Introdução
A segurança é a principal prioridade na AWS. Os clientes da AWS se beneficiam de data centers e arquiteturas de rede projetados para atender às necessidades das organizações mais sensíveis em termos de segurança. A AWS adota um modelo de responsabilidade compartilhada, no qual a AWS gerencia a segurança da nuvem, enquanto os clientes são responsáveis pela segurança na nuvem. Isso significa que você tem controle total sobre a implementação da sua segurança, incluindo o acesso a diversas ferramentas e serviços que auxiliam no atendimento aos seus objetivos de segurança. Essas funcionalidades ajudam você a estabelecer uma linha de base de segurança para as aplicações que estão em execução na Nuvem AWS.
Quando ocorre uma divergência em relação à linha de base, seja por uma configuração incorreta ou por fatores externos em constante alteração, será necessário responder e investigar. Para alcançar esse objetivo com êxito, é necessário compreender os conceitos básicos de resposta a incidentes de segurança dentro do seu ambiente da AWS e os requisitos para preparar, instruir e treinar as equipes de nuvem antes que ocorram problemas de segurança. É importante saber quais controles e funcionalidades podem ser usados, analisar os exemplos atuais para resolver preocupações potenciais e identificar métodos de remediação que empreguem automação para melhorar a velocidade e a consistência da resposta. Além disso, você deve compreender os requisitos de conformidade e de regulamentação relacionados ao desenvolvimento de um programa de resposta a incidentes de segurança para cumprir essas exigências.
A resposta a incidentes de segurança pode ser complexa, portanto, recomendamos que você adote uma abordagem iterativa. Comece com os serviços principais de segurança, desenvolva as funcionalidades de base de detecção e de resposta, e, em seguida, desenvolva planos de ação para criar uma biblioteca inicial de mecanismos de resposta a incidentes que possa ser aprimorada e iterada continuamente.
Antes de começar
Antes de iniciar o aprendizado sobre a resposta a incidentes em eventos de segurança na AWS, é importante familiarizar-se com os padrões e estruturas relevantes à segurança e à resposta a incidentes da AWS. Esses fundamentos ajudarão você a compreender os conceitos e as práticas recomendadas apresentados neste guia.
Padrões e estruturas de segurança da AWS
Para começar, recomendamos que você analise as Práticas recomendadas de segurança, identidade e conformidade, o Pilar Segurança: AWS Well-Architected Framework
O AWS CAF fornece orientações para apoiar a coordenação entre diferentes áreas das organizações que estão migrando para a nuvem. As orientações do AWS CAF são divididas em diversas áreas de foco, denominadas perspectivas, que são relevantes para o desenvolvimento de sistemas de TI baseados na nuvem. A perspectiva de segurança descreve como implementar um programa de segurança ao longo dos fluxos de trabalho, incluindo a resposta a incidentes. Este documento é resultado de nossas experiências trabalhando com clientes para ajudá-los a desenvolver programas e funcionalidades eficazes e eficientes de resposta a incidentes de segurança.
Padrões e estruturas do setor destinados a resposta a incidentes
Este whitepaper segue os padrões e as práticas recomendadas de resposta a incidentes do Computer Security Incident Handling Guide SP 800-61 r3
Visão geral da resposta a incidentes da AWS
Para começar, é importante compreender como as operações de segurança e a resposta a incidentes diferem no ambiente de nuvem. Para desenvolver funcionalidades de resposta eficazes na AWS, é necessário compreender as diferenças em relação à resposta tradicional em ambientes on-premises e o impacto dessas diferenças no seu programa de resposta a incidentes. Cada uma dessas diferenças, assim como os princípios fundamentais de concepção da resposta a incidentes da AWS, serão detalhados nesta seção.
Aspectos da resposta a incidentes da AWS
Todos os usuários da AWS de uma organização devem ter uma compreensão básica dos processos de resposta a incidentes de segurança, e a equipe de segurança deve entender como responder aos problemas de segurança. Educação, treinamento e experiência são essenciais para um programa bem-sucedido de resposta a incidentes na nuvem e são preferencialmente implementados bem antes de precisar lidar com um possível incidente de segurança. A base de um programa bem-sucedido de resposta a incidentes na nuvem é composta por três pilares: Preparação, Operações e Atividades posteriores ao incidente.
Para entender cada um desses aspectos, considere as seguintes descrições:
-
Preparação: prepare sua equipe de resposta a incidentes para detectar e responder a incidentes dentro da AWS ao habilitar os controles de detecção e verificar o acesso adequado às ferramentas e aos serviços em nuvem necessários. Além disso, prepare os playbooks necessários, tanto os automatizados quanto os manuais, para garantir respostas confiáveis e consistentes.
-
Operações: atue sobre eventos de segurança e possíveis incidentes seguindo as fases de resposta a incidentes estabelecidas pelo NIST: detecção, análise, contenção, erradicação e recuperação.
-
Atividades posteriores ao incidente: realize a iteração com base nos resultados de seus eventos de segurança e simulações para melhorar a eficácia da resposta, aumentar o valor obtido das ações de resposta e de investigações, e reduzir ainda mais os riscos. Você precisa aprender com os incidentes e ter uma propriedade consistente das atividades de melhoria.
Cada um desses aspectos será explorado e detalhado neste guia. O diagrama apresentado a seguir mostra o fluxo desses aspectos, alinhando-se ao ciclo de vida da resposta a incidentes estabelecido pelo NIST e comentado anteriormente, mas com a fase de operações abrangendo a detecção e a análise, bem como a contenção, a erradicação e a recuperação.
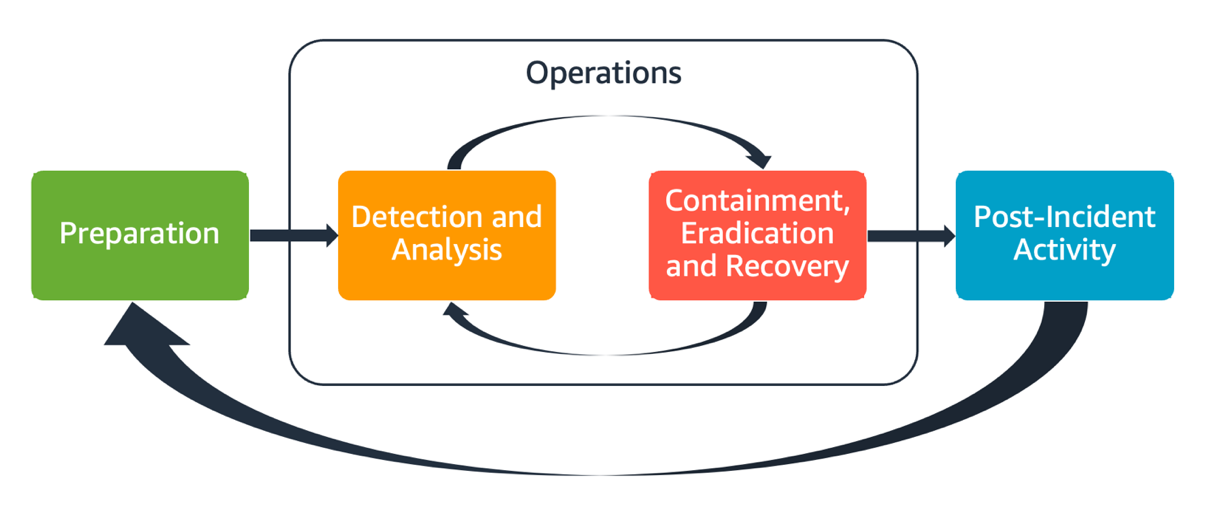
Aspectos da resposta a incidentes da AWS
Princípios e metas de concepção da resposta a incidentes da AWS
Embora os processos e os mecanismos gerais da resposta a incidentes definidos no guia NIST SP 800-61 – Computer Security Incident Handling Guide
-
Estabelecer objetivos de resposta: trabalhe em conjunto com as partes interessadas, a assessoria jurídica e a liderança da organização para determinar a meta da resposta a um incidente. Algumas metas comuns incluem conter e mitigar o problema, realizar a recuperação dos recursos afetados, preservar dados para fins forenses, restabelecer operações em um estado conhecido como seguro e, por fim, extrair aprendizados dos incidentes.
-
Responder usando a nuvem: implemente padrões de resposta diretamente na nuvem, que corresponde ao local em que os eventos e os dados são originados.
-
Ter clareza sobre seus recursos e sobre suas necessidades: preserve logs, recursos, snapshots e outras evidências ao copiar e realizar o armazenamento deles em uma conta centralizada na nuvem dedicada à resposta. Use tags, metadados e mecanismos que impõem políticas de retenção. É necessário compreender quais serviços estão em uso e, a partir disso, identificar os requisitos necessários para investigá-los. Para ajudar na compreensão do seu ambiente, você também pode empregar a marcação, conforme descrito posteriormente neste documento, na seção Desenvolva e implemente uma estratégia de marcação.
-
Usar mecanismos de reimplantação: se uma anomalia de segurança puder ser atribuída a uma configuração incorreta, a remediação pode ser tão simples quanto eliminar a divergência por meio da reimplantação dos recursos com a configuração adequada. Caso seja identificado um possível comprometimento, verifique se a nova implantação inclui a mitigação bem-sucedida e verificada das causas-raiz.
-
Automatizar sempre que possível: à medida que surgem problemas ou incidentes recorrentes, desenvolva mecanismos que realizem a triagem e a resposta programática para eventos comuns. Deixe os incidentes complexos, específicos ou sensíveis para resposta humana, visto que a automação não atinge o nível necessário de precisão.
-
Escolher soluções escaláveis: busque alinhar a escalabilidade da abordagem da sua organização à computação em nuvem. Implemente mecanismos de detecção e de resposta que escalam com base em diferentes ambientes, a fim de reduzir de forma eficaz o tempo entre a detecção e a resposta.
-
Aprender e aprimorar seu processo: adote uma postura proativa na identificação de lacunas em seus processos, ferramentas ou equipe, e implemente um plano para corrigi-las. As simulações são métodos seguros para realizar a descoberta de falhas e aprimorar os processos. Consulte a seção Atividade pós-incidente deste documento para obter mais detalhes sobre como efetuar a iteração dos seus processos.
Essas metas de design são um lembrete para analisar a implementação de sua arquitetura quanto à capacidade de conduzir tanto a resposta a incidentes quanto a detecção de ameaças. Durante o planejamento das implementações na nuvem, considere a necessidade de responder a incidentes, preferencialmente por meio de uma metodologia que preserve a integridade forense. Em alguns casos, isso pode significar a existência de diversas organizações, contas e ferramentas configuradas especificamente para executar essas tarefas de resposta. Essas ferramentas e funções devem ser disponibilizadas para a equipe de atendimento a incidentes por meio do pipeline de implantação. Elas não devem ser estáticas, pois podem causar um risco maior.
Domínios relacionados aos incidentes de segurança na nuvem
Para se preparar e responder a eventos de segurança em seu ambiente da AWS de forma eficaz, é essencial compreender os tipos mais comuns de incidentes de segurança na nuvem. Existem três domínios sob a responsabilidade do cliente nos quais incidentes de segurança podem ocorrer, nomeadamente, serviço, infraestrutura e aplicação. Cada domínio requer conhecimentos, ferramentas e processos de resposta distintos. Considere os seguintes domínios:
-
Domínio de serviço: incidentes no domínio de serviço podem afetar a conta da Conta da AWS, as permissões do AWS Identity and Access Management
(IAM), os metadados de recursos, o faturamento ou outras áreas. Um evento no domínio de serviço consiste em um evento que é tratado exclusivamente por meio de mecanismos da API da AWS ou cuja causa-raiz está associada à configuração ou às permissões de recursos, podendo envolver registros de log relacionados a serviços. -
Domínio de infraestrutura: incidentes no domínio de infraestrutura incluem atividades relacionadas aos dados ou à rede, como processos e dados em instâncias do Amazon Elastic Compute Cloud
(Amazon EC2), tráfego direcionado a essas instâncias do Amazon EC2 dentro de uma nuvem privada virtual (VPC), além de outras áreas, como contêineres ou outros serviços futuros. A resposta aos eventos no domínio de infraestrutura geralmente envolve a aquisição de dados relacionados ao incidente para análise forense. Além disso, a resposta frequentemente requer interação com o sistema operacional da instância e, em diversos casos, pode envolver também mecanismos da API da AWS. No domínio de infraestrutura, é possível combinar o uso de APIs da AWS com ferramentas de resposta a incidentes e forense digital (DFIR, na sigla em inglês) executadas dentro de um sistema operacional convidado, como uma instância do Amazon EC2 dedicada à realização de análises e de investigações forenses. Os incidentes no domínio de infraestrutura podem envolver a análise de capturas de pacotes de rede, blocos de disco em volumes do Amazon Elastic Block Store (Amazon EBS) ou memória volátil adquirida de uma instância. -
Domínio de aplicação: incidentes no domínio de aplicação ocorrem no código da aplicação ou em softwares implantados para os serviços ou para a infraestrutura. Esse domínio deve ser incluído em seus planos de ação de detecção e de resposta a ameaças na nuvem e pode incorporar respostas semelhantes às apresentadas no domínio de infraestrutura. Com uma arquitetura de aplicação bem planejada e adequada, é possível gerenciar esse domínio ao usar ferramentas em nuvem por meio da aquisição, da recuperação e da implantação automatizadas.
Nesses domínios, considere os agentes que podem representar ameaças às contas, aos recursos ou aos dados na AWS. Sejam internos ou externos, use uma estrutura de gerenciamento de riscos para determinar os riscos específicos à organização e se preparar adequadamente. Além disso, você deve realizar o desenvolvimento de modelos de ameaças, que podem auxiliar no planejamento da resposta a incidentes e na criação de arquiteturas com melhor planejamento.
Principais diferenças na resposta a incidentes na AWS
A resposta a incidentes constitui uma parte essencial da estratégia de segurança da cibernética, aplicável tanto em ambientes on-premises quanto na nuvem. Os princípios de segurança, como o privilégio mínimo e a defesa em profundidade, têm o objetivo de proteger a confidencialidade, a integridade e a disponibilidade dos dados tanto em ambientes on-premises quanto na nuvem. Diversos padrões de resposta a incidentes que apoiam esses princípios de segurança seguem esse exemplo, incluindo a retenção de log, a seleção de alertas baseada em modelagem de ameaças, o desenvolvimento de planos de ação e a integração com o gerenciamento de informações e de eventos de segurança (SIEM, na sigla em inglês). As diferenças surgem quando os clientes começam a projetar e a desenvolver esses padrões na nuvem. A seguir, apresentamos as principais diferenças da resposta a incidentes na AWS.
Diferença n.º 1: segurança como uma responsabilidade compartilhada
A responsabilidade pela segurança e pela conformidade é compartilhada entre a AWS e seus clientes. Esse modelo de responsabilidade compartilhada reduz parte da carga operacional do cliente, pois a AWS opera, gerencia e controla os componentes desde o sistema operacional do host e a camada de virtualização até a segurança física das instalações nas quais o serviço é prestado. Para obter mais detalhes sobre o modelo de responsabilidade compartilhada, consulte a documentação do Modelo de responsabilidade compartilhada
À medida que a sua responsabilidade compartilhada na nuvem evolui, as opções para a resposta a incidentes também se transformam. O planejamento e a compreensão dessas compensações, combinados com suas necessidades de governança, são etapas fundamentais na resposta a incidentes.
Além da relação direta que você mantém com a AWS, pode haver outras entidades que tenham responsabilidades em seu modelo de responsabilidade específico. Por exemplo, você pode contar com unidades organizacionais internas que assumem a responsabilidade por determinados aspectos de suas operações. Além disso, é possível que você mantenha relações com outras partes que desenvolvem, gerenciam ou operam parte da sua tecnologia em nuvem.
A criação e a realização de testes de um plano de resposta a incidentes adequado, assim como planos de ação apropriados que estejam alinhados ao seu modelo operacional, é de extrema importância.
Diferença n.º 2: domínio de serviço em nuvem
Devido às diferenças presentes nas responsabilidades de segurança existentes nos serviços em nuvem, foi introduzido um novo domínio para incidentes de segurança, denominado o domínio de serviço, conforme explicado anteriormente na seção Domínios relacionados aos incidentes. O domínio de serviço abrange a conta da AWS do cliente, as permissões do IAM, os metadados de recursos, o faturamento e outras áreas. Esse domínio é distinto no contexto da resposta a incidentes devido à forma como a resposta é conduzida. Geralmente, a resposta no domínio de serviço é realizada por meio da análise e da emissão de chamadas de API, em vez de abordagens de respostas tradicionais baseadas em host e em rede. No domínio de serviço, não há interação direta com o sistema operacional de um recurso afetado.
O diagrama apresentado a seguir mostra um exemplo de um evento de segurança no domínio de serviço baseado em um antipadrão de arquitetura. Nesse evento, um usuário não autorizado obtém as credenciais de segurança de longo prazo de um usuário do IAM. O usuário do IAM tem uma política do IAM que permite a recuperação de objetos de um bucket do Amazon Simple Storage Service
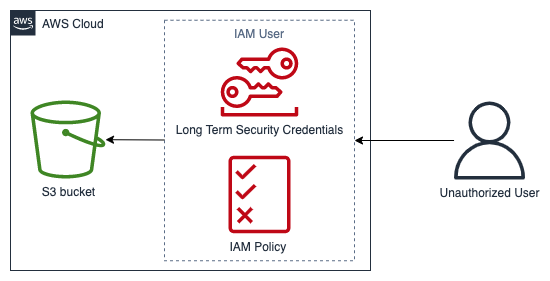
Exemplo de domínio de serviço
Diferença n.º 3: APIs para provisionamento de infraestrutura
Uma outra diferença decorre da natureza sob demanda e de autoatendimento da computação em nuvem
Devido à natureza baseada em APIs da AWS, uma fonte de log importante para a resposta a eventos de segurança é o AWS CloudTrail, que acompanha as chamadas à API de gerenciamento realizadas em suas contas da AWS e fornece informações sobre a localização de origem dessas chamadas de API.
Diferença n.º 4: natureza dinâmica da nuvem
A nuvem é dinâmica, portanto, ela permite a criação e a exclusão de recursos rapidamente. Com a escalabilidade automática, os recursos podem ser provisionados ou encerrados conforme a demanda de tráfego. Devido à natureza transitória da infraestrutura e à rapidez das alterações, o recurso que está sendo investigado pode já não existir mais ou ter sido modificado. Compreender a natureza efêmera dos recursos da AWS, bem como saber como acompanhar a criação e a exclusão dos recursos da AWS, será importante para a análise de incidentes. Você pode usar o AWS Config
Diferença n.º 5: acesso aos dados
O acesso aos dados também é diferente na nuvem. Não é possível conectar-se diretamente a um servidor para coletar os dados necessários para uma investigação de segurança. Os dados são coletados por meio de tráfego de rede e de chamadas de API. É fundamental praticar e compreender como realizar a coleta de dados por meio de APIs para estar com tudo preparado para essa mudança, além de garantir o armazenamento adequado para uma coleta e para um acesso eficazes.
Diferença n.º 6: importância da automação
Para que os clientes possam aproveitar plenamente os benefícios da adoção da nuvem, sua estratégia operacional deve incorporar a automação. A infraestrutura como código (IaC) consiste em um padrão de ambientes altamente eficientes e automatizados, nos quais os serviços da AWS são implantados, configurados, reconfigurados e destruídos por meio de código, utilizando serviços nativos de IaC, como o AWS CloudFormation
Como abordar essas diferenças
Para abordar essas diferenças, siga as etapas descritas na próxima seção para garantir que seu programa de resposta a incidentes, contemplando pessoas, processos e tecnologias, esteja adequadamente preparado.
