AWS Data Pipeline 不再向新客户提供。的现有客户 AWS Data Pipeline 可以继续照常使用该服务。了解详情
本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用命令行启动集群
如果您定期运行 Amazon EMR 集群来分析网络日志或分析科学数据,则可以使用 AWS Data Pipeline 来管理您的 Amazon EMR 集群。使用 AWS Data Pipeline,您可以指定在启动集群之前必须满足的先决条件(例如,确保将今天的数据上传到 Amazon S3)。本教程将引导您完成启动集群的过程,该集群可以是基于 Amazon EMR 的简单管道的模型,也可以是更相关的管道的一部分。
先决条件
必须先完成以下步骤,然后才能使用 CLI:
-
安装和配置命令行界面(CLI)。有关更多信息,请参阅 正在访问 AWS Data Pipeline。
-
确保 IAM 角色已命名DataPipelineDefaultRole且DataPipelineDefaultResourceRole存在。 AWS Data Pipeline 控制台会自动为您创建这些角色。如果您至少没有使用过 AWS Data Pipeline 控制台,则必须手动创建这些角色。有关更多信息,请参阅 适用的 IAM 角色 AWS Data Pipeline。
创建管道定义文件
以下代码是简单 Amazon EMR 集群的管道定义文件,该集群运行由 Amazon EMR 提供的现有 Hadoop 流式处理作业。此示例应用程序被调用 WordCount,您也可以使用 Amazon EMR 控制台运行它。
将此代码复制到一个文本文件中并将其另存为 MyEmrPipelineDefinition.json。您应将 Amazon S3 存储桶位置替换为您拥有的 Amazon S3 存储桶的名称。您还应替换开始日期和结束日期。要立即启动集群,startDateTime请设置为过去某一天的日期和endDateTime将来的某一天。 AWS Data Pipeline 然后立即开始启动 “逾期” 集群,试图解决它所认为的工作积压问题。这种回填意味着你不必等一个小时就能看到它的第一个集群 AWS Data Pipeline 启动。
{ "objects": [ { "id": "Hourly", "type": "Schedule", "startDateTime": "2012-11-19T07:48:00", "endDateTime": "2012-11-21T07:48:00", "period": "1 hours" }, { "id": "MyCluster", "type": "EmrCluster", "masterInstanceType": "m1.small", "schedule": { "ref": "Hourly" } }, { "id": "MyEmrActivity", "type": "EmrActivity", "schedule": { "ref": "Hourly" }, "runsOn": { "ref": "MyCluster" }, "step": "/home/hadoop/contrib/streaming/hadoop-streaming.jar,-input,s3n://elasticmapreduce/samples/wordcount/input,-output,s3://myawsbucket/wordcount/output/#{@scheduledStartTime},-mapper,s3n://elasticmapreduce/samples/wordcount/wordSplitter.py,-reducer,aggregate" } ] }
此管道有三个对象:
-
Hourly,表示工作的计划。您可以将计划设置为活动上的字段之一。在执行此操作时,该活动将根据计划运行或 (在此示例中) 每小时运行一次。 -
MyCluster,表示用于运行集群的 Amazon EC2 实例组。您可以指定要作为集群运行的 EC2 实例的大小和数目。如果您不指定实例数,则集群在启动时有两个节点:一个主节点和一个任务节点。您可以指定要在其中启动集群的子网。您可以向集群添加其他配置,例如,用于将其他软件加载到由 Amazon EMR 提供的 AMI 上的引导操作。 -
MyEmrActivity,表示要使用集群处理的计算。Amazon EMR 支持多种类型的集群,包括流式处理、级联和脚本化 Hive。该runsOn字段引用回 MyCluster来,将其用作集群基础的规范。
上传并激活管道定义
您必须上传您的管道定义并激活您的管道。在以下示例命令中,pipeline_name替换为管道的标签和pipeline_file管道定义.json文件的完全限定路径。
AWS CLI
要创建管道定义并激活管道,请使用以下 create-pipeline 命令。记下您的管道 ID,因为您将在大多数 CLI 命令中使用这个值。
aws datapipeline create-pipeline --name{ "pipelineId": "df-00627471SOVYZEXAMPLE" }pipeline_name--unique-idtoken
要上传您的管道定义,请使用以下put-pipeline-definition命令。
aws datapipeline put-pipeline-definition --pipeline-id df-00627471SOVYZEXAMPLE --pipeline-definition file://MyEmrPipelineDefinition.json
如果您的管道成功验证,则 validationErrors 字段为空。您应该查看所有警告。
要激活管道,请使用以下 activate-pipeline 命令。
aws datapipeline activate-pipeline --pipeline-id df-00627471SOVYZEXAMPLE
您可以使用以下 list-pipelines 命令来验证您的管道是否出现在管道列表中。
aws datapipeline list-pipelines
监控管道运行
您可以 AWS Data Pipeline 使用 Amazon EMR 控制台查看启动的集群,也可以使用 Amazon S3 控制台查看输出文件夹。
要查看由启动的集群的进度 AWS Data Pipeline
-
打开 Amazon EMR 控制台。
-
生成的集群 AWS Data Pipeline 的名称格式如下:
<pipeline-identifier>_@ _<emr-cluster-name>。<launch-time>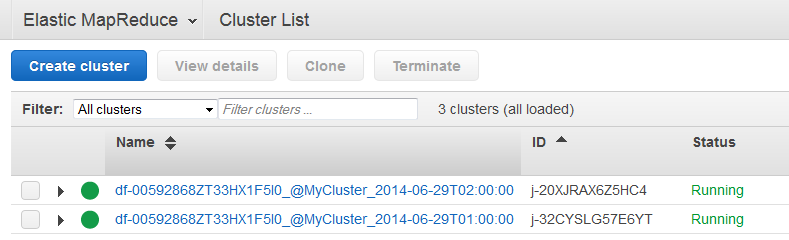
-
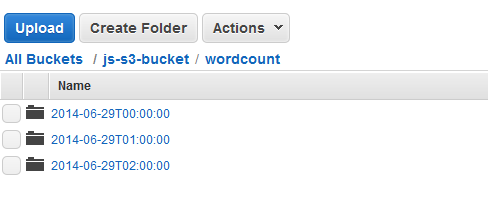
在某个运行完成后,请打开 Amazon S3 控制台并检查带时间戳的输出文件夹是否存在并且包含集群的预期结果。