本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Braket Hybrid Jobs
Amazon Braket Hybrid Jobs 为您提供了一种运行混合量子经典算法的方法,需要经典 AWS 资源和量子处理单元 (QPU)。Hybrid Jobs 旨在启动请求的经典资源,运行您的算法,并在完成后释放实例,因此您只需为实际使用的资源付费。
Hybrid Jobs 非常适合长期运行的迭代算法,这些算法涉及使用经典计算资源和量子计算资源。使用 Hybrid Jobs 提交算法运行后,Braket 将在可扩展的容器化环境中运行您的算法。算法完成后,您就可以检索结果了。
此外,通过混合作业创建的量子任务受益于更高的优先级排队到目标 QPU 设备。这种优先级划分可确保您的量子计算在队列中等待的其他任务之前得到处理和运行。这对于迭代混合算法尤其有利,在迭代混合算法中,一项量子任务的结果取决于先前量子任务的结果。此类算法的示例包括量子近似优化算法(QAOA)
您可以使用以下方式在 Braket 中访问混合作业:
-
Amazon Braket API。
本节内容:
何时使用 Amazon Braket Hybrid Jobs
Amazon Braket Hybrid Jobs 可运行混合量子经典算法,如变分量子特征求解器(VQE)和量子近似优化算法(QAOA),它们将经典计算资源与量子计算设备相结合,以优化当今量子系统的性能。Amazon Braket Hybrid Jobs 有三个主要好处:
-
性能:与在您自己的环境中运行混合算法相比,Amazon Braket Hybrid Jobs 的性能更佳。当您的作业正在运行时,它可以优先访问选定的目标 QPU。您的任务比设备上排队的其他任务之前运行的时间要早。由此,混合算法的运行时更短、更具可预测性。Amazon Braket Hybrid Jobs 还支持参数化编译。您可以使用免费参数提交电路。Braket 只需编译一次电路,无需重新编译即可对同一电路进行后续参数更新,从而实现更快的运行时。
-
便利:Amazon Braket Hybrid Jobs 简化了计算环境的设置和管理,并在混合算法运行时保持其运行。您只需提供算法脚本,然后选择要运行的量子设备(量子处理单元或模拟器)即可。Amazon Braket 等待目标设备可用,启动传统资源,在预先构建的容器环境中运行工作负载,将结果返回到 Amazon Simple Storage Service (Amazon S3),然后释放计算资源。
-
指标:Amazon Braket Hybrid Jobs 提供有关运行算法的即时见解,并近乎实时地向亚马逊 CloudWatch 和 Amazon Braket 控制台提供可自定义的算法指标,以便您可以跟踪算法的进度。
使用 Amazon Braket Hybrid Jobs 运行混合作业
要使用 Amazon Braket Hybrid Jobs 运行混合作业,您首先需要定义算法。您可以通过使用 Amazon Braket Python 软件开发工具包编写算法脚本以及其他依赖项文件来定义它,也可以使用 Amazon Braket Python SDK 或
无论哪种情况,接下来都要使用 Amazon Braket API 创建混合作业,在其中提供算法脚本或容器,选择混合作业要使用的目标量子设备,然后从各种可选设置中进行选择。为这些可选设置提供的默认值适用于大多数使用案例。对于运行混合作业的目标设备,您可以在 QPU、按需模拟器(如 SV1、DM1 或 TN1)或经典混合作业实例本身之间进行选择。使用按需模拟器或 QPU,您的混合作业容器可以对远程设备进行 API 调用。使用嵌入式模拟器,模拟器与算法脚本嵌入在同一个容器中。中的闪电模拟 PennyLane 器
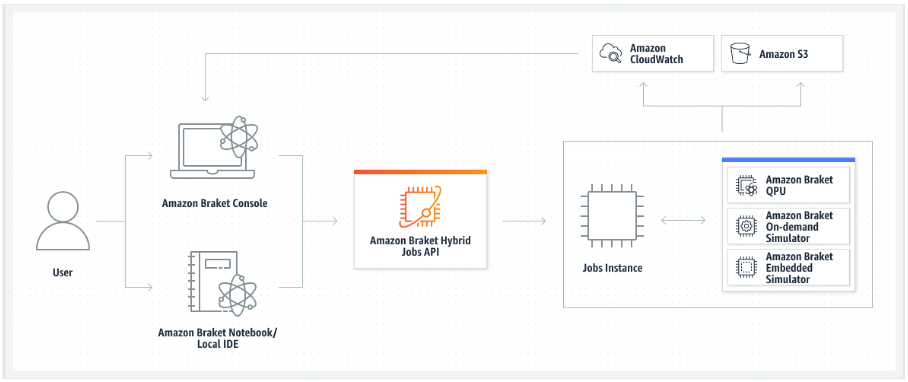
如果您的目标设备是按需模拟器或嵌入式模拟器,Amazon Braket 会立即开始运行混合任务。它启动混合作业实例(您可以在 API 调用中自定义实例类型),运行算法,将结果写入 Amazon S3,然后释放您的资源。此资源版本可确保您只需按实际使用量付费。
每个量子处理单元(QPU)的并发混合任务总数受到限制。如今,在任何给定时间,QPU 上只能运行一个混合作业。队列用于控制可运行的混合作业的数量,以免超过规定的限制。如果您的目标设备是 QPU,则混合作业将首先进入所选 QPU 的作业队列。Amazon Braket 启动所需的混合作业实例,并在设备上运行您的混合作业。在算法持续时间内,您的混合作业具有优先访问权限,这意味着混合作业中的量子任务优先于设备上排队的其他 Braket 量子任务,前提是该作业的量子任务每隔几分钟提交给 QPU 一次。混合作业完成后,资源就会被释放,这意味着您只需按实际使用量付费。
注意
设备是区域性的,您的混合任务与主设备在 AWS 区域 同一设备上运行。
在模拟器和 QPU 目标场景中,您可以选择将自定义算法指标(如哈密顿量)定义为算法的一部分。这些指标会自动报告给亚马逊, CloudWatch 然后在亚马逊Braket控制台中以近乎实时的方式显示。
注意
如果您想使用基于 GPU 的实例,请务必使用 Braket 上嵌入式模拟器中可用的模拟器之一(例如)。 GPU-based lightning.gpu如果您选择其中一个 CPU-based 嵌入式模拟器(例如lightning.qubit、或braket:default-simulator),则不会使用 GPU,并且可能会产生不必要的成本。
