Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Trabalhar com clusters de réplicas de leitura multi-AZ para o Amazon Timestream para InfluxDB
A implantação de um cluster de réplica de leitura é um modo de implantação assíncrona do Amazon Timestream para InfluxDB que permite configurar réplicas de leitura anexadas a uma instância de banco de dados primária. Um cluster de réplica de leitura tem uma instância de banco de dados de gravação e uma instância de banco de dados de leitura em zonas de disponibilidade diferentes na mesma Região da AWS. Clusters de réplica de leitura oferecem alta disponibilidade e maior capacidade para workloads de leitura quando comparados a implantações de instância de banco de dados multi-AZ.
Disponibilidade de classe de instância para clusters de réplicas de leitura
As implantações de cluster de réplica de leitura são suportadas para os mesmos tipos de instância do Timestream normal para instâncias do InfluxDB.
| Classe de instância | vCPU | Memória (GiB) | Tipo de armazenamento | Largura de banda da rede (Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | Influx IOPS incluído | 10 |
| db.influx.large | 2 | 16 | Influx IOPS incluído | 10 |
| db.influx.xlarge | 4 | 32 | Influx IOPS incluído | 10 |
| db.influx.2xlarge | 8 | 64 | Influx IOPS incluído | 10 |
| db.influx.4xlarge | 16 | 128 | Influx IOPS incluído | 10 |
| db.influx.8xlarge | 32 | 256 | Influx IOPS incluído | 12 |
| db.influx.12xlarge | 48 | 384 | Influx IOPS incluído | 20 |
| db.influx.16xlarge | 64 | 512 | Influx IOPS incluído | 25 |
| db.influx.24xlarge | 96 | 768 | Influx IOPS incluído | 40 |
Ler arquitetura de cluster de réplica
Com um cluster de réplica de leitura, o Amazon Timestream for InfluxDB replica automaticamente todas as gravações feitas na instância de banco de dados do gravador para todas as instâncias de banco de dados do leitor usando o complemento de réplica de leitura licenciado. InfluxData Essa replicação é assíncrona e todas as gravações são reconhecidas assim que são confirmadas pelo nó do gravador. As gravações não exigem a confirmação de todos os nós de leitura para serem consideradas uma gravação bem-sucedida. Depois que os dados são confirmados pela instância de banco de dados do gravador, eles são replicados para a instância de réplica de leitura quase instantaneamente. Em caso de falha irrecuperável do gravador, quaisquer dados que não tenham sido replicados para pelo menos um dos leitores serão perdidos.
Uma instância de réplica de leitura é uma cópia somente para leitura de uma instância de gravador do banco de dados. É possível reduzir a carga na instância de gravador do banco de dados roteando algumas ou todas as consultas dos aplicativos para a réplica de leitura. Dessa maneira, é possível aumentar a escala horizontalmente para além das limitações de capacidade de uma única instância de banco de dados para workloads de banco de dados com muita leitura.
O diagrama a seguir mostra uma instância de banco de dados primário replicando para uma réplica de leitura em uma zona de disponibilidade diferente. Os clientes têm read/write acesso à instância de banco de dados primária e acesso somente de leitura à réplica.
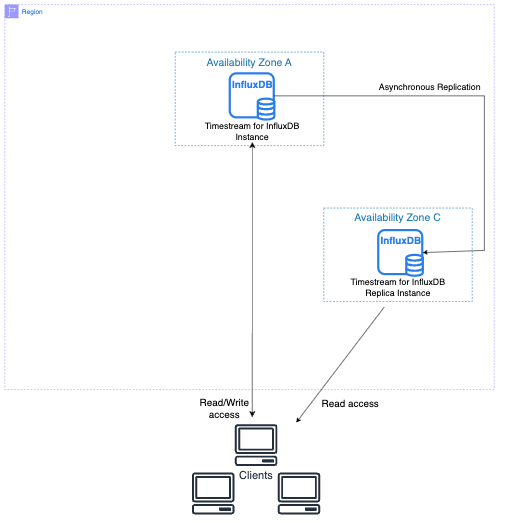
Grupos de parâmetros para clusters de réplicas de leitura
Em um cluster de réplica de leitura, um grupo de parâmetros de banco de dados atua como um contêiner para os valores de configuração do mecanismo aplicados a cada instância de banco de dados em um cluster de réplica de leitura. Um grupo de parâmetros de banco de dados padrão é definido com base no mecanismo de banco de dados e na versão do mecanismo de banco de dados. As configurações no grupo de parâmetros de banco de dados são utilizadas para todas as instâncias de banco de dados do cluster.
Ao transmitir um grupo de parâmetros de banco de dados específico usando CreateDbClusterou UpdateDbClusterpara uma réplica de leitura de banco de dados Multi-AZ, certifique-se de que storage-wal-max-write-delay esteja definido para uma duração mínima de 1 hora. Se nenhum grupo de parâmetros do banco de dados for especificado, o padrão storage-wal-max-write-delay será de 1 hora.
Atraso de réplica em clusters de réplica de leitura
Embora os clusters de réplica de leitura Timestream para InfluxDB permitam uma alta performance de gravação, o atraso de réplica ainda pode ocorrer devido à natureza da replicação baseada em mecanismo assíncrono. Esse atraso pode levar à possível perda de dados no caso de um failover, o que faz do monitoramento essencial.
Você pode rastrear o atraso da réplica CloudWatch selecionando Todas as métricas no Console de gerenciamento da AWS painel de navegação. Escolha Timestream/InfluxDB e, em seguida, Por. DbCluster Selecione seu DbClusterNamee depois seu DbReaderInstanceName. Aqui, além do conjunto normal de métricas rastreadas para todas as instâncias do Timestream for InfluxDB (veja a lista abaixo), você também verá ReplicaLag, expresso em milissegundos.
CPUUtilization
MemoryUtilization
DiskUtilization
ReplicaLag (somente para instâncias de banco de dados no modo de instância de réplica)
Causas comuns de atraso de réplica
Em geral, o atraso de réplica ocorre quando os workloads de gravação e leitura são muito altos para que as instâncias de banco de dados do leitor apliquem as transações de forma eficiente. Vários workloads podem incorrer em atraso de réplica temporário ou contínuo. Os seguintes exemplos demonstram as causas comuns:
Alta simultaneidade de gravação ou atualização em lote pesado na instância de banco de dados do gravador, fazendo com que o processo de aplicação nas instâncias de banco de dados do leitor fique para trás.
Workload de leitura pesada que usa recursos em uma ou mais instâncias de banco de dados do leitor. Executar consultas lentas ou grandes pode afetar o processo de aplicação e causar atraso de réplica.
As transações que modificam grandes quantidades de dados ou instruções DDL às vezes podem causar um aumento temporário no atraso de réplica porque o banco de dados deve preservar a ordem de confirmação.
Para ver um tutorial que mostra como criar um CloudWatch alarme quando o atraso da réplica excede um determinado período de tempo, consulte. Tutorial: Crie um CloudWatch alarme da Amazon para o atraso de réplica do cluster Multi-AZ para o Amazon Timestream para InfluxDB
Diminuir o atraso de réplica
Para clusters de réplica de leitura do Timestream para InfluxDB, é possível mitigar o atraso da réplica reduzindo a carga na instância de banco de dados do gravador.
Disponibilidade e durabilidade
Os clusters de réplicas de leitura podem ser configurados para realizar o failover automático para uma das instâncias do leitor em caso de falha do gravador em priorizar a disponibilidade de gravação ou para evitar falhas para minimizar a perda de dados de ponta. Os dados de ponta se referem à lacuna de replicação de dados ainda não replicados em pelo menos um dos nós do leitor (consulte Atraso de réplica em clusters de réplica de leitura). O comportamento padrão e recomendado para clusters de réplicas de leitura é o failover automático em caso de falhas no gravador. Porém, se a perda de dados de ponta for mais importante do que a disponibilidade de gravação para seus casos de uso, você poderá substituir o padrão atualizando o cluster.
Os clusters de réplica de leitura garantem que todas as instâncias de banco de dados do cluster sejam distribuídas em pelo menos duas zonas de disponibilidade para garantir maior disponibilidade de gravação e durabilidade dos dados em caso de interrupção da zona de disponibilidade.
Tópicos
Visão geral dos clusters de réplica de leitura do Amazon Timestream para InfluxDB
Criando um cluster de réplica de leitura do Timestream para InfluxDB
Conectando-se a um cluster de réplica de leitura de banco de dados do Timestream para InfluxDB
Modificar um cluster de réplica de leitura para o Amazon Timestream para InfluxDB
Reinicializando um cluster de réplica de leitura no Amazon Timestream para InfluxDB
Criação de CloudWatch alarmes para monitorar o Amazon Timestream para InfluxDB
