As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Guia de integração
Toda a solução foi projetada para ser facilmente extensível. A camada de orquestração dessa solução é criada usando. LangChain
Suporte de expansão LLMs
Para adicionar outro provedor de modelo, como um provedor LLM personalizado, você deve atualizar os três componentes da solução a seguir:
-
Crie uma nova pilha de
TextUseCaseCDK, que implanta o aplicativo de bate-papo configurado com seu provedor LLM personalizado:-
Clone o GitHub repositório
dessa solução e configure seu ambiente de compilação seguindo as instruções fornecidas no arquivo README.md . -
Copie (ou crie um novo) o
source/infrastructure/lib/bedrock-chat-stack.tsarquivo, cole-o no mesmo diretório e renomeie-o paracustom-chat-stack.ts. -
Renomeie a classe no arquivo para uma adequada, como
CustomLLMChat. -
Você pode optar por adicionar um segredo do Secrets Manager a essa pilha, que armazena suas credenciais para seu LLM personalizado. Você pode recuperar essas credenciais durante a invocação do modelo na camada Lambda de bate-papo discutida no próximo parágrafo.
-
-
Crie e anexe uma camada Lambda contendo a biblioteca Python do provedor de modelo a ser adicionada. Para um aplicativo de bate-papo de casos de uso do Amazon Bedrock, a biblioteca
langchain-awsPython contém os conectores personalizados na parte superior do pacote para se conectar aos provedores de LangChain modelos da AWS (Amazon Bedrock SageMaker e AI), às bases de conhecimento (Amazon Kendra e Amazon Bedrock Knowledge Bases) e aos tipos de memória (como o DynamoDB). Da mesma forma, outros fornecedores de modelos têm seus próprios conectores. Essa camada ajuda você a anexar a biblioteca Python desse provedor de modelos para que você possa usar esses conectores na camada Lambda de bate-papo, que invoca o LLM (etapa 3). Nessa solução, um agrupador de ativos personalizado é usado para criar camadas Lambda, que são anexadas usando aspectos do CDK. Para criar uma nova camada para a biblioteca do provedor de modelos personalizados:-
Navegue até a
LambdaAspectsclasse nosource/infrastructure/lib/utils/lambda-aspects.tsarquivo. -
Siga as instruções sobre como estender a funcionalidade da classe de aspectos Lambda fornecida no arquivo (como adicionar o
getOrCreateLangchainLayermétodo). Para usar esse novo método (por exemplo,getOrCreateCustomLLMLayer), atualize também aLLM_LIBRARY_LAYER_TYPESenumeração nosource/infrastructure/lib/utils/constants.tsarquivo.
-
-
Estenda a função
chatLambda para implementar um construtor, cliente e manipulador para o novo provedor.O
source/lambda/chatcontém as LangChain conexões de diferentes classes, LLMs juntamente com as classes de suporte para construí-las LLMs. Essas classes de suporte seguem os padrões de design Builder e Object Oriented para criar o LLM.Cada manipulador (por exemplo,
bedrock_handler.py) primeiro cria um cliente, verifica o ambiente em busca das variáveis de ambiente necessárias e, em seguida, chama umget_modelmétodo para obter a classe LangChain LLM. O método generate é então chamado para invocar o LLM e obter sua resposta. LangChain atualmente oferece suporte à funcionalidade de streaming para o Amazon Bedrock, mas não para SageMaker IA. Com base na funcionalidade de streaming ou não streaming, o WebSocket manipulador apropriado (WebsocketStreamingCallbackHandlerouWebsocketHandler) é chamado para enviar a resposta de volta à WebSocket conexão usando opost_to_connectionmétodo.A
clients/builderpasta contém as classes que ajudam a criar um LLM Builder usando o padrão Builder. Primeiro, ause_case_configé recuperado de um armazenamento de configurações do DynamoDB, que armazena os detalhes sobre o tipo de base de conhecimento, memória de conversação e modelo a ser construído. Ele também contém detalhes relevantes do modelo, como parâmetros e avisos do modelo. Em seguida, o Builder ajuda a seguir as etapas para criar uma base de conhecimento, criar uma memória de conversação para manter o contexto da conversa para o LLM, definir os retornos de LangChain chamada apropriados para casos de streaming e não streaming e criar um modelo LLM com base nas configurações de modelo fornecidas. A configuração do DynamoDB é armazenada no momento da criação do caso de uso, quando você implanta um caso de uso a partir do painel de implantação (ou quando é fornecida pelos usuários em implantações autônomas de pilha de casos de uso sem o painel de implantação).A
clients/factoriessubpasta ajuda a definir a memória de conversação e a classe da base de conhecimento apropriadas, com base na configuração do LLM. Isso permite uma fácil extensão para qualquer outra base de conhecimento ou tipo de memória que você queira que sua implementação ofereça suporte.A
sharedsubpasta contém implementações específicas da base de conhecimento e da memória de conversação que são instanciadas dentro das fábricas pelo construtor. Ele também contém recuperadores do Amazon Kendra e do Amazon Bedrock Knowledge Base LangChain chamados para recuperar documentos para os casos de uso do RAG, além de retornos de chamada, que são usados pelo modelo LLM. LangChainAs LangChain implementações usam a Linguagem de LangChain Expressão (LCEL) para compor cadeias de conversação.
RunnableWithMessageHistoryA classe é usada para manter o histórico de conversas com cadeias de LCEL personalizadas, permitindo que funcionalidades como retornar documentos de origem e usar a pergunta reformulada (ou desambiguada) enviada à base de conhecimento também sejam enviadas ao LLM.Para criar sua própria implementação de um provedor personalizado, você pode:
-
Copie o
bedrock_handler.pyarquivo e crie seu manipulador personalizado (por exemplo,custom_handler.py), que cria seu cliente personalizado (por exemplo,CustomProviderClient) (especificado na etapa a seguir). -
Copie
bedrock_client.pyna pasta de clientes. Renomeie-o paracustom_provider_client.py(ou para o nome específico do provedor do modelo, comoCustomProvider). Nomeie a classe dentro dela de forma adequada, como aCustomProviderClientqueLLMChatClientherda.Você pode usar os métodos fornecidos por
LLMChatClientou escrever suas próprias implementações para substituí-los.O
get_modelmétodo cria umCustomProviderBuilder(consulte a etapa a seguir) e chama oconstruct_chat_modelmétodo que constrói o modelo de bate-papo usando as etapas do construtor. Esse método atua como diretor no padrão do construtor. -
Copie
clients/builders/bedrock_builder.pye renomeie paracustom_provider_builder.pye a classe dentro dela paraCustomProviderBuilderque herda LLMBuilder ()llm_builder.py. Você pode usar os métodos fornecidos por LLMBuilder ou escrever suas próprias implementações para substituí-los. As etapas do construtor são chamadas em sequência dentro doconstruct_chat_modelmétodo do clienteset_model_defaults, comoset_knowledge_base,set_conversation_memorye.O
set_llm_modelmétodo criaria o modelo LLM real usando todos os valores definidos usando os métodos chamados antes dele. Especificamente, você pode criar um LLM RAG (CustomProviderRetrievalLLM) ou não RAG (CustomProviderLLM), com base norag_enabled variableque é recuperado da configuração do LLM no DynamoDB.Essa configuração é obtida no
retrieve_use_case_configmétodo daLLMChatClientclasse. -
Implemente sua
CustomProviderRetrievalLLMimplementaçãoCustomProviderLLMou nallm_modelssubpasta com base na necessidade de um caso de uso RAG ou não RAG. A maioria das funcionalidades para implementar esses modelos é fornecida em suasRetrievalLLMclassesBaseLangChainModele, respectivamente, para casos de uso não RAG e RAG.Você pode copiar o
llm_models/bedrock.pyarquivo e fazer as alterações necessárias para chamar o LangChain modelo que se refere ao seu provedor personalizado. Por exemplo, o Amazon Bedrock usa umaChatBedrockclasse para criar um modelo de bate-papo usando LangChain.O método generate gera a resposta LLM usando as cadeias LangChain LCEL.
Você também pode usar o
get_clean_model_paramsmétodo para higienizar os parâmetros do modelo de acordo LangChain com os requisitos do seu modelo.
-
Expandindo as ferramentas Strands suportadas
A solução permite que você crie e implante servidores MCP, agentes de IA e fluxos de trabalho com vários agentes. Na experiência do Agent Builder, você pode conectar servidores MCP para oferecer recursos adicionais aos seus agentes. Além dos servidores MCP, você pode aproveitar as ferramentas integradas fornecidas pela Strands
Pronta para uso, a solução vem pré-configurada com as seguintes ferramentas Strands:
-
Hora atual (ativada por padrão)
-
Calculadora (ativada por padrão)
-
Environment
Seleção de servidor e ferramentas MCP no assistente do Agent Builder mostrando as ferramentas Strands integradas

Para ampliar seus agentes com ferramentas adicionais da Strands, siga o processo de quatro etapas descrito nesta seção.
Etapa 1: Encontre a ferramenta Strands
Navegue pelas ferramentas Strands disponíveis
Por exemplo, para adicionar recursos de recuperação da Base de Conhecimento Amazon Bedrock, você usaria a ferramenta de recuperação
Etapa 2: atualizar o parâmetro SSM
Para disponibilizar uma ferramenta na interface de implantação do Agent Builder, atualize o parâmetro AWS Systems Manager Parameter Store que define quais ferramentas Strands são suportadas.
-
Navegue até o AWS Systems Manager Parameter Store em sua conta da AWS.
-
Localize o parâmetro:
/gaab/<stack-name>/strands-tools -
Adicione a configuração da ferramenta ao final da lista existente usando a seguinte estrutura JSON:
{ "name": "Bedrock KB Retrieve", "description": "Retrieve information from Bedrock Knowledge Base", "value": "retrieve", "category": "AI", "isDefault": false }Campo Description name
Nome de exibição mostrado na interface do Agent Builder
descrição
Breve descrição da funcionalidade da ferramenta
value
O nome exato da ferramenta, conforme definido no pacote de ferramentas Strands
category
Categoria organizacional para agrupar ferramentas na interface do usuário
é o padrão
Se a ferramenta deve ser ativada por padrão para novos agentes
Etapa 3: Configurar variáveis de ambiente
Muitas ferramentas Strands exigem variáveis de ambiente para configuração. Você pode definir essas variáveis de duas maneiras:
Opção 1: configuração direta no AgentCore Runtime
Atualize o agente implantado diretamente no Amazon Bedrock AgentCore Runtime com as variáveis de ambiente necessárias.
Opção 2: Parâmetros do modelo no assistente de implantação
Adicione variáveis de ambiente durante a etapa de seleção do modelo no assistente do Agent Builder usando a seção Parâmetros do modelo. As variáveis de ambiente que seguem a convenção de nomenclatura ENV_<ALL_CAPS_TOOL_NAME>_<env_variable_name> serão carregadas automaticamente em tempo de execução no ambiente de execução do agente como<env_variable_name>.
Por exemplo:
-
ENV_RETRIEVE_KNOWLEDGE_BASE_IDse tornaKNOWLEDGE_BASE_ID -
ENV_RETRIEVE_MIN_SCOREse tornaMIN_SCORE
Seção de parâmetros avançados do modelo mostrando a configuração ENV_RETRIEVE_KNOWLEDGE_BASE_ID

Consulte a documentação ou o código-fonte da ferramenta específica para identificar as variáveis de ambiente necessárias. Para a ferramenta de recuperação, você pode encontrar opções de configuração no código-fonte
Etapa 4: adicionar permissões do IAM
Adicione manualmente todas as permissões necessárias do IAM à sua função AgentCore de execução do Runtime para permitir que o agente use a ferramenta.
Por exemplo, para usar a ferramenta de recuperação com as bases de conhecimento Amazon Bedrock:
-
Navegue até o console do IAM em sua conta da AWS.
-
Localize a função AgentCore de execução do Runtime para seu agente.
-
Adicione a seguinte permissão:
{ "Effect": "Allow", "Action": "bedrock:Retrieve", "Resource": "arn:aws:bedrock:region:account-id:knowledge-base/knowledge-base-id" }
Console do IAM mostrando a StrandsRetrieveTool KBAccess política anexada à função AgentCore de execução do Runtime

As permissões específicas necessárias variam de acordo com a ferramenta. Consulte a documentação da ferramenta e a documentação do serviço da AWS para determinar as permissões apropriadas do IAM.
Etapa 5: testar o agente
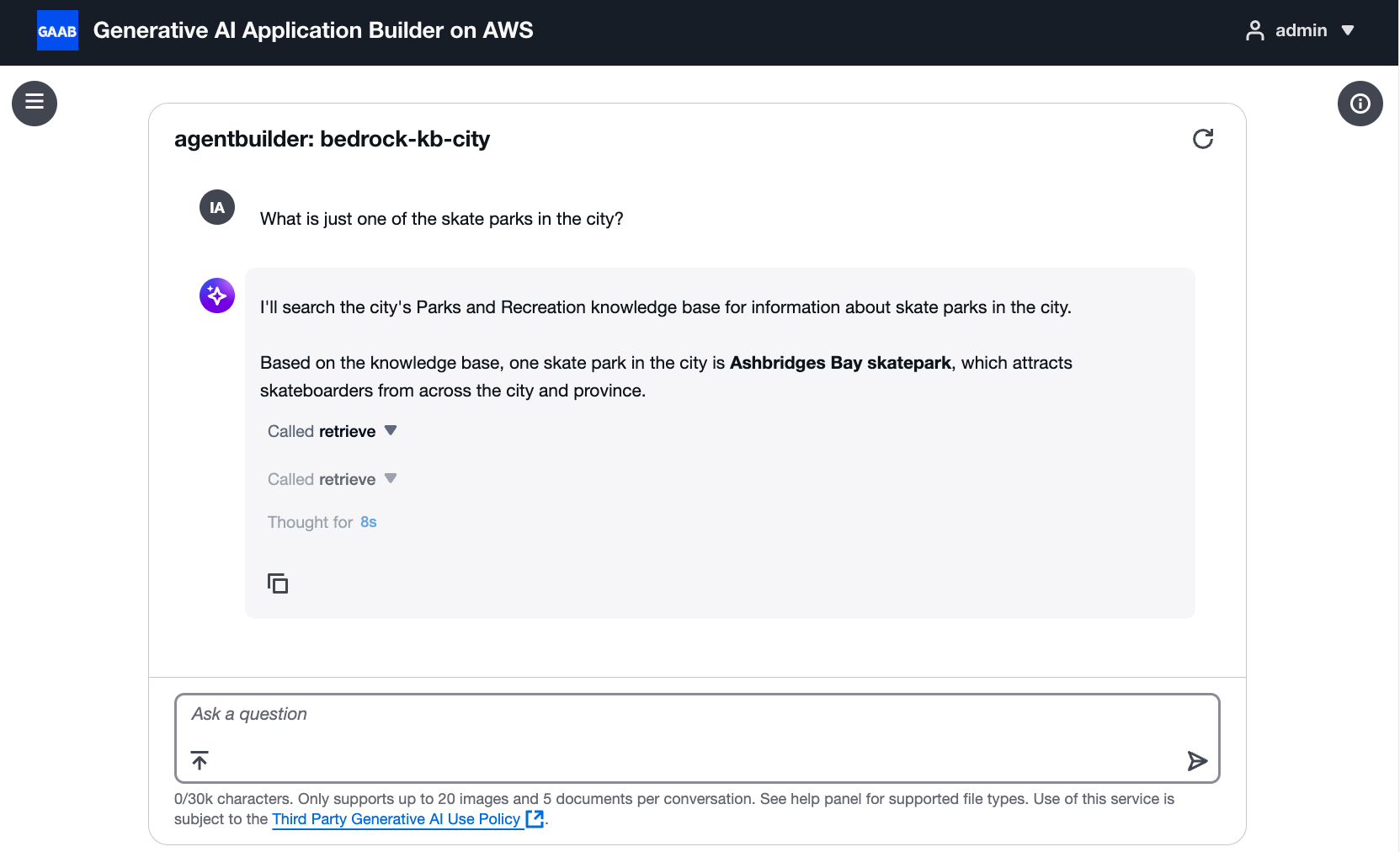
Depois de concluir as etapas de configuração, teste seu agente para verificar se a ferramenta está funcionando corretamente. Você deve ver as invocações da ferramenta nos registros de execução e nas respostas do agente.
Agente usando com sucesso a ferramenta de recuperação para responder a uma pergunta sobre parques de skate
nota
Para obter uma lista completa das ferramentas Strands disponíveis e seus recursos, consulte a documentação das Strands Community Tools
Expandindo as bases de conhecimento suportadas e os tipos de memória de conversação
Para adicionar suas implementações de memória de conversação ou base de conhecimento, adicione as implementações necessárias na shared pasta e, em seguida, edite as fábricas e as enumerações apropriadas para criar uma instância dessas classes.
Quando você fornece a configuração do LLM, que é armazenada dentro do repositório de parâmetros, a memória de conversação e a base de conhecimento apropriadas serão criadas para seu LLM. Por exemplo, quando o ConversationMemoryType é especificado como DynamoDB, uma instância DynamoDBChatMessageHistory de (disponível shared_components/memory/ddb_enhanced_message_history.py no interior) é criada. Quando o KnowledgeBaseType é especificado como Amazon Kendra, uma instância KendraKnowledgeBase de (disponível shared_components/knowledge/kendra_knowledge_base.py no interior) é criada.
Criando e implantando as alterações de código
Crie o programa com o npm run build comando. Depois que todos os erros forem resolvidos, execute cdk synth para gerar os arquivos de modelo e todos os ativos do Lambda.
-
Você pode usar o
–0—/stage-assets.shscript para colocar manualmente todos os ativos gerados no intervalo de preparação da sua conta. -
Use o comando a seguir para implantar ou atualizar a plataforma:
cdk deploy DeploymentPlatformStack --parameters AdminUserEmail='admin-email@amazon.com'Quaisquer CloudFormation parâmetros adicionais da AWS também devem ser fornecidos junto com o AdminUserEmailparâmetro.
