本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon MQ for RabbitMQ 中性能优化与效率的最佳实践
您可通过最大化吞吐量、最小化延迟及确保高效资源利用来优化 Amazon MQ for RabbitMQ 代理性能。请完成以下最佳实践以优化应用程序性能。
步骤 1:保持消息大小低于 1 MB
我们建议将消息保持在 1 兆字节(MB)以下以获得最佳性能和可靠性。
RabbitMQ 3.13 默认支持高达 128 MB 的消息大小,但大消息可能触发不可预测的内存警报,从而阻塞发布操作,并在跨节点复制消息时可能产生高内存压力。过大的消息还会影响代理重启和恢复过程,这会增加服务连续性的风险并可能导致性能下降。
使用认领检查模式存储和检索大有效载荷
为管理大消息,您可通过将消息有效载荷存储在外部存储中,并仅通过 RabbitMQ 发送有效载荷引用标识符来实现认领检查模式。消费者使用有效载荷引用标识符来检索和处理大消息。
下图演示了如何使用 Amazon MQ for RabbitMQ 和 Amazon S3 实现认领检查模式。
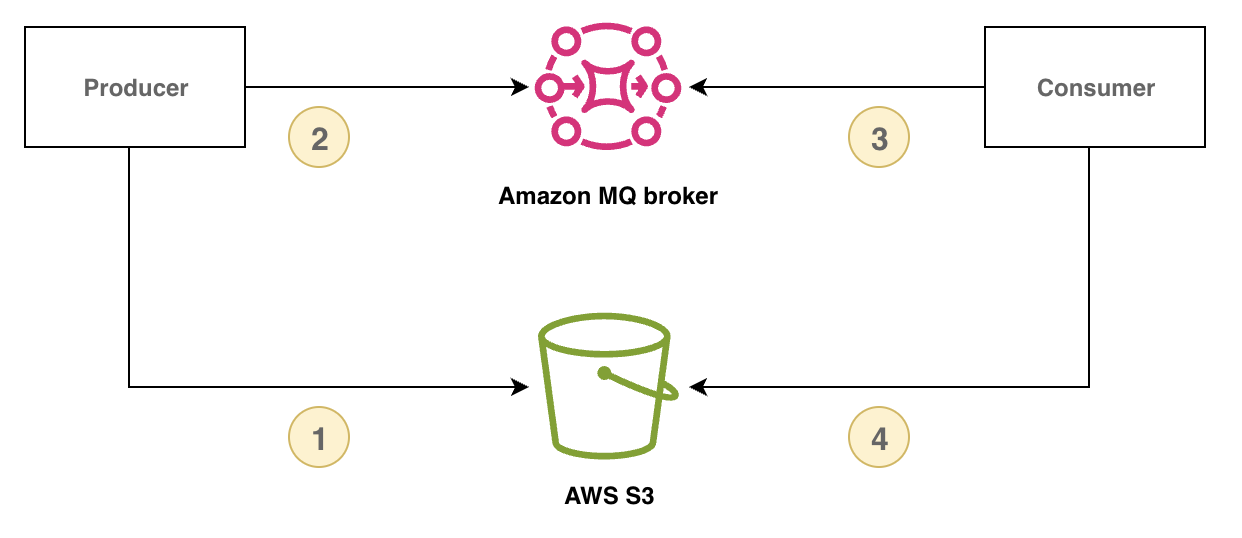
以下示例使用 Amazon MQ、AWS SDK for Java 2.x 和 Amazon S3 演示此模式:
-
首先,定义一个用于存储 Amazon S3 引用标识符的 Message 类。
class Message { // Other data fields of the message... public String s3Key; public String s3Bucket; } -
创建一个发布者方法,将有效载荷存储在 Amazon S3 中并通过 RabbitMQ 发送引用消息。
public void publishPayload() { // Store the payload in S3. String payload = PAYLOAD; String prefix = S3_KEY_PREFIX; String s3Key = prefix + "/" + UUID.randomUUID(); s3Client.putObject(PutObjectRequest.builder() .bucket(S3_BUCKET).key(s3Key).build(), RequestBody.fromString(payload)); // Send the reference through RabbitMQ. Message message = new Message(); message.s3Key = s3Key; message.s3Bucket = S3_BUCKET; // Assign values to other fields in your message instance. publishMessage(message); } -
实现一个消费者方法,从 Amazon S3 检索有效载荷、处理有效载荷并删除 Amazon S3 对象。
public void consumeMessage(Message message) { // Retrieve the payload from S3. String payload = s3Client.getObjectAsBytes(GetObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()) .asUtf8String(); // Process the complete message. processPayload(message, payload); // Delete the S3 object. s3Client.deleteObject(DeleteObjectRequest.builder() .bucket(message.s3Bucket).key(message.s3Key).build()); }
步骤 2:使用 basic.consume 和长生命周期消费者
使用 basic.consume 配合长生命周期消费者比使用 basic.get 轮询单个消息更高效。更多信息,请参阅轮询单个消息
步骤 3:配置预取
您可以使用 RabbitMQ 预提取值来优化使用者使用消息的方式。RabbitMQ 通过将预提取计数应用于使用者而不是通道,实现 AMQP 0-9-1 提供的通道预提取机制。预提取值用于指定在任何给定时间向使用者发送的消息数量。默认情况下,RabbitMQ 会为客户端应用程序设置无限制的缓冲区大小。
在为您的 RabbitMQ 使用者设置预提取计数时,需要考虑各种因素。首先,考虑使用者的环境和配置。由于使用者需要在处理消息时将所有消息保存在内存中,因此,较高的预提取值可能会对使用者的性能产生负面影响,在某些情况下,可能会导致使用者同时崩溃。同样,RabbitMQ 代理本身会将其发送的所有消息缓存在内存中,直到收到使用者确认。如果没有为使用者配置自动确认,并且使用者需要相对较长的时间来处理消息,则较高的预提取值可能会导致 RabbitMQ 服务器内存不足。
考虑到上述因素,我们建议始终设置预提取值,以防止由于大量未处理或未确认的消息而导致 RabbitMQ 代理或其使用者出现内存不足的情况。如果您需要优化代理来处理大量消息,您可以使用一系列预提取计数来测试您的代理和使用者,以确定与使用者处理消息所需的时间相比,网络开销在哪个点上变得微不足道。
注意
如果您的客户端应用程序已配置为自动确认将消息传递给使用者,则设置预提取值将不起作用。
所有预提取消息都会从队列中删除。
以下示例演示了如何使用 RabbitMQ Java 客户端库为单一使用者设置 10 的预提取值。
ConnectionFactory factory = new ConnectionFactory(); Connection connection = factory.newConnection(); Channel channel = connection.createChannel(); channel.basicQos(10, false); QueueingConsumer consumer = new QueueingConsumer(channel); channel.basicConsume("my_queue", false, consumer);
注意
在 RabbitMQ Java 客户端库中,global 标志的默认值设置为 false,所以上面的例子可以简单地写成 channel.basicQos(10)。
步骤 4:将 Celery 5.5 或更高版本与法定队列结合使用
Python Celery
对于所有 Celery 版本
-
关闭
task_create_missing_queues以减轻队列抖动。 -
然后关闭
worker_enable_remote_control以停止动态创建celery@...pidbox队列。这将减少代理上的队列抖动。worker_enable_remote_control = false -
要进一步减少非关键消息活动,请在启动 Celery 应用程序时worker-send-task-events
通过不包含 -E或--task-events标记来关闭 Celery。 -
使用以下参数启动 Celery 应用程序:
celery -A app_name worker --without-heartbeat --without-gossip --without-mingle
对于 Celery 5.5 及以上版本
-
升级到 Celery 5.5 版本
(支持法定队列的最低版本)或更高版本。要检查您使用的 Celery 版本,请使用 celery --version。有关法定队列的更多信息,请参阅 RabbitMQ on Amazon MQ 的仲裁队列。 -
升级到 Celery 5.5 或更高版本后,将
task_default_queue_type配置为 "quorum"。 -
然后,您还必须在代理传输选项
中开启发布确认: broker_transport_options = {"confirm_publish": True}
