本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
设计无服务器 AI 架构
要将无服务器 AI 的原理转化为现实世界的系统,需要经过深思熟虑的架构。目标是将松散耦合集成 AWS 服务 到模块化的智能管道中,这些管道可以弹性扩展并实时响应。
本节提供了有关如何使用 AWS 无服务器服务(包括生成式 AI 编排、实时推理和边缘计算)组装云原生 AI 系统的规范性指导。每种架构模式都对应于一个常见的企业用例,从而确保相关性和适用性。
本节内容
基础架构模式
在传统的事件驱动应用程序架构中,系统分为四个逻辑层,在实现可扩展性和响应性的同时,将关注点分开。在顶部,应用程序层处理用户交互和用户界面事件 APIs,通常会将特定域的事件触发到系统中。在其之下,编排层使用状态机或无服务器工作流程等工具管理工作流程、业务规则和事件排序。服务层包含模块化、可重复使用的函数或微服务,用于响应事件和执行核心逻辑。在基础上,数据层负责持久性、流式传输和事件采集。数据层利用数据库、对象存储或事件日志等服务来发出和使用变更事件。这些层共同支持松散耦合、可扩展和可维护的架构,在该架构中,事件驱动整个堆栈的流动。
无服务器 AI 系统同样由松散耦合的事件驱动服务组成,这些服务可以独立扩展、演变和恢复。要设计具有一致性和可扩展性的系统,必须将架构视为五个不同的层。每个图层都有特定的功能,并直接映射到专门建造 AWS 服务的图层。下图显示了每个图层。
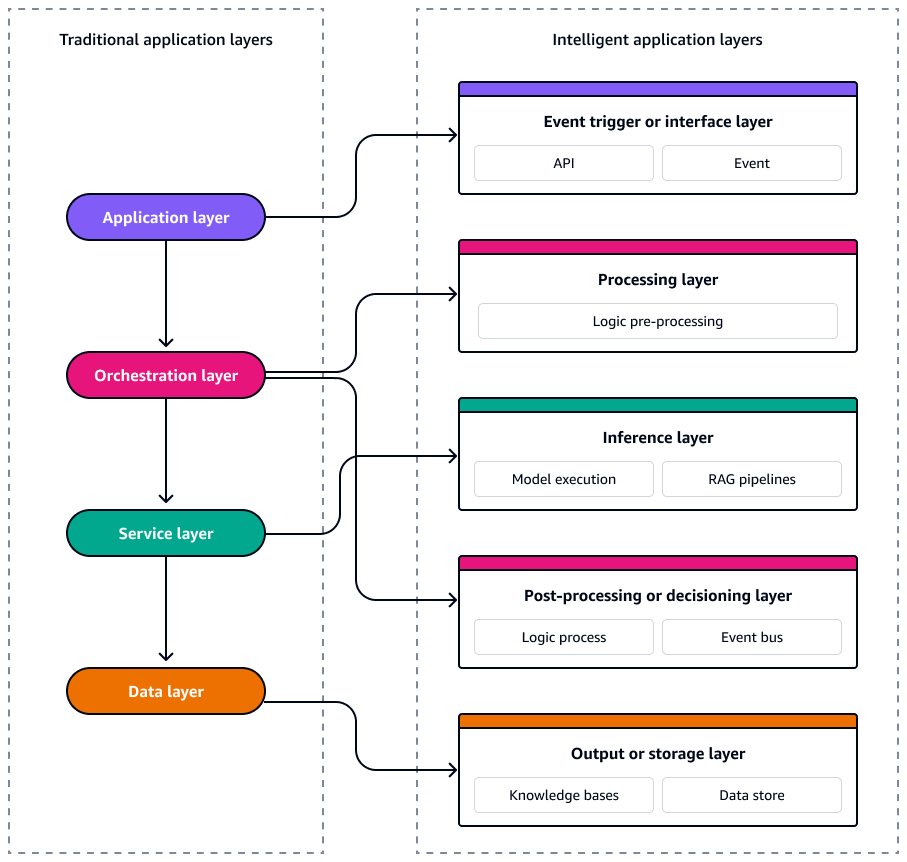
这五层构成了构建事件驱动的智能应用程序的蓝图,这些应用程序具有弹性、可观察性,并且针对成本和性能进行了优化。
事件触发器或接口层
事件触发器或接口层是您的无服务器 AI 系统的入口点。它捕获用户交互、系统事件或数据更改,并将其作为结构化事件发送到架构中。它支持异步编排,并将上游输入与下游处理逻辑分离。
事件触发层的职责包括以下内容:
-
捕获用户操作,例如点击、消息和上传
-
发送域名事件或更改通知
-
对传入的数据进行标准化以供下游使用
AWS 服务 该层常用的包括以下内容:
-
Amazon API Gateway 接受通过 REST 或的用户输入 WebSocket APIs。
-
Amazon 使用架构注册表 EventBridge路由内部或外部事件。
-
亚马逊简单存储服务 (Amazon S3) 会在创建对象(例如文档上传和媒体文件)时触发。
-
亚马逊 Kinesis 和适用于 Apache Kafka 的亚马逊托管流媒体 Kafka(亚马逊 MSK)可以大规模摄取直播事件。
示例:通过网络表单提交的客户支持请求会触发一条 EventBridge 规则,在下游启动 Amazon Bedrock 代理工作流程。
处理层
在将数据传递给 AI 模型之前,处理层会对其进行转换或充实。它使用查找表或外部来处理预处理任务,例如输入验证、格式设置、元数据标记、语言检测和数据扩充。 APIs
处理层的职责包括以下内容:
-
验证和标准化原始输入。
-
提取或注入语言和客户 ID 等元数据。
-
基于数据属性的路由或分支逻辑。
AWS 服务 该层常用的包括以下内容:
-
AWS Lambda是用于转换逻辑的无状态、事件驱动的计算。
-
AWS Step Functions协调多步骤预处理任务。
-
Amazon C omprehend 提供语言检测、实体识别或情感分析作为预处理的一部分。
示例:在 AI 汇总之前,使用 Lambda 和 Amazon Comprehend 对上传的保险索赔进行个人身份信息 (PII) 和文件类型扫描。
推理层
作为 AI 系统的核心,推理层运行机器学习 (ML) 或基础模型 (FM) 推理。它可能包括一个或多个模型(生成模型、预测模型或分类模型),具体取决于用例。
推理层的职责包括以下内容:
-
执行 ML 或 FM 模型推断。
-
生成预测、分类或生成的内容。
-
在适用的情况下,集成检索增强生成 (RAG) 上下文。
AWS 服务 该层常用的包括以下内容:
-
Amazon Bedrock 提供来自 Anthropic、Amazon(适用于亚马逊 Nova)等提供商的基础模型推断(文本、图像、多模态)Meta。Mistral
-
Amazon SageMaker Serverless Inf erence 大规模运行自定义 ML 模型。
-
Amazon Bedrock Agen ts 提供大型语言模型 (LLM) 驱动的推理和基于目标的编排。
示例:Amazon Bedrock 代理使用 Amazon Nova Pro 根据企业知识使用 RAG 生成对复杂支持查询的响应。
后处理层或决策层
后处理或决策层对推理结果进行细化或根据推理结果采取行动。它可以格式化响应、记录输出、调用下游操作或根据模型置信度、分类或外部业务规则做出决策。
后期处理或决策层的职责包括以下内容:
-
为下游系统或显示器格式化 AI 输出。
-
触发条件逻辑或调用 APIs。
-
路由经过丰富的数据以进行存储或分析。
AWS 服务 该层常用的包括以下内容:
-
Lambda 可以格式化结果、应用转换或调用。 APIs
-
亚马逊简单通知服务 (Amazon SNS),并根据 EventBridge 模型输出发出更多的事件。
-
Step Functions 应用连锁逻辑,例如,如果情绪等于 “愤怒”,则升级支持案例。
示例:LLM 提供的产品推荐在发送给用户之前,使用 Lambda 函数根据实时库存进行交叉验证。
输出层或存储层
最后,输出层或存储层负责向用户或系统交付结果,并保留结构化输出,用于审计、分析或反馈循环。
输出层或存储层的职责包括以下内容:
-
通过 APIs 或将 AI 结果返回给最终用户 UIs。
-
保留结构化输出和日志。
-
馈入数据湖或再训练管道。
AWS 服务 该层常用的包括以下内容:
-
Amazon S3 存储推理日志、摘要或生成的内容。
-
Amazon DynamoDB 为特定于会话的 A I 输出提供低延迟的键值存储。
-
Amazon OpenSearch 服务为搜索和分析提供索引结构化输出。
-
API Gateway 并向前端或移动客户端 WebSocket APIs 提供返回响应。
示例:由 Amazon Bedrock 生成的法律文件摘要存储在 Amazon S3 中,并在 OpenSearch 服务中编制索引,以实现语义企业搜索。
跨层设计注意事项
以下关键设计注意事项和模式适用于所有建筑层:
-
弹性 — 每层都应失败并独立重试(例如 Lambda DLQs 上的死信队列 ())。
-
可观察性 — 将每个阶段的结构化日志、跟踪和指标发送到 Amazon, CloudWatch 以检测行为偏差。
-
安全-使用 AWS Identity and Access Management(IAM) 角色分离和 AWS Key Management Service(AWS KMS) 进行跨层数据加密。
-
成本优化-尽可能使用异步执行,并选择大小合适的模型。
-
可扩展性 — 模块化设计允许独立更换或升级服务。
这五层构成了模块化、可扩展的无服务器参考架构,适用于基于人工智能的工作负载。 AWS每个层都可以独立开发、部署和优化,从而实现快速迭代、卓越运营以及跨业务领域的明确问题分离。
通过使用这种分层模式作为设计支架,企业可以标准化其无服务器人工智能方法,并充满信心地加快从原型到生产的过程。
架构设计注意事项
AWS 启用的 Serverless AI 架构使您能够构建模块化、可扩展和生产级的智能应用程序。无论你是在边缘部署模型、编排多步推理管道,还是构建生成式 AI 助手, AWS 服务 都可以为下一代 AI 原生应用程序提供动力。
在设计无服务器 AI 架构时,请记住以下主要设计重点和最佳实践:
-
安全 — 使用精细的 IAM 角色,加密提示和输出,并限制 API 访问权限。
-
可观察性 — 为每个管道阶段集成 CloudWatch AWS X-Ray、和自定义日志。
-
可扩展性-仅使用无服务器组件,例如 Lambda、Amazon Bedrock 和无服务器推理。 SageMaker
-
延迟-利用 Lambda @Edge、预配置的并发性或异步推理。
-
模块化 — 使用事件触发器和隔离函数为每项任务设计管道。
-
可重用性-使用 Step Functions 对提示进行参数化,使用共享的 Lambda 层并解耦逻辑。
