本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
从 Couchbase 服务器迁移
简介
本指南介绍了从 Couchbase Server 迁移到 Amazon DocumentDB 时需要考虑的要点。它解释了迁移的发现、规划、执行和验证阶段的注意事项。它还说明了如何执行离线和在线迁移。
与亚马逊 DocumentDB 的比较
| Couchbase 服务器 | Amazon DocumentDB | |
|---|---|---|
| 数据组织 | 在 7.0 及更高版本中,数据按存储桶、范围和集合进行组织。在早期版本中,数据被组织到存储桶中。 | 数据被组织成数据库和集合。 |
| 兼容性 | 每项服务(例如数据、索引、搜索等)都有单独 APIs 的服务。二级查找使用 SQL++(以前称为 N1QL);这是一种基于 ANSI 标准 SQL 的查询语言,因此许多开发人员都很熟悉。 | 亚马逊 DocumentDB 与 MongoDB API 兼容。 |
| 架构 | 存储空间已连接到每个集群实例。您不能独立于存储来扩展计算。 | Amazon DocumentDB 专为云而设计,可避免传统数据库架构的限制。计算层和存储层在 Amazon DocumentDB 中是分开的,计算层可以独立于存储进行扩展。 |
| 按需添加读取容量 | 可以通过添加实例来扩展集群。由于存储连接到运行服务的实例,因此横向扩展所需的时间取决于需要移动到新实例或重新平衡的数据量。 | 您可以通过在集群中创建多达 15 个 Amazon DocumentDB 副本来实现对您的 Amazon DocumentDB 集群的读取扩展。对存储层没有影响。 |
| 从节点故障中快速恢复 | 集群具有自动故障转移功能,但是使集群恢复到最大容量所需的时间取决于需要移动到新实例的数据量。 | 无论集群中的数据量如何,Amazon DocumentDB 通常可以在 30 秒内对主集群进行故障转移,并在 8-10 分钟内将集群恢复到最大容量。 |
| 随着数据的增长扩展存储 | 适用于自行管理的集群存储, IOs 不要自动扩展。 | 亚马逊 DocumentDB 存储和自动 IOs 扩展。 |
| 在不影响性能的情况下备份数据 | 备份由备份服务执行,默认情况下不启用。由于存储和计算不是分开的,因此可能会对性能产生影响。 | 默认情况下,Amazon DocumentDB 备份处于启用状态,无法关闭。备份由存储层处理,因此它们对计算层的影响为零。Amazon DocumentDB 支持从集群快照还原和还原到某个时间点。 |
| 数据持久性 | 一个集群中最多可以有 3 个副本数据副本,总共有 4 个副本。运行数据服务的每个实例都将有活动数据副本和 1、2 或 3 个副本副本。 | 无论有多少计算实例,Amazon DocumentDB 都会维护 6 个数据副本,写入法定人数为 4,并保持不变。存储层保存 4 个数据副本后,客户端会收到确认信息。 |
| 一致性 | 支持 K/V 操作的即时一致性。Couchbase SDK 会将 K/V 请求路由到包含数据活动副本的特定实例,因此在确认更新后,可以保证客户端读取该更新。将更新复制到其他服务(索引、搜索、分析、事件)最终是一致的。 | Amazon DocumentDB 副本最终是一致的。如果需要立即读取一致性,则客户端可以从主实例读取。 |
| 复制 | 跨数据中心复制 (XDCR) 在许多:多拓扑中提供经过筛选的、主动-被动/主动-主动的数据复制。 | Amazon DocumentDB 全球集群在 1:多(最多 10 个)拓扑中提供主动-被动复制。 |
Discovery
迁移到 Amazon DocumentDB 需要对现有数据库工作负载有透彻的了解。工作负载发现是分析您的 Couchbase 集群配置和操作特征(数据集、索引和工作负载)的过程,以帮助确保在最小中断的情况下实现无缝过渡。
集群配置
Couchbase 使用以服务为中心的架构,其中每项功能都对应一项服务。对您的 Couchbase 集群执行以下命令以确定正在使用哪些服务(请参阅获取节点信息
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
示例输出:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
Couchbase 服务包括以下内容:
数据服务 (kv)
数据服务提供对内存和磁盘上数据的 read/write 访问。
亚马逊 DocumentDB 支持通过 MongoDB API 对 JSON 数据进行 K/V 操作。
查询服务 (n1ql)
查询服务支持通过 SQL++ 查询 JSON 数据。
亚马逊 DocumentDB 支持通过 MongoDB API 查询 JSON 数据。
索引服务(索引)
索引服务创建和维护数据索引,从而实现更快的查询。
亚马逊 DocumentDB 支持默认主索引和通过 MongoDB API 在 JSON 数据上创建二级索引。
搜索服务 (fts)
搜索服务支持创建用于全文搜索的索引。
Amazon DocumentDB 的原生全文搜索功能允许您通过 MongoDB API 使用特殊用途的文本索引对大型文本数据集执行文本搜索。对于高级搜索用例,Amazon DocumentDB Zero-etl 与亚马逊 OpenSearch 服务的集成
分析服务 (cba)
分析服务支持近乎实时地分析 JSON 数据。
亚马逊 DocumentDB 支持通过 MongoDB API 对 JSON 数据进行临时查询。您还可以使用在亚马逊 EMR 上运行的 Apache Spark 对亚马逊文档数据库中的 JSON 数据进行复杂查询
活动服务(活动)
事件服务执行用户定义的业务逻辑以响应数据更改。
Amazon DocumentDB 通过在您的 Amazon DocumentDB 集群中每次数据发生变化时调用 AWS Lambda 函数来自动执行事件驱动的工作负载。
备份服务(备份)
备份服务计划完整和增量数据备份,并合并以前的数据备份。
Amazon DocumentDB 会持续将您的数据备份到 Amazon S3,保留期为 1-35 天,这样您就可以快速恢复到备份保留期内的任何时间。作为持续备份过程的一部分,Amazon DocumentDB 还会自动拍摄数据快照。您还可以使用管理 Amazon DocumentDB 的备份和恢复
操作特征
使用适用于 Couchbase 的发现工具
数据集
该工具检索以下存储桶、范围和集合信息:
存储桶名称
存储桶类型
作用域名称
集合名称
总大小(字节)
商品总数
项目大小(字节)
索引
该工具检索以下索引统计数据以及所有存储桶的所有索引定义。请注意,不包括主索引,因为 Amazon DocumentDB 会自动为每个集合创建主索引。
存储桶名称
作用域名称
集合名称
索引名
索引大小(字节)
工作负载
该工具检索 K/V 和 N1QL 查询指标。 K/V 指标值在存储桶级别收集,SQL++ 指标在集群级别收集。
工具命令行选项如下所示:
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
以下是一个示例命令:
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
K/V 指标值将基于过去一周每 10 分钟采样一次(参见 HTTP 方法和 URI
collection-stats.csv — 存储桶、范围和集合信息
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv — 索引名称和大小
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv — 获取、设置和删除所有存储桶的指标
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv — SQL++ 为集群选择、删除和插入指标
selects,deletes,inserts 0,132,87
<bucket-name>ind@@ exes-.txt — 存储桶中所有索引的索引定义。请注意,不包括主索引,因为 Amazon DocumentDB 会自动为每个集合创建主索引。
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
规划
在规划阶段,您将确定 Amazon DocumentDB 集群要求以及 Couchbase 存储桶、范围和馆藏与亚马逊文档数据库和馆藏的映射。
亚马逊 DocumentDB 集群要求
使用在发现阶段收集的数据来调整您的 Amazon DocumentDB 集群的大小。有关调整您的 Amazon DocumentDB 集群规模的更多信息,请参阅实例大小调整。
将存储桶、作用域和集合映射到数据库和集合
确定将存在于您的 Amazon DocumentDB 集群中的数据库和馆藏。根据您的 Couchbase 集群中数据的组织方式,考虑以下选项。这些不是唯一的选择,但它们提供了可供您考虑的起点。
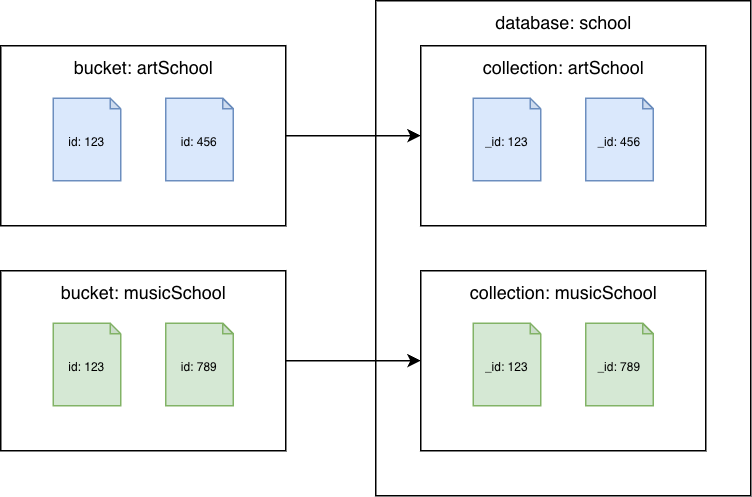
Couchbase Server 6.x 或更早版本
Couchbase 存储到亚马逊 DocumentDB 馆藏中
将每个存储桶迁移到不同的亚马逊文档数据库集合。在这种情况下,Couchbase 文档id值将用作亚马逊 _id DocumentDB 的值。
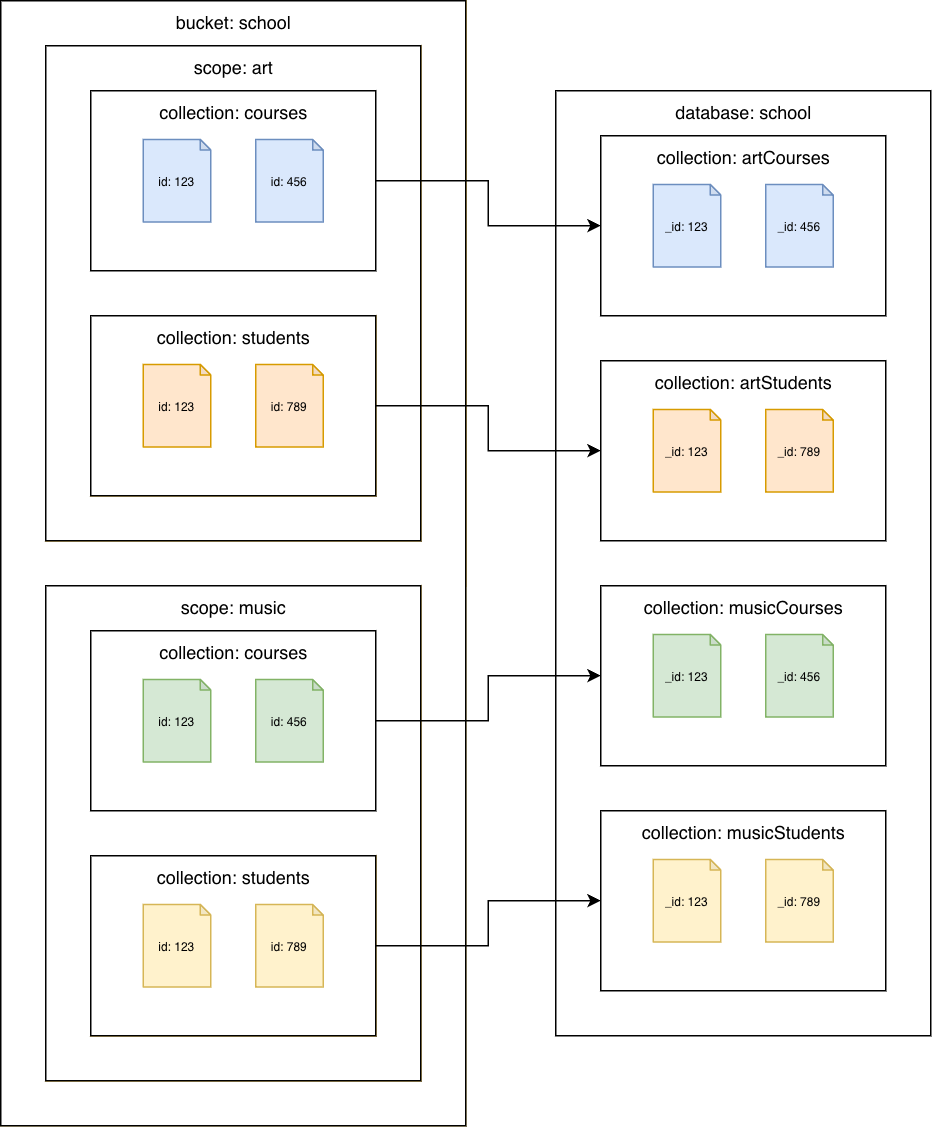
Couchbase Server 7.0 或更高版本
Couchbase 馆藏到亚马逊 DocumentDB 馆藏
将每个馆藏迁移到不同的亚马逊 DocumentDB 馆藏。在这种情况下,Couchbase 文档id值将用作亚马逊 _id DocumentDB 的值。
迁移
索引迁移
迁移到 Amazon DocumentDB 不仅需要传输数据,还需要传输索引,以保持查询性能和优化数据库操作。本节概述了在确保兼容性和效率的同时将索引迁移到 Amazon DocumentDB 的详细 step-by-step过程。
使用 Amazon Q 将 SQL++ CREATE INDEX 语句转换为亚马逊 DocumentDB 命令createIndex()。
上传索引——由 Couchbase 的发现工具创建的.txt <bucket name>文件。
输入以下提示:
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q 将生成等效的亚马逊 DocumentDB 命令createIndex()。请注意,您可能需要根据将 Couchbase 存储桶、范围和集合映射到 Amazon DocumentDB 馆藏的方式来更新馆藏名称。
例如:
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Amazon Q 输出示例(摘录):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
有关 Amazon Q 无法转换的任何索引,请参阅管理 Amazon DocumentDB 索引、索引和索引属性了解更多信息。
重构代码以使用 MongoDB APIs
客户使用 Couchbase 连接 SDKs 到 Couchbase 服务器。亚马逊 DocumentDB 客户端使用 MongoDB 驱动程序连接到亚马逊 DocumentDB。MongoDB 驱动程序也支持 Couchbase SDKs 支持的所有语言。有关适用于您的语言的驱动程序的更多信息,请参阅 MongoDB
APIs 由于 Couchbase Server 和 Amazon DocumentDB 不同,因此您需要重构代码才能使用相应的 MongoDB。 APIs你可以使用 Amazon Q 将 K/V API 调用和 SQL++ 查询转换为等效的 MongoDB: APIs
上传源代码文件。
输入以下提示:
Convert the Couchbase API code to Amazon DocumentDB API code
使用 Hello Couchbase Python
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
有关使用 Python、Node.js、PHP、Go、Java、C#/NET、R 和 Ruby 连接亚马逊文档数据库的示例,请参阅以编程方式连接到亚马逊文档数据库。
选择迁移方法
将数据迁移到 Amazon DocumentDB 时,有两种选择:
离线迁移
在以下情况下,可以考虑离线迁移:
停机时间是可以接受的:离线迁移包括停止对源数据库的写入操作,导出数据,然后将其导入到 Amazon DocumentDB。此过程会导致您的应用程序停机。如果您的应用程序或工作负载可以容忍这段不可用期,那么离线迁移是一个可行的选择。
迁移较小的数据集或进行概念验证:对于较小的数据集,导出和导入过程所需的时间相对较短,这使得离线迁移成为一种快速而简单的方法。它也非常适合开发、测试和停机时间不太重要的 proof-of-concept环境。
简单性是重中之重:使用 cbexport 和 mongoimport 的离线方法通常是迁移数据的最直接方法。它避免了在线迁移方法中涉及的变更数据捕获 (CDC) 的复杂性。
无需复制正在进行的更改:如果源数据库在迁移期间没有主动接收更改,或者如果在迁移过程中捕获这些更改并将其应用于目标数据库并不重要,则可以使用离线方法。
Couchbase Server 6.x 或更早版本
Couchbase 存储桶到亚马逊 DocumentDB 馆藏
使用 cbexport json--format选项,你可以使用lines或list。
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
使用 mongoimport 将数据导入亚马逊文档数据库集合,并使用相应的选项来导入行或列表:
台词:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
清单:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 或更高版本
要执行离线迁移,请使用 cbexport 和 mongoimport 工具:
带有默认范围和默认集合的 Couchbase 存储桶
使用 cbexport json--format选项,你可以使用lines或list。
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
使用 mongoimport 将数据导入亚马逊文档数据库集合,并使用相应的选项来导入行或列表:
台词:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
清单:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase 馆藏到亚马逊 DocumentDB 馆藏
使用 cbexport json 导出数据,为每个--include-data选项导出每个集合。对于该--format选项,你可以使用lines或list。使用--scope-field和--collection-field选项将作用域和集合的名称存储在每个 JSON 文档的指定字段中。
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
由于 cbexport 将_scope和_collection字段添加到每个导出的文档中,因此您可以通过搜索和替换或任何您喜欢的方法将它们从导出文件中的每个文档中删除。sed
使用 mongoimport 将每个馆藏的数据导入到 Amazon Documpor t 集合中,并使用相应的选项来导入行或列表:
台词:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
清单:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
在线迁移
当您需要最大限度地减少停机时间并且需要近乎实时地将正在进行的更改复制到 Amazon DocumentDB 时,可以考虑在线迁移。
请参阅如何执行从 Couchbase 到亚马逊 DocumentDB 的实时迁移,了解如何实时迁移到亚马逊
Couchbase Server 6.x 或更早版本
Couchbase 存储桶到亚马逊 DocumentDB 馆藏
Couchbase 的迁移实用程序document.id.strategy参数配置为使用消息键值作为_id字段值(参见 Sin k 连接器 ID 策略属性
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 或更高版本
带有默认范围和默认集合的 Couchbase 存储桶
Couchbase 的迁移实用程序document.id.strategy参数配置为使用消息键值作为_id字段值(参见 Sin k 连接器 ID 策略属性
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase 馆藏到亚马逊 DocumentDB 馆藏
将源连接器
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
将接收器连接器
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
验证
本节提供了详细的验证流程,用于在迁移到 Amazon DocumentDB 后验证数据的一致性和完整性。无论采用何种迁移方法,验证步骤都适用。
验证目标中是否存在所有集合
Couchbase 来源
选项 1:查询工作台
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
选项 2:cbq 工具
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Amazon DocumentDB 目标
mongosh(参见 Connect 连接到你的亚马逊 DocumentDB 集群):
db.getSiblingDB('<database>') db.getCollectionNames()
验证源群集和目标群集之间的文档数量
Couchbase 来源
Couchbase Server 6.x 或更早版本
选项 1:查询工作台
SELECT COUNT(*) FROM `<bucket>`
选项 2:cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 或更高版本
选项 1:查询工作台
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
选项 2:cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB 目标
mongosh(参见 Connect 连接到你的亚马逊 DocumentDB 集群):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
比较源群集和目标群集之间的文档
Couchbase 来源
Couchbase Server 6.x 或更早版本
选项 1:查询工作台
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
选项 2:cbq
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 或更高版本
选项 1:查询工作台
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
选项 2:cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB 目标
mongosh(参见 Connect 连接到你的亚马逊 DocumentDB 集群):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
