As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Exportar dados usando o AWS Glue
Você pode arquivar dados do MySQL no Amazon S3 usando o AWS Glue, que é um serviço analítico sem servidor para cenários de big data. O AWS Glue é baseado no Apache Spark, um framework de computação em cluster distribuída amplamente usada compatível com muitas fontes de banco de dados.
O descarregamento de dados arquivados do banco de dados para o Amazon S3 pode ser realizado com algumas linhas de código em um trabalho do AWS Glue. A maior vantagem que o AWS Glue oferece é a escalabilidade horizontal e um pay-as-you-go modelo, fornecendo eficiência operacional e otimização de custos.
O diagrama a seguir mostra uma arquitetura básica para arquivamento do banco de dados.
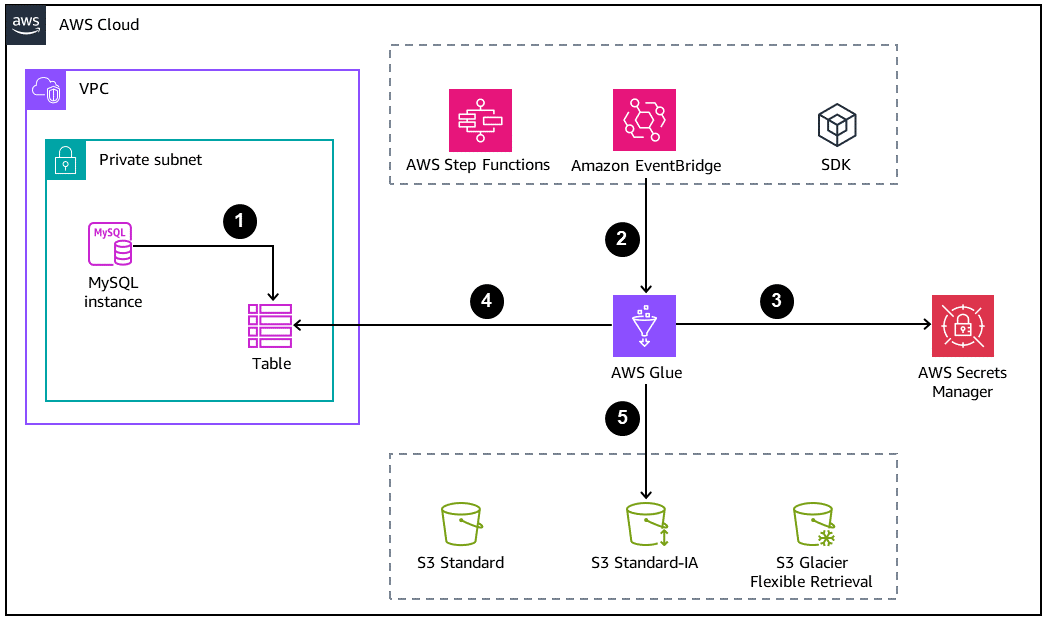
-
O banco de dados MySQL cria o arquivo ou a tabela de backup para ser descarregada no Amazon S3.
-
Um trabalho do AWS Glue é iniciado por uma das seguintes abordagens:
-
De forma síncrona, como uma etapa dentro de uma máquina de estado do AWS Step Functions
-
Por meio de uma solicitação manual usando a AWS CLI ou um AWS SDK
-
-
As credenciais do banco de dados são recuperadas do AWS Secrets Manager.
-
O trabalho do AWS Glue usa uma conexão Java Database Connectivity (JDBC) para acessar o banco de dados e ler a tabela.
-
O AWS Glue grava os dados no Amazon S3 no formato Parquet, que é um formato de dados aberto, colunar e que economiza espaço.
Configuração do trabalho do AWS Glue
Para funcionar conforme o esperado, o trabalho do AWS Glue exige os seguintes componentes e configurações:
-
Conexões do AWS Glue: este é um objeto do Catálogo de Dados do AWS Glue que você anexa ao trabalho para acessar o banco de dados. Um trabalho pode ter várias conexões para fazer chamadas para vários bancos de dados. As conexões contêm as credenciais do banco de dados armazenadas com segurança.
-
GlueContext— Este é um invólucro personalizado sobre SparkContext
a GlueContext classe que fornece operações de API de ordem superior para interagir com o Amazon S3 e fontes de banco de dados. Ele permite a integração com o Catálogo de Dados. Também elimina a necessidade de depender de drivers para conexão com o banco de dados, que é feita na conexão do Glue. Além disso, a GlueContext classe fornece maneiras de lidar com as operações de API do Amazon S3, o que não é possível com a classe original SparkContext . -
Políticas e perfis do IAM: como o AWS Glue interage com outros serviços da AWS, você deve configurar perfis apropriados com o privilégio mínimo necessário. Os serviços que exigem permissões apropriadas para interagir com o AWS Glue incluem o seguinte:
-
Amazon S3
-
AWS Secrets Manager
-
AWS Key Management Service (AWS KMS)
-
Práticas recomendadas
-
Para ler tabelas inteiras que têm um grande número de linhas a serem descarregadas, recomendamos usar o endpoint da réplica de leitura para aumentar o throughput de leitura sem prejudicar a performance da instância principal do gravador.
-
Para obter eficiência no número de nós usados para processar o trabalho, ative o ajuste de escala automático no AWS Glue 3.0.
-
Se o bucket do S3 fizer parte da arquitetura do data lake, recomendamos descarregar os dados organizando-os em partições físicas. O esquema de partição deve ser baseado nos padrões de acesso. O particionamento com base em valores de data é uma das práticas mais recomendadas.
-
Salvar os dados em formatos abertos, como Parquet ou Optimized Row Columnar (ORC), ajuda a disponibilizar os dados para outros serviços de analytics, como o Amazon Athena e Amazon Redshift.
-
Para que os dados descarregados sejam otimizados para leitura por outros serviços distribuídos, o número de arquivos de saída deve ser controlado. Geralmente, é mais eficiente ter um número menor de arquivos maiores em vez de um grande número de arquivos pequenos. O Spark tem arquivos de configuração e métodos integrados para controlar a geração de arquivos parciais.
-
Os dados arquivados, por definição, são conjuntos de dados frequentemente acessados. Para obter eficiência de custo para armazenamento, a classe do Amazon S3 deve ser transferida para níveis mais baratos. Isso pode ser feito usando duas abordagens:
-
Transição síncrona do nível durante o descarregamento — Se você souber de antemão que os dados descarregados devem ser transferidos como parte do processo, você pode usar o mecanismo transition_s3_path no mesmo trabalho do AWS Glue que grava os dados GlueContext no Amazon S3.
-
Transição assíncrona usando o S3 Lifecycle: configure as regras do S3 Lifecycle com os parâmetros apropriados para a transição e expiração da classe de armazenamento do Amazon S3. Depois que isso for configurado no bucket, ele persistirá para sempre.
-
-
Crie e configure uma sub-rede com um intervalo de endereços IP suficiente
na nuvem privada virtual (VPC) em que o banco de dados está implantado. Isso evitará falhas de trabalho do AWS Glue causadas por um número insuficiente de endereços de rede quando um grande número de unidades de processamento de dados (DPUs) estiver configurado.
