本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
创建混合作业
本节将向您介绍如何使用 Python 脚本创建混合作业。或者,要使用本地 Python 代码 [例如您首选的集成式开发环境(IDE)或 Braket Notebook] 创建混合作业,请参阅 将本地代码作为混合作业运行。
创建并运行
拥有运行混合作业权限的角色后,就可以继续操作了。您的第一个 Braket 混合作业的关键部分是算法脚本。它定义了您要运行的算法,并包含作为算法一部分的经典逻辑和量子任务。除算法脚本外,还可以提供其他依赖关系文件。算法脚本及其依赖关系被称为源模块。入口点定义了混合作业启动时要在源模块中运行的第一个文件或函数。
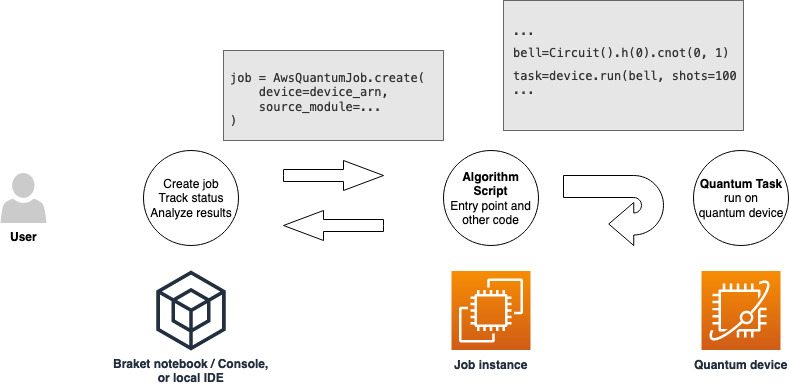
首先,考虑以下算法脚本的基本示例,该脚本创建了五个钟形状态并打印相应的测量结果。
import os from braket.aws import AwsDevice from braket.circuits import Circuit def start_here(): print("Test job started!") # Use the device declared in the job script device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test job completed!")
将此文件名为 algorithm_script.py 的文件保存在 Braket Notebook 或本地环境的当前工作目录中。algorithm_script.py 文件已将 start_here() 作为计划的入口点。
接下来,在与 algorithm_script.py 文件相同的目录下创建 Python 文件或 Python Notebook。此脚本启动混合作业并处理任何异步处理,例如打印我们感兴趣的状态或关键结果。此脚本至少需要指定您的混合作业脚本和主设备。
注意
有关如何创建 Braket Notebook 或将文件(如 algorithm_script.py 文件)上传到与 Notebook 相同的目录中的更多信息,请参阅使用 Amazon Braket Python SDK 运行您的第一个电路
对于基本的第一种情况,您的目标是模拟器。无论您瞄准的是哪种类型的量子设备,无论是模拟器还是实际的量子处理单元(QPU),您在以下脚本 device 中指定的设备都用于调度混合作业,并且可以作为环境变量 AMZN_BRAKET_DEVICE_ARN 提供给算法脚本。
注意
您只能使用混合作业中 AWS 区域 可用的设备。Amazon Braket SDK 会自动选择此 AWS 区域。例如,us-east-1 中的混合作业可以IonQ使用SV1、DM1和设备,但不能使用设备。Rigetti
如果您选择量子计算机而不是模拟器,Braket 会安排您的混合作业,以优先访问权限运行其所有量子任务。
from braket.aws import AwsQuantumJob from braket.devices import Devices job = AwsQuantumJob.create( Devices.Amazon.SV1, source_module="algorithm_script.py", entry_point="algorithm_script:start_here", wait_until_complete=True )
参数 wait_until_complete=True 设置了详细模式,以便您的作业在运行时打印实际作业的输出。您应该可以看到类似于以下示例的输出。
Initializing Braket Job: arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 Job queue position: 1 Job queue position: 1 Job queue position: 1 .............. . . . Beginning Setup Checking for Additional Requirements Additional Requirements Check Finished Running Code As Process Test job started! Counter({'00': 58, '11': 42}) Counter({'00': 55, '11': 45}) Counter({'11': 51, '00': 49}) Counter({'00': 56, '11': 44}) Counter({'11': 56, '00': 44}) Test job completed! Code Run Finished 2025-09-24 23:13:40,962 sagemaker-training-toolkit INFO Reporting training SUCCESS
注意
您还可以通过传递自定义模块的位置(本地目录或文件的路径或 tar.gz 文件的 S3 URI)来使用该AwsQuantumJob.create
监控结果
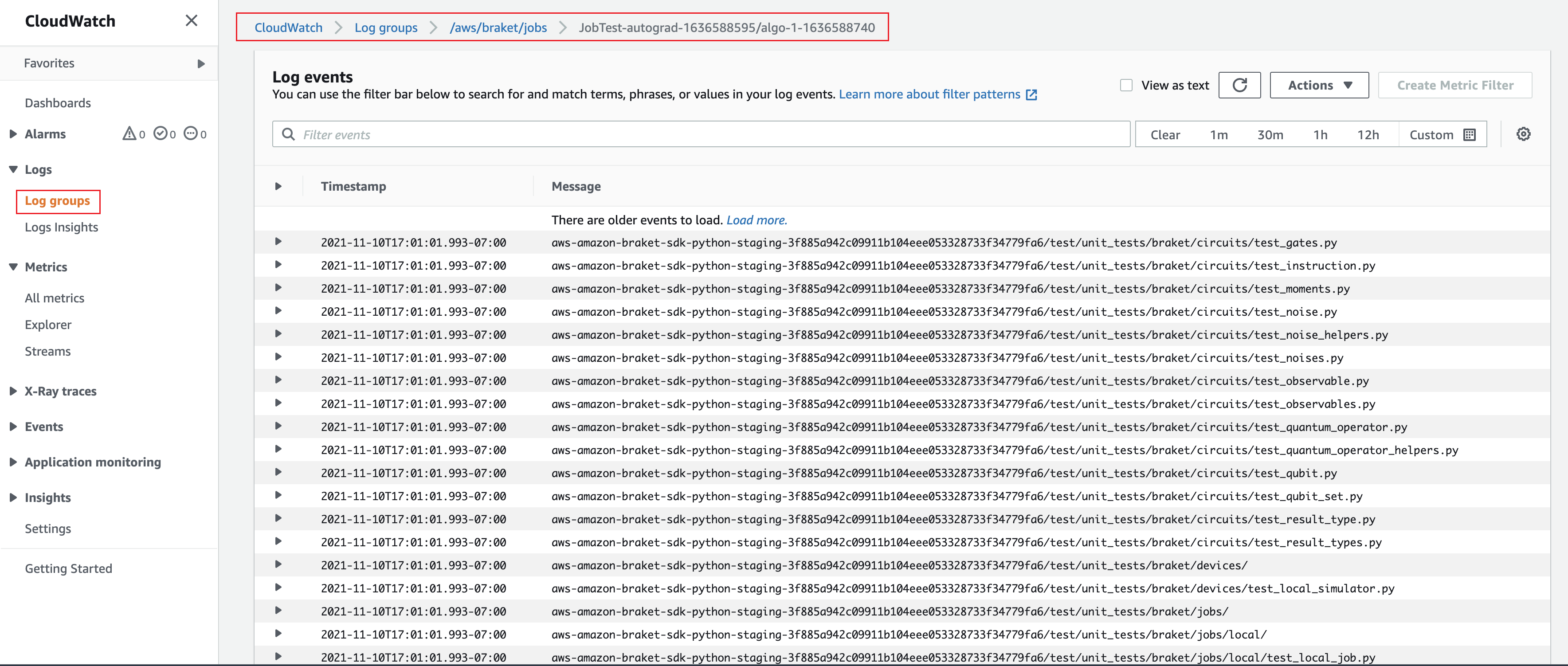
或者,您可以访问来自 Amazon 的日志输出 CloudWatch。为此,请转到作业详细信息页面左侧菜单上的“日志组”选项卡,选择“日志组 aws/braket/jobs”,然后选择包含该作业名称的日志流。在上述示例中,即为 braket-job-default-1631915042705/algo-1-1631915190。
您还可以在控制台中查看混合作业的状态,方法是选择“混合作业”页面,然后选择“设置”。
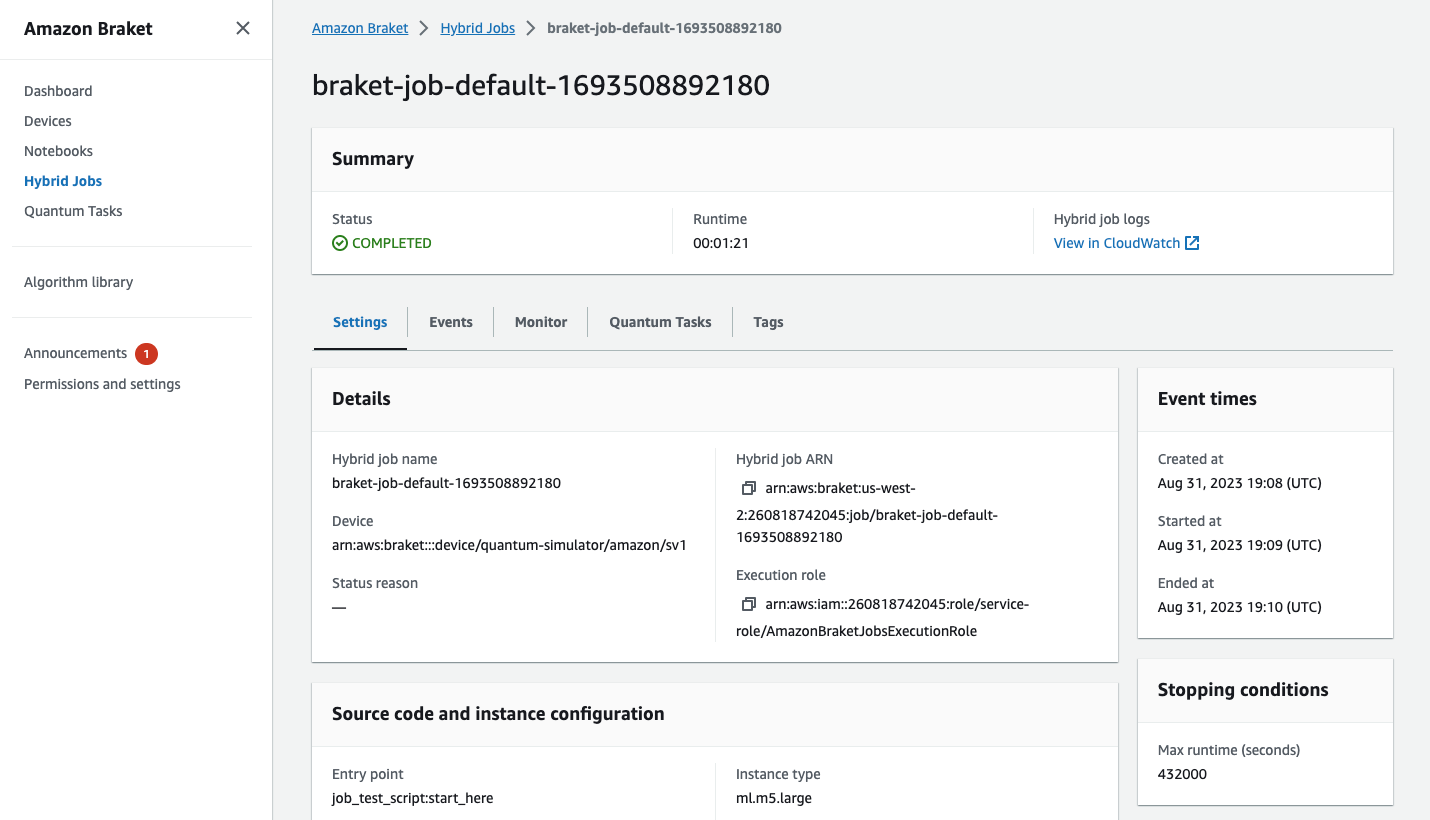
您的混合作业在运行时会在 Amazon S3 中生成一些构件。S3 存储桶的默认名称为 amazon-braket-<region>-<accountid> 且内容位于 jobs/<jobname>/<timestamp> 目录中。使用 Braket Python SDK 创建混合作业时,您可以通过指定其他 code_location来配置存储这些构件的 S3 位置。
注意
此 S3 存储桶必须与您的任务脚本位于同一 AWS 区域 位置。
该 jobs/<jobname>/<timestamp> 目录包含一个子文件夹,model.tar.gz 文件中包含入口点脚本的输出。还有一个名为 script 的目录,包含了 source.tar.gz 文件中您的算法脚本构件。实际量子任务的结果位于名为 jobs/<jobname>/tasks 的目录中。
保存结果
您可以保存算法脚本生成的结果,以便从混合作业脚本中的混合作业对象以及 Amazon S3 的输出文件夹(名为 model.tar.gz 的 tar 压缩文件中)获得这些结果。
输出必须使用 JavaScript 对象表示法 (JSON) 格式保存在文件中。如果数据无法轻易序列化为文本(如 numpy 数组),则可以传入一个使用腌制数据格式进行序列化的选项。有关更多详细信息,请参阅 t.jobs.data_persistence
要保存混合作业的结果,请将以下用 #ADD 注释的行添加到 algorithm_script.py 文件中。
import os from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_result # ADD def start_here(): print("Test job started!") device = AwsDevice(os.environ['AMZN_BRAKET_DEVICE_ARN']) results = [] # ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) results.append(task.result().measurement_counts) # ADD save_job_result({"measurement_counts": results}) # ADD print("Test job completed!")
然后,您可以通过附加带有 #ADD 注释的行 print(job.result()) 来显示作业脚本中的作业结果。
import time from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="algorithm_script.py", entry_point="algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", ) print(job.arn) while job.state() not in AwsQuantumJob.TERMINAL_STATES: print(job.state()) time.sleep(10) print(job.state()) print(job.result()) # ADD
在此示例中,我们移除了 wait_until_complete=True,以抑制冗余输出。您可以将其重新添加以进行调试。当您运行该混合作业时,它会每隔 10 秒输出一次标识符和 job-arn,然后输出混合作业的状态,直到混合作业的状态为 COMPLETED 为止,然后它会向您显示钟形回路的结果。请参阅以下示例。
arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 INITIALIZED RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING ... RUNNING RUNNING COMPLETED {'measurement_counts': [{'11': 53, '00': 47},..., {'00': 51, '11': 49}]}
使用检查点
您可以使用检查点保存混合作业的中间迭代。在上一节的算法脚本示例中,您添加了以下用 #ADD 注释的行来创建检查点文件。
from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_checkpoint # ADD import os def start_here(): print("Test job starts!") device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) # ADD the following code job_name = os.environ["AMZN_BRAKET_JOB_NAME"] save_job_checkpoint(checkpoint_data={"data": f"data for checkpoint from {job_name}"}, checkpoint_file_suffix="checkpoint-1") # End of ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test hybrid job completed!")
当您运行混合作业时,它会在检查点目录中的混合作业构件中使用默认 /opt/jobs/checkpoints 路径创建文件 <jobname>-checkpoint-1.json。除非您要更改此默认路径,否则混合作业脚本保持不变。
如果要从之前的混合作业生成的检查点加载混合作业,则算法脚本会使用 from braket.jobs import load_job_checkpoint。加载到算法脚本中的逻辑如下所示。
from braket.jobs import load_job_checkpoint checkpoint_1 = load_job_checkpoint( "previous_job_name", checkpoint_file_suffix="checkpoint-1", )
加载此检查点后,您可以根据加载到 checkpoint-1 的内容继续执行逻辑。
注意
checkpoint_file_suffix 必须与之前在创建检查点时指定的后缀匹配。
您的编排脚本需要指定前一个混合作业中的 job-arn,该行用 #ADD 注释。
from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="source_dir", entry_point="source_dir.algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", copy_checkpoints_from_job="<previous-job-ARN>", #ADD )
