Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criando um cluster de réplica de leitura do Timestream para InfluxDB
Um cluster de réplica de leitura do Timestream para InfluxDB tem uma instância de banco de dados de gravador e uma instância de banco de dados de leitor em zonas de disponibilidade separadas. Os clusters de réplica de leitura do Timestream para InfluxDB fornecem alta disponibilidade, maior capacidade para workloads de leitura e um failover mais rápido quando o failover para réplica é configurado.
Pré-requisitos do cluster de banco de dados
Importante
As etapas a seguir são pré-requisitos que devem ser concluídos antes da criação de um cluster de réplica de leitura.
Configurar a rede para o cluster de banco de dados
Só é possível criar um cluster de réplica de leitura do Timestream para InfluxDB em uma nuvem privada virtual (VPC) com base no serviço da Amazon VPC. Ele deve estar em um local Região da AWS que tenha pelo menos três zonas de disponibilidade. O grupo de sub-redes do banco de dados escolhido para o cluster de banco de dados deve incluir pelo menos três zonas de disponibilidade. Essa configuração garante que cada instância de banco de dados no cluster de banco de dados esteja em uma zona de disponibilidade diferente.
Para se conectar ao cluster de banco de dados usando recursos que não sejam instâncias do EC2 na mesma VPC, configure as conexões de rede manualmente.
Pré-requisitos adicionais
Antes de criar o cluster de réplica de leitura, considere os seguintes pré-requisitos adicionais:
Para personalizar os parâmetros de configuração do cluster de banco de dados, especifique um grupo de parâmetros do cluster de banco de dados com as configurações de parâmetro necessárias. Para obter informações sobre como criar ou modificar um grupo de parâmetros de cluster de banco de dados, consulte Grupos de parâmetros para clusters de réplicas de leitura.
Determine o número da TCP/IP porta a ser especificada para seu cluster de banco de dados. Em algumas empresas, firewalls bloqueiam conexões com as portas padrão. Se o firewall da sua empresa bloquear a porta padrão, escolha outra porta para o cluster de banco de dados. Todas as instâncias de banco de dados em um cluster de banco de dados utilizam a mesma porta.
Criar um cluster de banco de dados
Você pode criar um cluster de banco de dados de réplica de leitura Timestream para o InfluxDB usando a API Console de gerenciamento da AWS, AWS CLI the ou Amazon Timestream for InfluxDB.
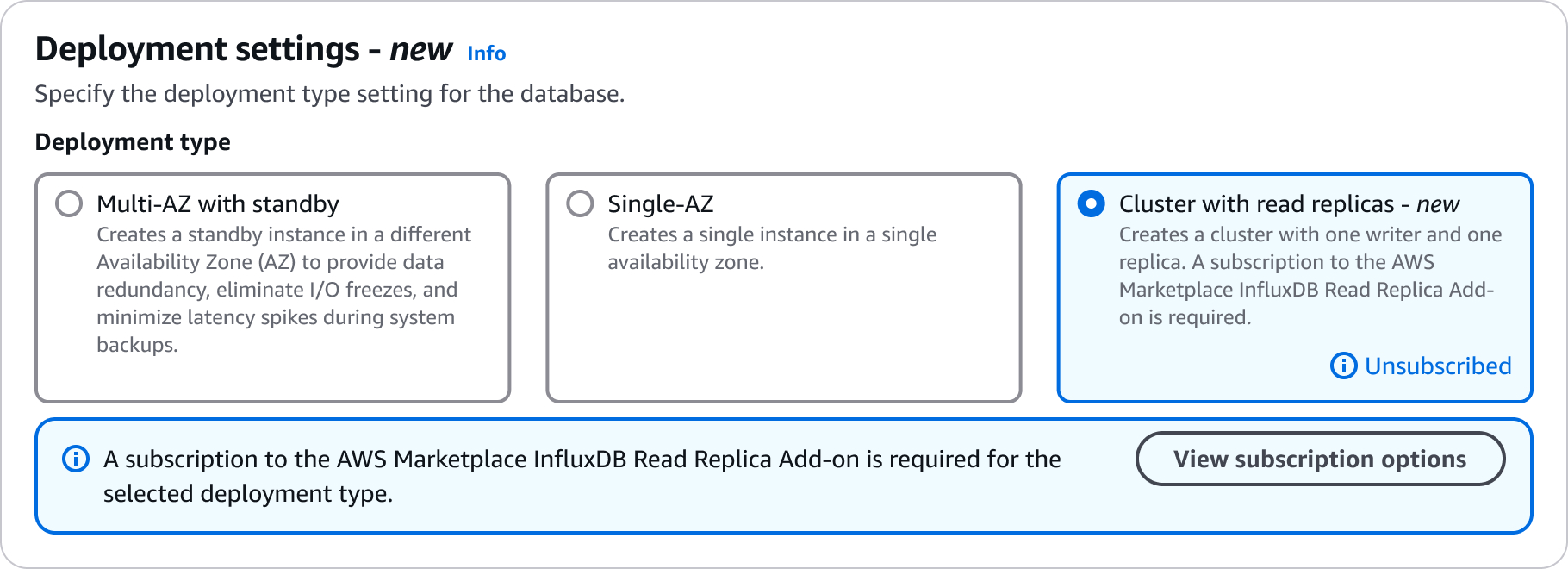
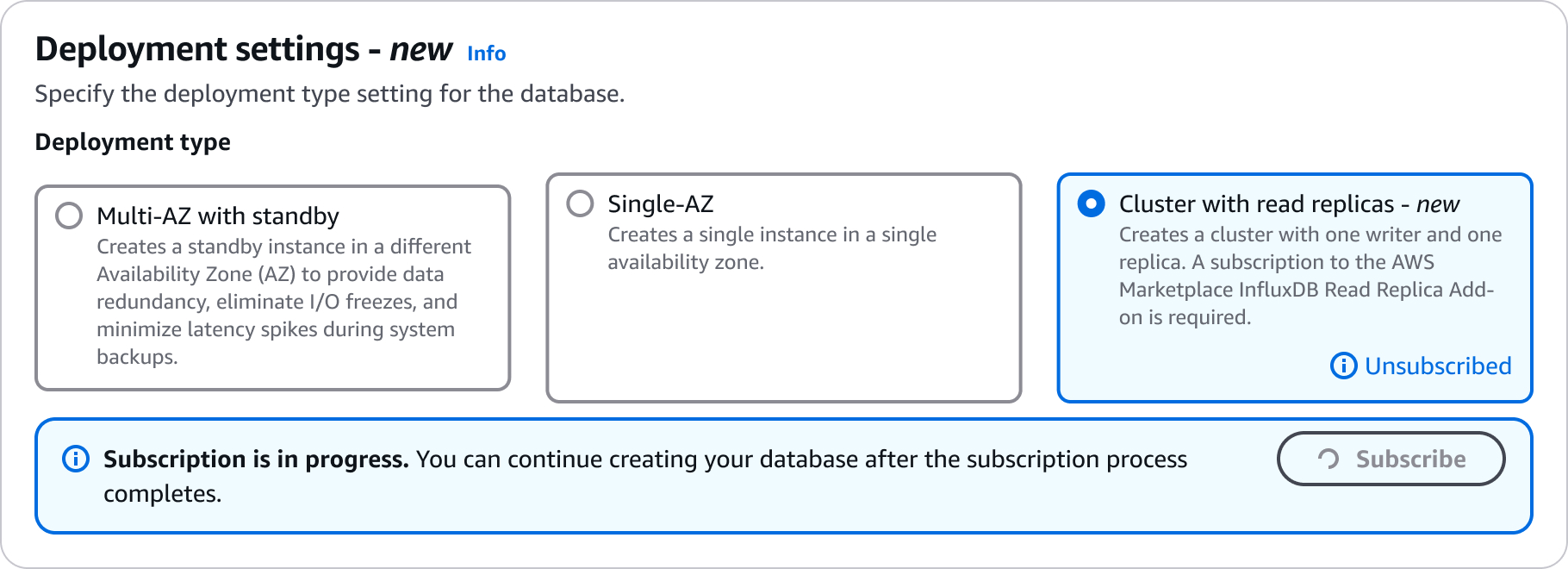
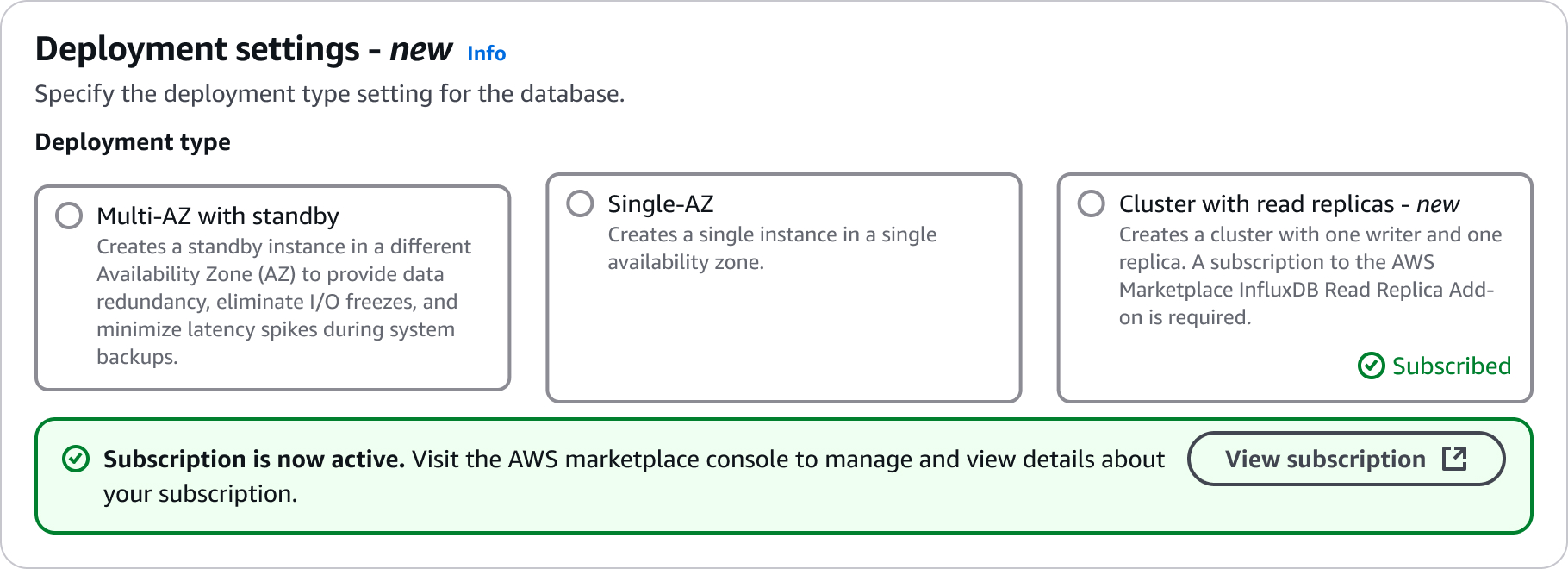
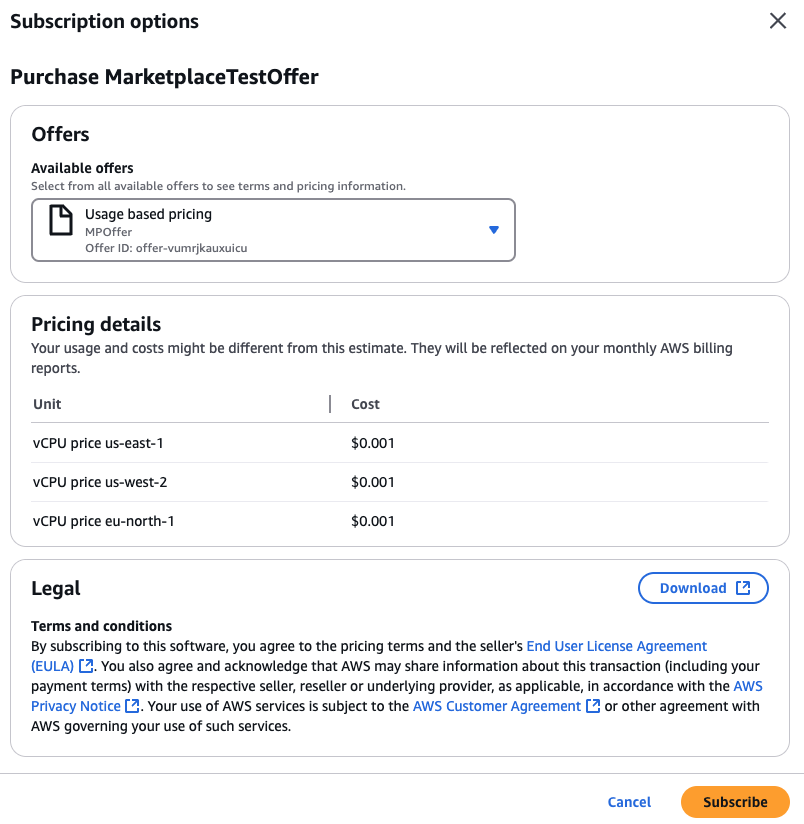
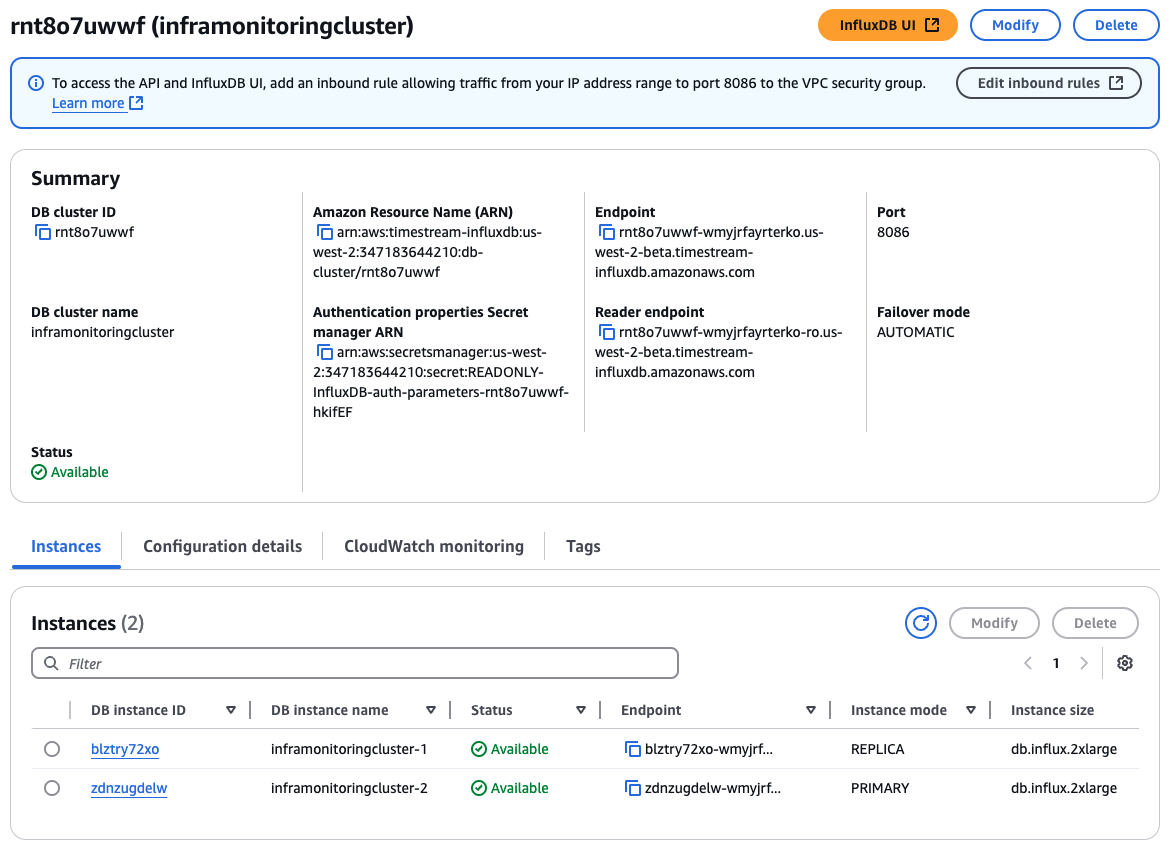
Configurações para criar clusters de réplicas de leitura
Para obter detalhes sobre as configurações que você escolhe ao criar um cluster de réplica de leitura, consulte a tabela a seguir. Para obter mais informações sobre as AWS CLI opções, consulte create-db-cluster
| Configuração do console | Descrição da configuração | Opção CLI e parâmetro de API Timestream para InfluxDB |
|---|---|---|
| Armazenamento alocado | O valor de armazenamento a ser alocado para cada instância de banco de dados no seu cluster de banco de dados (em gibibytes). Para obter mais informações, consulte Armazenamento da instância do InfluxDB. |
Opção CLI: Parâmetro da API: |
| Porta do banco de dados | O número da porta na qual o InfluxDB aceita conexões. Valores válidos: 1024-65535 Padrão: 8086 Restrições: o valor não pode ser 2375-2376, 7788-7799, 8090 ou 51678-51680. |
Opção CLI: Parâmetro da API: |
| Nome do cluster do banco de dados | O nome que identifica de forma exclusiva o cluster de banco de dados. Os nomes das instâncias de banco de dados devem ser exclusivos por cliente e por região. |
Opção CLI: Parâmetro da API: |
| Tipo de instância do banco de dados | A capacidade de computação e memória de cada instância de banco de dados no cluster de banco de dados do Timestream para InfluxDB, por exemplo db.influx.xlarge. Se possível, escolha uma classe de instância de banco de dados grande o suficiente para um conjunto de trabalho de consulta típico pode ser sustentado na memória. Quando os conjuntos de trabalho são mantidos na memória o sistema pode evitar a gravação em disco, o que aprimora a performance. |
Opção CLI: Parâmetro da API: |
| Grupo de parâmetros do cluster de banco de dados | O ID do grupo de parâmetros de banco de dados a atribuir ao seu cluster de banco de dados. Grupos de parâmetros do DB especificam como o banco de dados é configurado. Por exemplo, grupos de parâmetros de DB podem especificar o limite para a simultaneidade de consultas. |
Opção CLI: Parâmetro da API: |
| Tipo de implantação |
Especifica se o cluster de banco de dados será implantado como uma réplica de leitura de vários nós ou uma réplica de leitura de vários nós AZ. Valores possíveis: |
Opção CLI: Parâmetro da API: |
| ID das sub-redes da VPC | O ID de sub-redes de banco de dados que você deseja usar para o cluster de banco de dados. Selecione Escolher existente para usar um grupo de sub-redes de banco de dados existente e, em seguida, escolha o grupo de sub-redes necessário na lista suspensa Grupos de sub-redes de banco de dados existentes. Escolha Configuração automática para permitir que o Timestream para InfluxDB selecione um grupo de sub-redes de banco de dados compatível. |
Opção CLI: Parâmetro da API: |
| Organização | O nome da organização inicial para o usuário administrador inicial no InfluxDB. Uma organização do InfluxDB é um espaço de trabalho para um grupo de usuários. |
Opção CLI: Parâmetro da API: |
| Bucket | O nome do bucket inicial do InfluxDB. Todos os dados do InfluxDB são armazenados em um bucket. Um bucket combina o conceito de banco de dados e um período de retenção (a duração do tempo em que cada ponto de dados persiste). Um bucket pertence a uma organização. |
Opção CLI: Parâmetro da API: |
| Exportações de log |
Configuração para enviar logs do mecanismo InfluxDB para um bucket do S3 especificado. Configuração para entrega de log de bucket do S3: O nome do bucket S3 ao qual enviar logs: Indica se a entrega do log ao bucket S3 está habilitada: Sintaxe abreviada: |
Opção CLI: Parâmetro da API: |
| Senha | A senha do usuário administrador inicial que você criou no InfluxDB. Essa senha permitirá que você acesse a UI do InfluxDB para realizar várias tarefas administrativas e também use a CLI InfluxDB para criar um token de operador. Esses atributos serão armazenados em um segredo criado no AWS Secrets Manager em sua conta. |
Opção CLI: Parâmetro da API: |
| Nome de usuário | O nome de usuário do usuário administrador inicial criado no InfluxDB. Deve começar com uma letra e não pode terminar com um hífen ou conter dois hifens consecutivos. Por exemplo, my-user1. Esse nome de usuário permitirá que você acesse a UI do InfluxDB para realizar várias tarefas administrativas e também use a CLI InfluxDB para criar um token de operador. Esses atributos serão armazenados em um segredo criado no AWS Secrets Manager em sua conta. |
Opção CLI: Parâmetro da API: |
| Acesso público | Indica se o cluster de banco de dados é acessível de fora da VPC. Acessível publicamente fornece ao cluster de banco de dados um endereço IP público, que é acessível fora da VPC. Para ser acessível publicamente, o cluster de banco de dados também deve estar em uma sub-rede pública na VPC. Não acessível publicamente torna o cluster de banco de dados acessível somente de dentro da VPC. |
Opções de CLI: Parâmetro da API: |
| Tipo de armazenamento do banco de dados | Dados do InfluxDB. Você pode escolher entre três tipos diferentes de armazenamento provisionado Influx IOPS Included de acordo com os requisitos do seu workload. Possíveis valores:
|
Opções de CLI: Parâmetro da API: |
| Grupo de segurança de VPC | Uma lista de grupos de segurança da VPC IDs a serem associados à instância de banco de dados. |
Opções de CLI: Parâmetro da API: |
| Sub-rede VPC IDs | Uma lista de sub-redes VPC IDs para associar à instância de banco de dados. Forneça pelo menos duas sub-redes VPC IDs em diferentes zonas de disponibilidade ao implantar com um cluster de banco de dados Timestream para InfluxDB. |
Opções de CLI: Parâmetro da API: |
| Modo de failover | Como seu cluster responde a uma falha na instância primária. É possível configurar isto com as seguintes opções:
|
Opções de CLI: Parâmetro da API: |
Importante
Como parte do objeto de resposta do cluster de banco de dados, você receberá um influxAuthParametersSecretArn. Isso manterá um ARN para um segredo do Secrets Manager em sua conta. Ele só será preenchido depois que suas instâncias de banco de dados InfluxDB estiverem disponíveis. O segredo contém os parâmetros de autenticação Influx fornecidos durante o processo CreateDbInstance. Essa é uma cópia somente para leitura, pois qualquer cópia desse segredo não afeta updates/modifications/deletions a instância de banco de dados criada. Se você excluir esse segredo, nossa resposta da API ainda se referirá ao ARN secreto excluído.
