As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Como configurar trabalhos de treinamento para acessar conjuntos de dados
Ao criar um trabalho de treinamento, você especifica a localização dos conjuntos de dados de treinamento em um armazenamento de dados de sua escolha e o modo de entrada de dados para o trabalho. O Amazon SageMaker AI oferece suporte ao Amazon Simple Storage Service (Amazon S3), ao Amazon Elastic File System (Amazon EFS) e ao Amazon FSx for Lustre. Você pode escolher um dos modos de entrada para transmitir o conjunto de dados em tempo real ou baixar todo o conjunto de dados no início do trabalho de treinamento.
nota
Seu conjunto de dados deve residir no mesmo Região da AWS local do trabalho de treinamento.
SageMaker Modos de entrada AI e AWS opções de armazenamento em nuvem
Esta seção fornece uma visão geral dos modos de entrada de arquivos suportados SageMaker pelos dados armazenados no Amazon EFS e no Amazon FSx for Lustre.
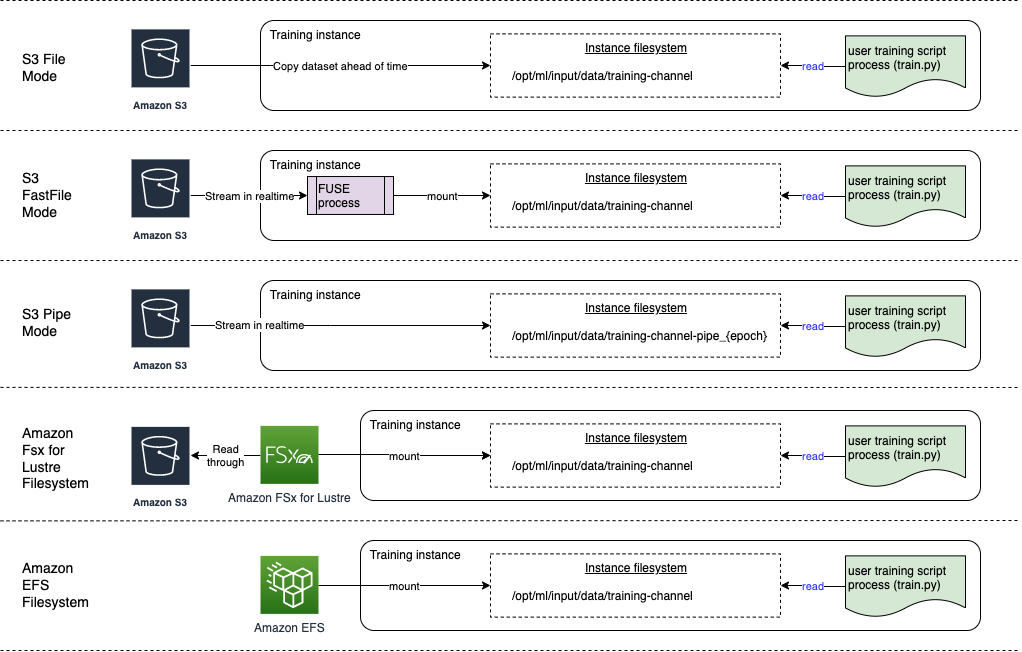
-
O modo de arquivo apresenta uma visualização do sistema de arquivos do conjunto de dados para o contêiner de treinamento. Esse é o modo de entrada padrão se você não especificar explicitamente uma das outras duas opções. Se você usa o modo de arquivo, o SageMaker AI baixa os dados de treinamento do local de armazenamento para um diretório local no contêiner do Docker. O treinamento começa após o download do conjunto de dados completo. No modo de arquivo, a instância de treinamento deve ter espaço de armazenamento suficiente para caber em todo o conjunto de dados. A velocidade de download do modo de arquivo depende do tamanho do conjunto de dados, do tamanho médio dos arquivos e do número de arquivos. Você pode configurar o conjunto de dados para o modo de arquivo fornecendo um prefixo, arquivo de manifesto ou arquivo de manifesto aumentado do Amazon S3. Use um prefixo S3 quando todos os arquivos do conjunto de dados estiverem localizados em um prefixo S3 comum. O modo de arquivo é compatível com o modo local de SageMaker IA
(iniciando um contêiner de SageMaker treinamento interativamente em segundos). Para treinamento distribuído, você pode fragmentar o conjunto de dados em várias instâncias com a opção ShardedByS3Key. -
O modo de arquivo rápido dá acesso ao sistema de arquivos a uma fonte de dados do Amazon S3 enquanto aproveita a vantagem de desempenho do modo pipe. No início do treinamento, o modo de arquivo rápido identifica os arquivos de dados, mas não os baixa. O treinamento pode começar sem esperar o download de todo o conjunto de dados. Isso significa que o startup do treinamento leva menos tempo quando há menos arquivos no prefixo Amazon S3 fornecido.
Em contraste com o modo pipe, o modo de arquivo rápido funciona com acesso randomizado aos dados. No entanto, funciona melhor quando os dados são lidos sequencialmente. O modo de arquivo rápido não é compatível com arquivos de manifesto aumentados.
O modo de arquivo rápido expõe objetos do S3 usando uma interface de sistema de POSIX-compliant arquivos, como se os arquivos estivessem disponíveis no disco local da sua instância de treinamento. Ele transmite conteúdo do S3 sob demanda à medida que seu script de treinamento consome dados. Isso significa que seu conjunto de dados não precisa mais caber no espaço de armazenamento da instância de treinamento como um todo, e você não precisa esperar que o conjunto de dados seja baixado para a instância de treinamento antes do início do treinamento. Atualmente, o Fast File é compatível apenas com prefixos S3 (não é compatível com manifesto e manifesto aumentado). O modo de arquivo rápido é compatível com o modo local SageMaker AI.
nota
Usar o modo Fast File pode aumentar CloudTrail os custos devido ao registro adicional de:
-
Eventos de dados do Amazon S3 (se habilitado em CloudTrail).
-
AWS KMS eventos de descriptografia ao acessar objetos do Amazon S3 criptografados com chaves. AWS KMS
-
Eventos de gerenciamento relacionados às AWS KMS operações.
Revise seus custos de CloudTrail configuração e monitoramento se você tiver o CloudTrail registro habilitado para esses tipos de eventos.
-
-
O modo Pipe transmite dados diretamente de uma fonte de dados do Amazon S3. O streaming pode proporcionar tempos de inicialização mais rápidos um throughput melhor que o modo de arquivo.
Ao transmitir os dados diretamente, você pode reduzir o tamanho dos volumes do Amazon EBS usados pela instância de treinamento. O modo de Pipe precisa apenas de espaço em disco suficiente para armazenar os artefatos de modelo finais.
É outro modo de streaming que é amplamente substituído pelo modo de arquivo rápido mais novo e mais simples de usar. No modo pipe, os dados são pré-obtidos do Amazon S3 com alta simultaneidade e taxa de transferência e transmitidos para um canal nomeado, também conhecido como canal (FIFO) por seu First-In-First-Out comportamento. Cada pipe só pode ser lido por um único processo. Uma extensão específica de SageMaker IA que integra TensorFlow convenientemente o modo Pipe ao carregador de TensorFlow dados nativo
para streaming de texto, TFRecords ou formatos de arquivo Recordio. O modo Pipe também é compatível com fragmentação e embaralhamento de dados gerenciados. -
O Amazon S3 Express One Zone é uma classe de armazenamento de zona de disponibilidade única e alto desempenho que pode fornecer acesso consistente a dados de um dígito em milissegundos para os aplicativos mais sensíveis à latência, incluindo treinamento de modelos. SageMaker O Amazon S3 Express One Zone permite que os clientes coloquem seus recursos computacionais e de armazenamento de objetos em uma única zona de AWS disponibilidade, otimizando o desempenho e os custos computacionais com maior velocidade de processamento de dados. Para aumentar ainda mais a velocidade de acesso e oferecer compatibilidade com centenas de milhares de solicitações por segundo, os dados são armazenados em um novo tipo de bucket: um bucket de diretório do Amazon S3.
SageMaker O treinamento do modelo de IA oferece suporte a buckets de diretório One Zone do Amazon S3 Express de alto desempenho como um local de entrada de dados para o modo de arquivo, modo de arquivo rápido e modo pipe. Para usar o Amazon S3 Express One Zone, insira a localização do bucket do diretório Amazon S3 Express One Zone, em vez de um bucket do Amazon S3. Forneça o ARN para o perfil do IAM com o controle de acesso e a política de permissões necessários. Para mais detalhes, consulte AmazonSageMakerFullAccesspolicy. Você só pode criptografar seus dados de saída de SageMaker IA em buckets de diretório com criptografia do lado do servidor com chaves gerenciadas do Amazon S3 (). SSE-S3 Server-side Atualmente, a criptografia com AWS KMS keys (SSE-KMS) não é suportada para armazenar dados de saída de SageMaker IA em buckets de diretório. Para obter mais informações, consulte Amazon S3 Express One Zone.
-
Amazon FSx para Lustre: O FSx para Lustre pode ser escalado para centenas de gigabytes de throughput e milhões de IOPS com recuperação de arquivos de baixa latência. Ao iniciar um trabalho de treinamento, a SageMaker IA monta o sistema de arquivos FSx for Lustre no sistema de arquivos da instância de treinamento e inicia seu script de treinamento. A montagem em si é uma operação relativamente rápida que não depende do tamanho do conjunto de dados armazenado no FSx for Lustre.
Para acessar o FSx for Lustre, seu trabalho de treinamento deve se conectar a uma Amazon Virtual Private Cloud (VPC), o que requer configuração DevOps e envolvimento. Para evitar custos de transferência de dados, o sistema de arquivos usa uma única zona de disponibilidade e você precisa especificar uma sub-rede VPC que mapeie essa ID da zona de disponibilidade ao executar o trabalho de treinamento.
-
Amazon EFS — Para usar o Amazon EFS como fonte de dados, os dados já devem residir no Amazon EFS antes do treinamento. SageMaker A IA monta o sistema de arquivos Amazon EFS especificado na instância de treinamento e, em seguida, inicia seu script de treinamento. Seu trabalho de treinamento deve se conectar a uma VPC para acessar o Amazon EFS.
dica
Para saber mais sobre como especificar sua configuração de VPC para estimadores de SageMaker IA, consulte Usar sistemas de arquivos como entradas de treinamento na
documentação do SDK para AI SageMaker Python.
