本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
将 ETL 流程转换为 in AWS Glue AWS Schema Conversion Tool
接下来,您可以找到将 ETL 脚本转换为 AWS Glue 的 AWS SCT过程大纲。在本示例中,我们将 Oracle 数据库转换为 Amazon Redshift,并将 ETL 过程与源数据库和数据仓库结合使用。
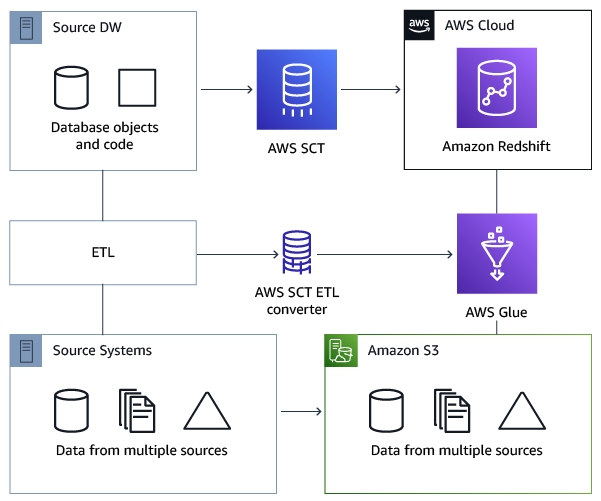
以下架构图显示了一个示例数据库迁移项目,其中包括将 ETL 脚本转换为 AWS Glue。
先决条件
开始之前,请执行以下操作:
-
迁移您打算迁移到 AWS的任何源数据库。
-
将目标数据仓库迁移到 AWS。
-
收集 ETL 过程中涉及的所有代码的列表。
-
收集每个数据库的所有必要连接信息的列表。
此外,还 AWS Glue 需要代表您访问其他 AWS 资源的权限。您可以使用 AWS Identity and Access Management (IAM) 提供这些权限。请确保您已为创建了 IAM 策略 AWS Glue。有关更多信息,请参阅开发人员指南中的为 AWS Glueservice 创建 IAM 策略。AWS Glue
了解 AWS Glue 数据目录
作为转换过程的一部分, AWS Glue 加载有关源数据库和目标数据库的信息。它将这些信息分成不同的类别,并采用称为 树的结构。此结构包括以下内容:
-
连接:连接参数
-
爬网程序:爬网程序的列表,每个架构对应一个爬网程序
-
数据库:容纳表的容器
-
表:表示表中数据的元数据定义
-
ETL 作业:执行 ETL 工作的业务逻辑
-
触发器 — 控制 ETL 作业何时运行的逻辑 AWS Glue (无论是按需、按计划还是由作业事件触发)
AWS Glue 数据目录 是数据的位置、架构和运行时指标的索引。使用 AWS Glue 和时 AWS SCT, AWS Glue 数据目录包含对用作中 ETL 任务源和目标的数据的引用。 AWS Glue要创建数据仓库,请编录该数据。
您可以使用数据目录中的信息创建和监控您的 ETL 作业。通常,您运行爬网程序来清点数据存储中的数据,但还有其他方法可以将元数据表添加到数据目录中。
当您在数据目录中定义表时,您将其添加到数据库中。数据库用于组织中的表 AWS Glue。
使用with进行转换 AWS SCT 的限制 AWS Glue
使用with进行 AWS SCT 转换时,存在以下限制 AWS Glue。
| 资源 | 默认限制 |
| 每个账户的数据库数量 | 10000 |
| 每个数据库的表数量 | 100000 |
| 每个表的分区数量 | 1000000 |
| 每个表的表版本数量 | 100000 |
| 每个账户的表数量 | 1000000 |
| 每个账户的分区数量 | 10,000,000 |
| 每个账户的表版本数量 | 1000000 |
| 每个账户的连接数量 | 1000 |
| 每个账户的爬网程序数量 | 25 |
| 每个账户的作业数量 | 25 |
| 每个账户的触发器数量 | 25 |
| 每个账户的并发作业运行数量 | 30 |
| 每个作业的并发作业运行数量 | 3 |
| 每个触发器的作业数量 | 10 |
| 每个账户的开发端点数量 | 5 |
| 开发端点一次使用的最大数据处理单元 (DPUs) | 5 |
| 一个角色一次 DPUs 使用的最大值 | 100 |
| 数据库名称长度 |
无限制 为了与其他元数据存储(如 Apache Hive)兼容,名称会更改为使用小写字符。 如果您计划从 Amazon Athena 访问数据库,请提供只包含字母数字和下划线字符的名称。 |
| 连接名称长度 | 无限制 |
| 爬网程序名称长度 | 无限制 |
步骤 1:创建新项目
要创建新项目,请执行以下简要步骤:
-
在中创建新项目 AWS SCT。有关更多信息,请参阅 在中启动和管理项目 AWS SCT。
-
将源数据库和目标数据库添加到项目中。有关更多信息,请参阅 将服务器添加到项目中 AWS SCT。
确保已在目标数据库连接设置中选择了使用 AWS Glue。为此,请选择 AWS Glue 选项卡。在 “从 AWS 配置文件复制” 中,选择要使用的配置文件。配置文件应自动填写 AWS 访问密钥、密钥和 Amazon S3 存储桶文件夹。如果不是这样,请自行输入这些信息。选择 “确定” 后, AWS Glue 分析对象并将元数据加载到 AWS Glue 数据目录中。
根据您的安全设置,您可能会收到一条警告消息,指出您的账户对服务器上的某些架构没有足够的权限。如果您有权访问您使用的架构,您可以安全地忽略此消息。
-
要完成准备导入您的 ETL,请连接到源数据库和目标数据库。为此,请在源元数据树或目标元数据树中选择您的数据库,然后选择连接到服务器。
AWS Glue 在源数据库服务器上创建一个数据库,在目标数据库服务器上创建一个数据库,以帮助进行 ETL 转换。目标服务器上的数据库包含 AWS Glue 数据目录。要查找特定对象,请在源面板或目标面板上使用搜索。
要查看特定对象如何转换,请找到要转换的项,然后从其上下文(右键单击)菜单中选择转换架构。 AWS SCT 将此选定的对象转换为脚本。
您可以在右侧面板的脚本文件夹中查看转换后的脚本。当前,该脚本是一个虚拟对象,只能作为 AWS SCT 项目的一部分使用。
要使用转换后的脚本创建 AWS Glue 任务,请将您的脚本上传到 Amazon S3。要将脚本上传到 Amazon S3,请选择脚本,然后从其上下文(右键单击)菜单中选择 保存至 S3。
步骤 2:创建作 AWS Glue 业
将脚本保存到 Amazon S3 后,您可以选择它,然后选择 “配置 AWS Glue 作业” 以打开向导来配置 AWS Glue 任务。此向导可让您更轻松地对其进行设置:
-
在向导的第一个选项卡设计数据流上,您可以选择执行策略以及要纳入这一个作业的脚本列表。您可以为每个脚本选择参数。也可以重新排列脚本,以便它们以正确的顺序运行。
-
在第二个选项卡上,您可以为作业命名,并直接配置 AWS Glue的设置。在此屏幕上,您可以配置以下设置:
-
AWS Identity and Access Management (IAM) 角色
-
脚本文件名和文件路径
-
使用具有 Amazon S3 托管式密钥的服务器端加密(SSE-S3)加密脚本
-
临时目录
-
生成的 Python 库路径
-
用户 Python 库路径
-
从属 .jar 文件的路径
-
引用的文件路径
-
每次 DPUs 作业运行并发
-
最大并发数
-
作业超时(分钟)
-
延迟通知阈值(分钟)
-
重试次数
-
安全配置
-
服务器端加密
-
-
在第三个步骤或选项卡中,您可以选择已配置的到目标端点的连接。
配置完作业后,它会显示在 AWS Glue 数据目录中的 ETL 作业下。如果您选择该作业,设置将显示,因此您可以查看或编辑它们。要在中创建新作业 AWS Glue,请从 AWS Glue 作业的上下文(右键单击)菜单中选择 “创建作业”。执行此操作将应用架构定义。要刷新显示内容,请从上下文(右键单击)菜单中选择 Refresh from database (从数据库刷新)。
此时,您可以在 AWS Glue 控制台中查看您的作业。为此,请登录 AWS 管理控制台 并打开 AWS Glue 控制台,网址为https://console.aws.amazon.com/glue/
您可以测试新作业以确保它正确工作。为此,首先检查源表中的数据,然后验证目标表是否为空。运行作业,然后再次检查。您可以从 AWS Glue 控制台查看错误日志。
