As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Mapeamento de caminhos de armazenamento de treinamento gerenciados pela Amazon SageMaker AI
Esta página fornece um resumo de alto nível de como a plataforma de SageMaker treinamento gerencia caminhos de armazenamento para conjuntos de dados de treinamento, artefatos de modelos, pontos de verificação e saídas entre armazenamento em AWS nuvem e trabalhos de treinamento em IA. SageMaker Ao longo deste guia, você aprende a identificar os caminhos padrão definidos pela plataforma de SageMaker IA e como os canais de dados podem ser simplificados com suas fontes de dados no Amazon Simple Storage Service (Amazon S3), FSx for Lustre e Amazon EFS. Para obter mais informações sobre opções de armazenamento e modos de entrada de canais de dados, consulte Como configurar trabalhos de treinamento para acessar conjuntos de dados.
Visão geral de como a SageMaker IA mapeia os caminhos de armazenamento
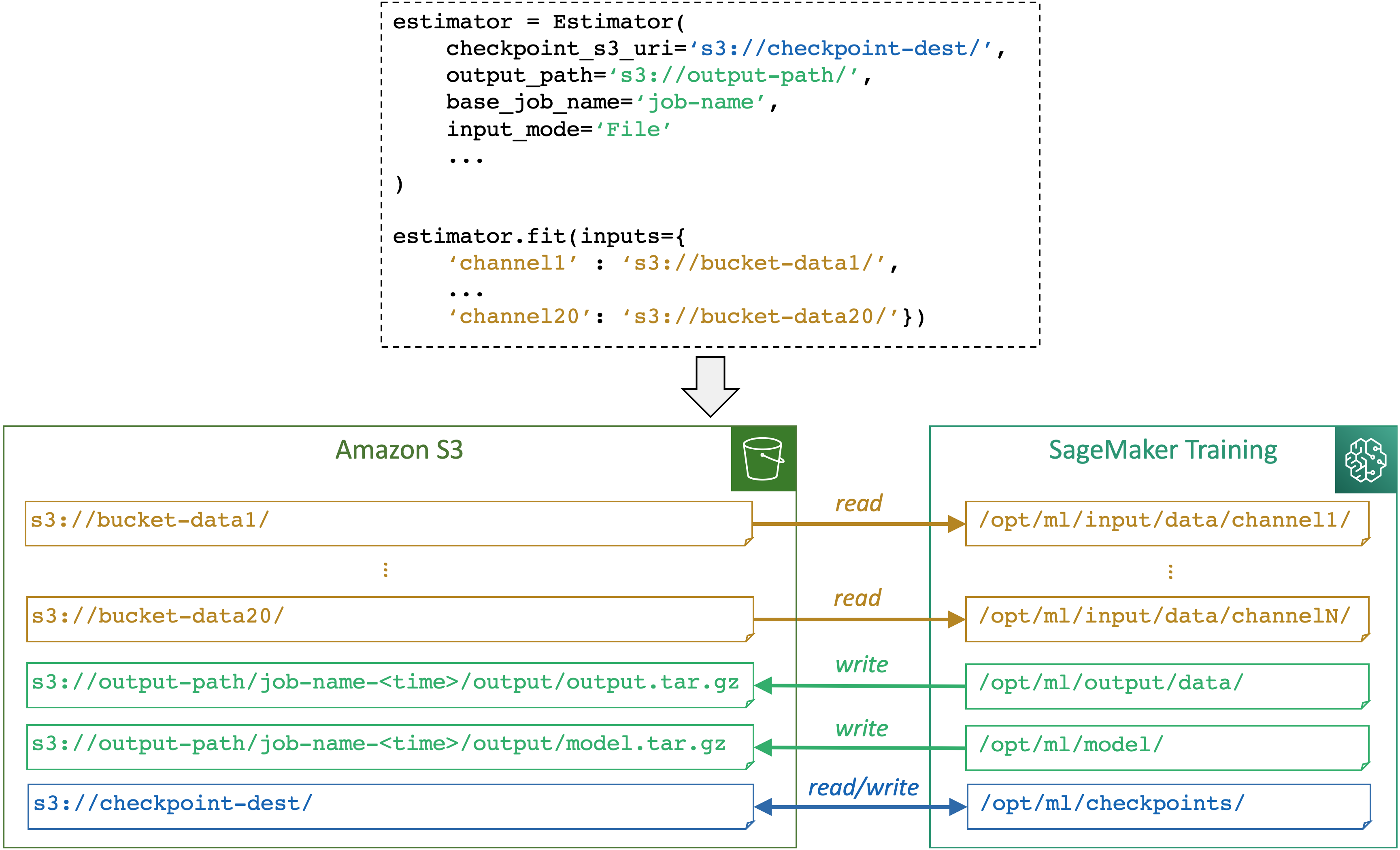
SageMaker A IA mapeia os caminhos de armazenamento entre um armazenamento (como Amazon S3, Amazon FSx e Amazon EFS) e o contêiner de SageMaker treinamento com base nos caminhos e no modo de entrada especificados por meio de um SageMaker objeto estimador de IA. Mais informações sobre como a SageMaker IA lê ou grava nos caminhos e a finalidade dos caminhos, consulteSageMaker Variáveis de ambiente de IA e os caminhos padrão para locais de armazenamento de treinamento.
Você pode usar OutputDataConfig na CreateTrainingJobAPI para salvar os resultados do treinamento do modelo em um bucket do S3. Use a ModelArtifactsAPI para encontrar o bucket do S3 que contém os artefatos do seu modelo. Consulte o caderno abalone_build_train_deploy
Para obter mais informações e exemplos de como a SageMaker IA gerencia a fonte de dados, os modos de entrada e os caminhos locais em instâncias de SageMaker treinamento, consulte Acessar dados de treinamento.
Tópicos
