本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
灾难恢复计划
灾难恢复 (DR) 是企业业务连续性和合规性的关键服务。AMS 与您合作,帮助您规划、实施和维护 AMS 灾难恢复策略。
AMS landing zone (LZ)(多账户和单账户)为满足大多数灾难保护场景的 AMS 基础设施组件提供原生、多可用区、高可用性。但是,根据您企业的地理覆盖范围,您可能需要区域保护。为了实现跨区域可用性和灾难恢复,需要在不同的地区使用另一个 AMS 账户(对于多账户 landing zone 和单账户着陆区都是如此)。
AMS 符合本博客 “在灾难中快速恢复任务关键型系统” 中所述的 AWS 灾难
多站点(或高可用性)
热待机
飞行员灯
备份与还原
以下各节将介绍这些选项以及对它们的 AMS 支持。
Multi-site 或高可用性 (HA)
HA 解决方案通常由应用程序的内置功能提供,例如集群或同步复制。用户会被定向到 Prod 和 HA/DR 节点。DNS 可以直接指向节点,也可以通过弹性负载均衡器 (ELB) 指向节点。
作为您 Well-Architected-Review 和灾难恢复规划的一部分,您的 AMS 云架构师 (CA) 将与您合作。
HA DR 利用应用程序和 AWS原生服务和功能,如下图所示:
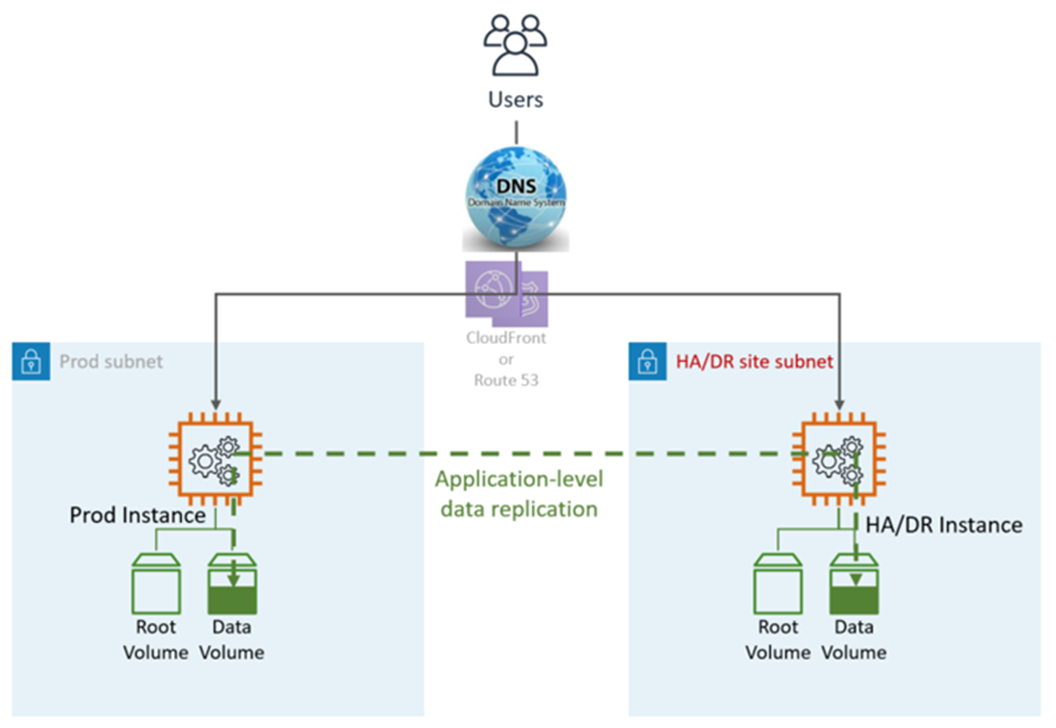
灾难恢复站点可以是相同的,也可以是不同的 AWS 区域。
注意
不同的区域 (Cross-Region) 将具有不同的活动目录环境。
DR(故障转移)步骤:自动故障转移,无需手动步骤。如果主 LZ 出现故障,用户将被自动重新路由到该节点。 DR/HA 这是通过 DNS 和应用程序配置实现的。
HA DR 指标:
恢复点目标 (RPO):<5 分钟
恢复时间目标和 (RTO):<5 分钟
维护:高(两种环境都需要同步更改,例如应用程序配置、修补、SG 或 ALB、证书等)。
成本:高
温备用
“热备用” 一词用于描述灾难恢复 (DR) 场景,在这种场景中,缩小版本的环境正在云中运行。
数据复制通常由应用程序层异步处理到在线实例,而其余实例(例如应用程序层和 Web 层)可能会关闭以节省成本。用户只能被定向到生产站点。其他 AWS 资源,例如弹性负载均衡器 (ELB),也可以在灾难恢复站点中预配置。
作为您 Well-Architected-Review 和灾难恢复规划的一部分,您的 AMS 云架构师 (CA) 将与您合作。
Warm Standby DR 利用应用程序和 AWS本机服务和功能,如下图所示:
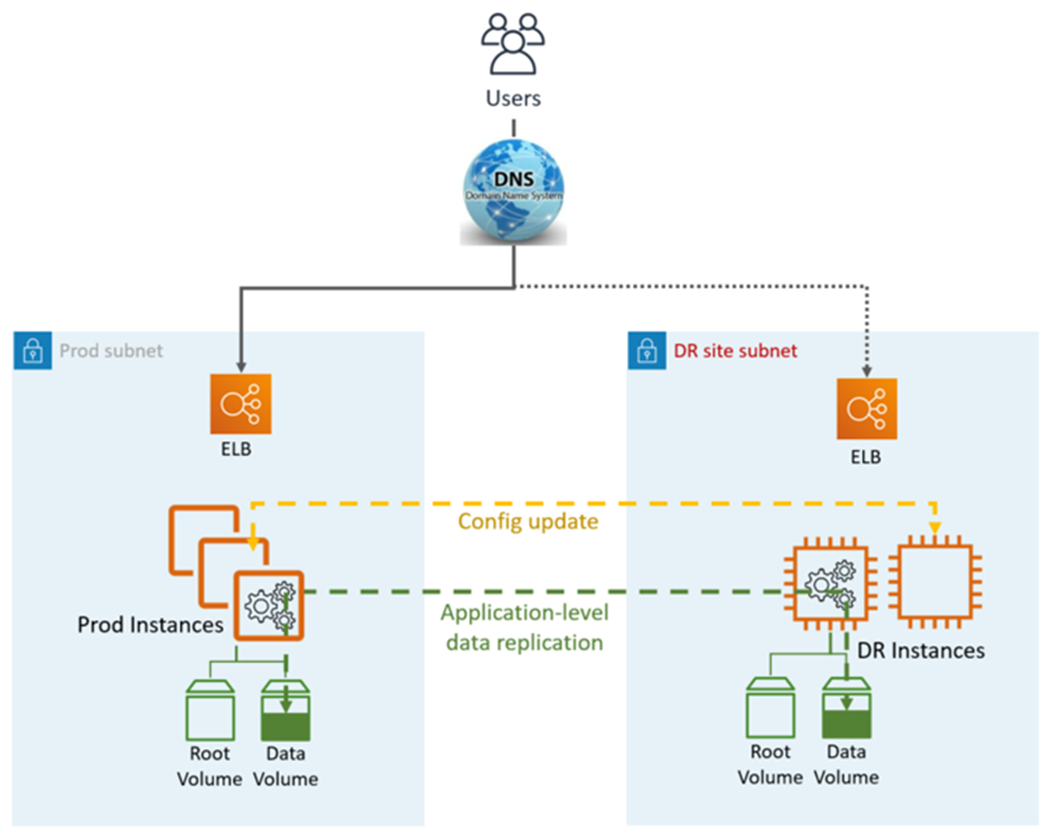
灾难恢复站点可以是相同的,也可以是不同的 AWS 区域。
注意
不同的区域 (Cross-Region) 将具有不同的活动目录环境。
DR(故障转移)步骤:
停止数据复制,将灾难恢复站点中的数据实例设为主实例
根据需要更新应用程序配置(新 IP、服务器名称等)
将 DNS 重定向到灾难恢复站点 (ELB)
AD 依赖关系(如果需要)(服务帐号、SPN、GPO 等)
HA DR 指标:
恢复点目标 (RPO):<1 小时
恢复时间目标和 (RTO):<1 小时(取决于实例数量和编排)
维护:高(两个环境都需要同步更改,例如应用程序配置、补丁、安全组 (SG) 或应用程序负载均衡器 (ALB)、证书等)。
成本:中等
指示灯
在这种灾难恢复 (DR) 方法中,您可以为一组有限的核心服务复制 Prod 环境的一部分。基础架构的一小部分始终处于运行状态,同时同步可变数据(例如数据库或文档),而基础架构的其他部分则处于关闭状态,仅在测试期间使用。与备份和恢复方法不同,您必须确保最关键的核心元素已经配置好并在 DR landing zone(指示灯)中运行。
作为您 Well-Architected-Review 和灾难恢复规划的一部分,您的 AMS 云架构师将与您合作。
Pilot Light DR 利用应用程序和 AWS原生服务和功能,如下图所示:
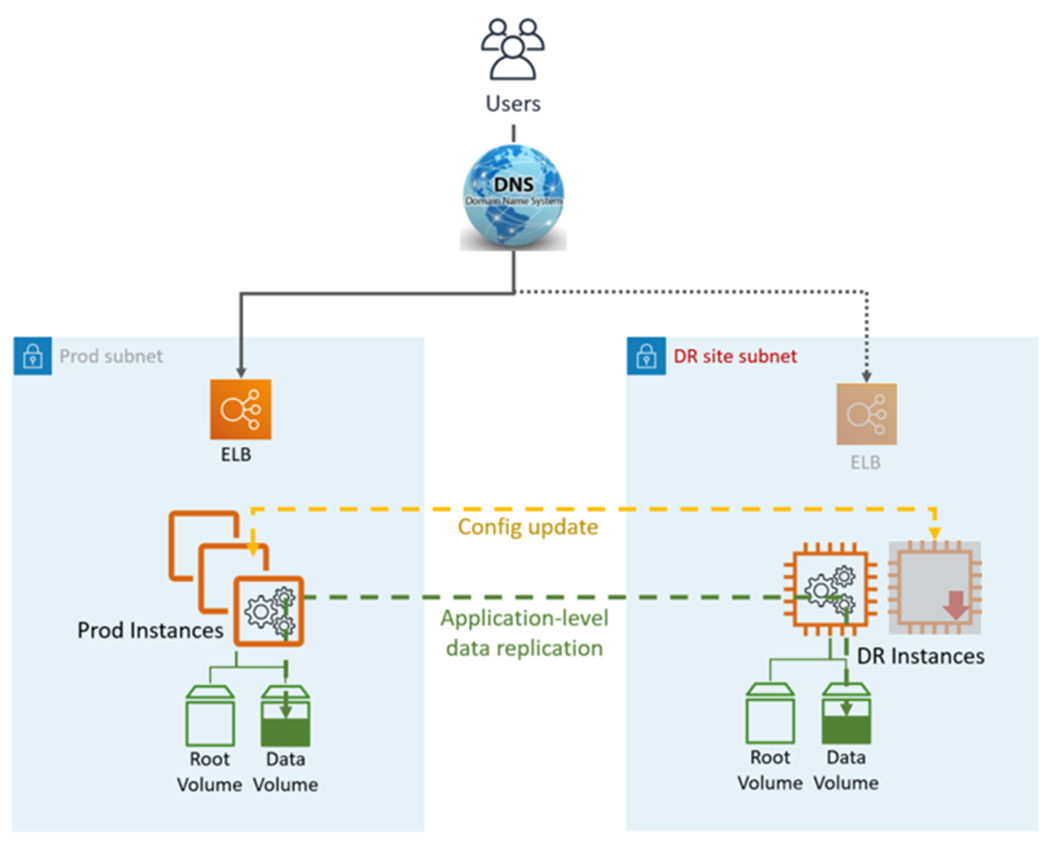
灾难恢复站点可以是相同的,也可以是不同的 AWS 区域。
注意
不同的区域 (Cross-Region) 将具有不同的活动目录环境。
DR(故障转移)步骤:
停止数据复制,将灾难恢复站点中的数据实例设为主实例
启动已关闭的实例和基础架构
根据需要更新应用程序配置(新 IP、服务器名称等)
根据需要将实例添加到 ELB
将 DNS 重定向到灾难恢复站点 (ELB)
AD 依赖关系(如果需要)(服务帐号、SPN、GPO 等)
指示灯灾难恢复指标:
恢复点目标 (RPO):<1 小时
恢复时间目标和 (RTO):约 1 小时(取决于实例数量和编排)
维护:中等
成本:中等
备份和还原
这种简单而低成本的灾难恢复 (DR) 方法可以将您的数据和应用程序从任何地方备份到 DR landing zone,以便在灾难恢复期间使用。
作为备份和灾难恢复计划的一部分,您的 AMS 云架构师会与您合作。
Backup and Restore DR 使用 AMS 自动工具和流程,如下图所示:
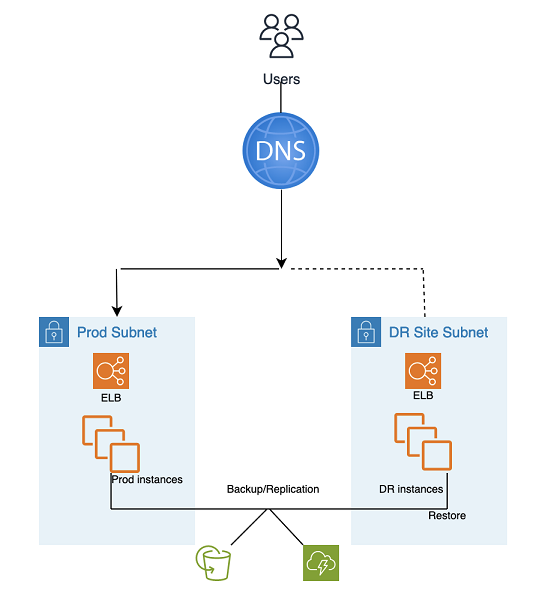
可以使用两种备份和复制方法:
EBS 快照(恢复点目标 (RPO) > 1 小时),被称为 “EBS”
AWS 弹性灾难恢复 (恢复点目标 (RPO) ~ 0.25 小时),被称为 “DRS”
灾难恢复站点可以位于相同或不同位置 AWS 区域。
注意
不同的区域 (Cross-Region) 具有不同的活动目录环境。
DR(故障转移)步骤:
从快照还原实例(两步流程,先使用占位符实例)
更新应用程序配置(新 IP、服务器名称等)
根据需要设置其他基础架构(SG、ELB 等)
将 DNS 重定向到灾难恢复站点 (ELB)
必要时更新或恢复 AD 依赖关系(服务帐号、服务主体名称 (SPN)、组策略对象 (GPO) 等)
Backup 和 Restore 灾难恢复指标:
恢复点目标 (RPO):>1 小时或大约 0.25 小时(取决于所选的解决方案-EBS 或 DRE)
恢复时间目标和 (RTO):约 1 小时(取决于实例数量和编排)
维护:高(在两个环境中都需要同步更改,例如应用程序配置、补丁、安全组或应用程序负载均衡器、证书等。
成本:中等
在 AMS 上使用 EBS 快照为 EC2 提供灾难保护
先决条件:
AMS Prod 着陆区(来源)
AMS DR 着陆区(灾难目标)
已为 EC2 实例启用 EBS 快照 ()AWS Backup
快照复制解决方案:
跨可用区:不适用-根据设计,EBS 快照在该区域内的可用性很高
Cross-Region: AWS Backup
下图显示了 AMS 上从 EBS 快照中恢复 EC2 的过程:
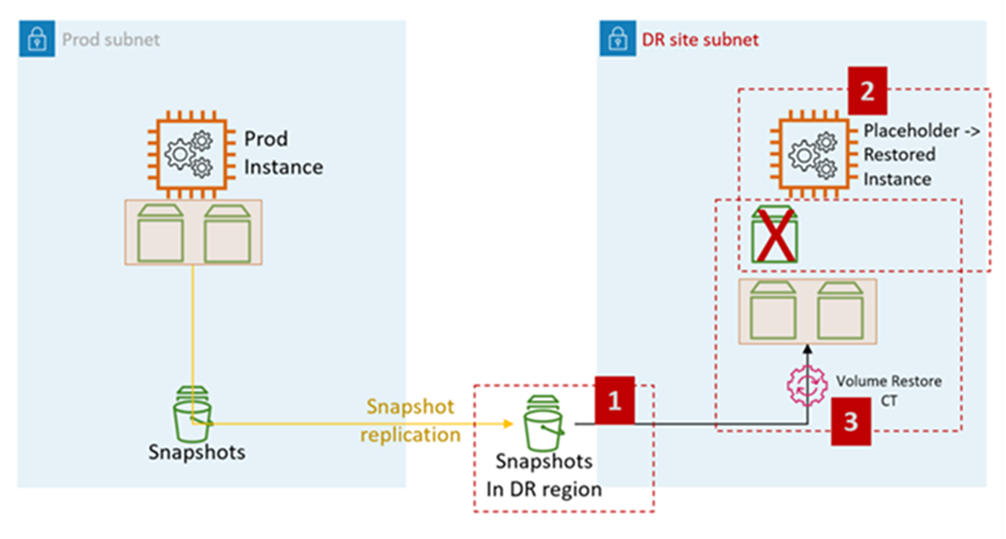
AMS 上的 EC2 灾难恢复步骤:
提出 RFC 以与目标账户共享 EBS 快照( Cross-Region 灾难恢复所必需的)。
: 管理、高级堆栈组件、EBS 快照、共享
在目标子网(灾难恢复站点子网)中创建占位符 EC2 AMS 堆栈。建议使用 CFN 摄取来创建堆栈,因为客户可以在同一个堆栈中组合分配安全组和其他(例如将实例添加到 ELB)的步骤。
更改类型:部署、接收、 CloudFormation 模板堆栈、创建
提高 RFC 以执行 EC2 堆栈卷恢复。
更改类型:管理、高级堆栈组件、EC2 实例堆栈、恢复卷。
CT 从步骤 1 中共享的快照中恢复卷,并连接到步骤 2 中创建的占位符实例。
音量恢复 CT 功能:
关闭占位符实例
从快照恢复卷
换出音量
启动实例
离开旧域名
更改主机名
重新启动。AMS 引导脚本在启动时将实例加入目标 (DR) 域
音量恢复 CT 输入:
InstanceId (占位符实例 ID)
RootDeviceSnapshotId,已恢复的根卷的 EBS 快照
KMSKeyId、KMS 密钥标识符或 ARN,用于加密 EC2 实例上所有已恢复的卷
DeviceNames,最多 25 个(可选)
SnapshotIds,最多 25 个(可选)。要恢复的卷的快照列表
在 AMS 上使用弹性灾难恢复功能为 EC2 提供灾难保护
先决条件:
AMS Prod 着陆区(来源)
AMS DR 着陆区(灾难目标)
您必须先为计划在其中使用的所有 AWS 区域 内容初始化 Elastic 灾难恢复服务。
在您的 DR 着陆区 (LZ) 中创建一个 IAM 角色以访问 Elastic 灾难恢复控制台。
重要:SSM 文档是在 DRS 中作为启动后操作创建的。必须在所有服务器的 PostLaunch 设置中启用此操作。
目标(占位符)实例必须具有标签键:“AWSDRS”,值:“”。AllowLaunchingIntoThisInstance占位符实例必须处于停止状态。否则,AMS 无法在启动设置下选择占位符实例,Elastic 灾难恢复也无法在占位符实例之上进行恢复。
有关 AMS 上的 EC2 的 Elastic 灾难恢复设置和恢复过程的示意图,请参阅 AWS 弹性灾难恢复 (AWS DRS) 通用架构。
在 AMS 上使用弹性灾难恢复的 EC2 灾难恢复步骤:
使用适当的标签在目标子网(灾难恢复站点子网)中创建占位符 EC2 AMS 堆栈,有关更多信息,请参阅上一节。我们建议使用 CFN 摄取来创建堆栈,因为您可以将分配安全组和标记实例、EBS 卷及其他(例如将实例添加到 ELB)的步骤组合到同一个堆栈中。
更改类型:部署、接收、 CloudFormation 模板堆栈、创建
停止占位符实例。
更改类型:管理、高级堆栈组件、EC2 实例、停止
如果未在步骤 1 中完成,请使用密钥:“AWSDRS”,值:“” 标记占位符实例及其 EBS 卷。AllowLaunchingIntoThisInstance
更改类型:管理、高级堆栈组件、标记、更新。
使用步骤 1 中的占位符实例作为源服务器的 “启动到实例 ID”、“DRS 启动设置” 下的目标。从 Elastic 灾难恢复控制台为源服务器启动实例恢复演练。
注意
占位符实例卷保留在账户中。要删除这些卷,请在灾难恢复操作结束时提交管理 | 高级堆栈组件 | EBS 卷 | 删除更改类型 (ct-3e3h8u0sp5z80)。
弹性灾难恢复恢复工作流程:
目标(占位符)实例必须处于停止状态
交换卷并删除源(占位符)根卷
启动实例
运行 “启动后操作” 以完成以下项目:
激活 SSM 代理。
交换卷并删除源(占位符)根卷。
启动实例
运行 PostLaunchScript SSM 文档。本文档执行以下操作:
离开旧域名。
更改主机名。
重新启动。AMS 引导脚本在启动期间将实例加入目标 (DR) 域。
