |
|
resourceType(必填:字符串) |
用于标识资源的资源类型 | PromoteRDSReadReplica 或 FailoverElastiCacheCluster |
resourceName(可选:字符串) |
确定这些资源属于哪个应用程序组合 | Promote RDS for MySQL Read Replica |
| 参数(必填:字典数组) | 对 AWS 数据库进行故障切换或故障恢复所需的参数列表 |
|
灾难恢复协调器故障恢复
在灾难恢复事件之后使用DR Orchestrator FAILBACK状态机,即以前的主区域 (us-east-1) 已启动。您可以从新的主区域 (us-west-2) 为以前的主区域的 Amazon RDS 创建只读副本,以符合您的灾难恢复策略。由于这是计划内活动,因此您可以将此活动安排在周末或非高峰工作时间进行,预计会有停机时间。
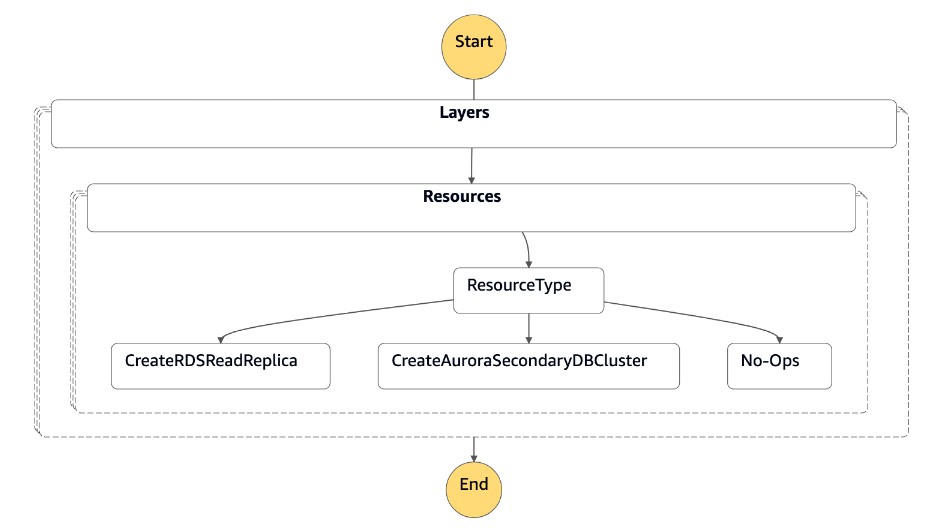
状态机接受 JSON 格式的参数,如以下代码所示:
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateRDSReadReplica", "resourceName": "Create RDS for MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn", "SourceRDSInstanceIdentifier": "!Import rds-mysql-instance-source-identifier", "SourceRegion": "!Import rds-mysql-instance-SourceRegion", "MultiAZ": "!Import rds-mysql-instance-MultiAZ", "DBInstanceClass": "!Import rds-mysql-instance-DBInstanceClass", "DBSubnetGroup": "!Import rds-mysql-instance-DBSubnetGroup", "DBSecurityGroup": "!Import rds-mysql-instance-DBSecurityGroup", "KmsKeyId": "!Import rds-mysql-instance-KmsKeyId", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "Port": "!Import rds-mysql-instance-DBPortNumber", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] }
