As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimização do desempenho do modelo com SageMaker o Neo
O Neo é um recurso da Amazon SageMaker AI que permite que modelos de aprendizado de máquina sejam treinados uma vez e executados em qualquer lugar na nuvem e na borda.
Se você é um usuário iniciante do SageMaker Neo, recomendamos que confira a seção Introdução aos dispositivos Edge para obter instruções passo a passo sobre como compilar e implantar em um dispositivo de ponta.
O que é SageMaker Neo?
Geralmente, otimizar modelos de machine learning para inferência em múltiplas plataformas é difícil, pois você precisa ajustar manualmente os modelos para a configuração específica de hardware e software de cada plataforma. Se você deseja obter um desempenho ideal para uma determinada workload, é necessário conhecer a arquitetura de hardware, o conjunto de instruções, os padrões de acesso à memória e os formatos dos dados de entrada, entre outros fatores. Para o desenvolvimento tradicional de softwares, ferramentas como compiladores e criadores de perfis simplificam o processo. Para machine learning, a maioria das ferramentas é específica da estrutura ou do hardware. Isso força você a um processo manual de tentativa e erro que não é confiável e é improdutivo.
O Neo otimiza automaticamente os modelos Gluon, Keras, MXNet,, PyTorch TensorFlow TensorFlow-Lite, e ONNX para inferência em máquinas Android, Linux e Windows com base em processadores da Ambarella, ARM, Intel, Nvidia, NXP, Qualcomm, Texas Instruments e Xilinx. O Neo é testado com modelos de visão computacional disponíveis nos zoológicos de modelos em todas as estruturas. SageMaker O Neo suporta compilação e implantação para duas plataformas principais: instâncias de nuvem (incluindo Inferentia) e dispositivos de ponta.
Para obter mais informações sobre estruturas compatíveis e tipos de instância de nuvem nos quais você pode implantar, consulte Tipos e estruturas de instância compatíveis para ver as instâncias de nuvem.
Para obter mais informações sobre estruturas suportadas, dispositivos de ponta, sistemas operacionais, arquiteturas de chip e modelos comuns de aprendizado de máquina testados pelo SageMaker AI Neo para dispositivos de borda, consulte Estruturas, dispositivos, sistemas e arquiteturas compatíveis para dispositivos de borda.
Como funciona
O Neo consiste em um compilador e um runtime. Em primeiro lugar, a API de compilação do Neo lê modelos exportados de várias estruturas. Ele converte as funções e operações específicas da estrutura em uma representação intermediária agnóstica à estrutura. Feito isso, ele realiza uma série de otimizações. Em seguida, ele gera código binário para as operações otimizadas, grava-as em uma biblioteca de objetos compartilhados e salva a definição e os parâmetros do modelo em arquivos separados. O Neo também fornece um runtime para cada plataforma de destino que carrega e executa o modelo compilado.
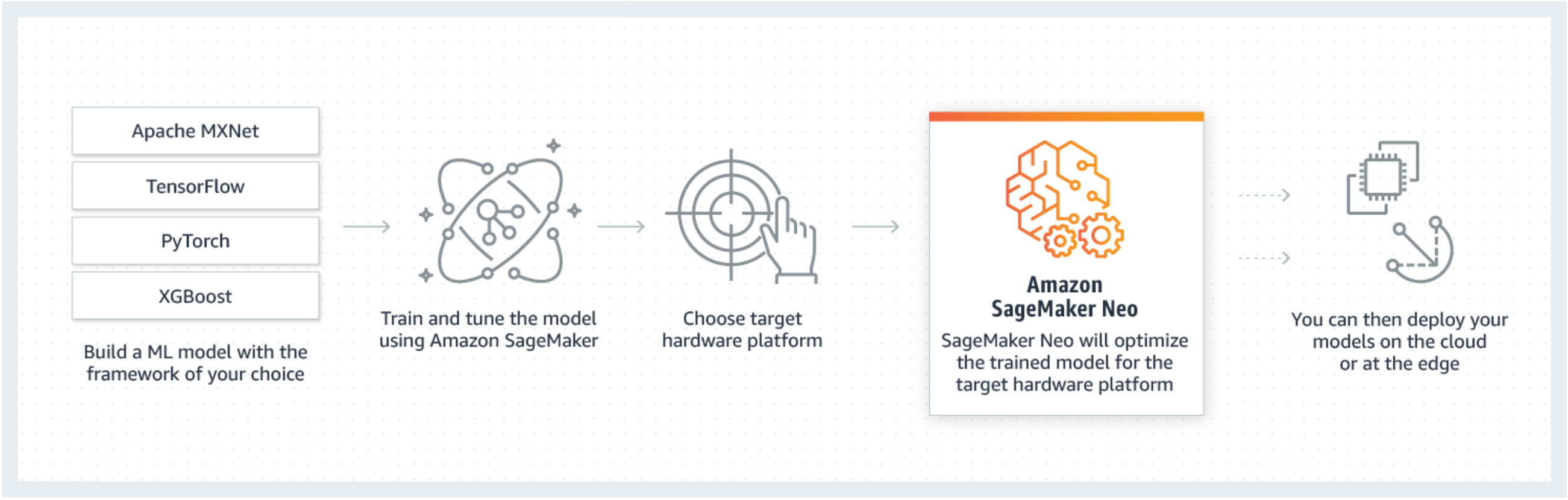
Você pode criar um trabalho de compilação Neo a partir do console SageMaker AI, do AWS Command Line Interface (AWS CLI), de um notebook Python ou SageMaker das informações de SDK.For IA sobre como compilar um modelo, consulte. Compilação de modelos com Neo Com alguns comandos da CLI, uma invocação de API ou alguns cliques, você pode converter um modelo para a plataforma escolhida. Você pode implantar o modelo em um endpoint de SageMaker IA ou em um AWS IoT Greengrass dispositivo rapidamente.
O Neo pode otimizar modelos com parâmetros em FP32 ou quantizados para a largura de bits INT8 ou FP16.
