As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
O que é Amazon OpenSearch Serverless?
O Amazon OpenSearch Serverless é uma opção sob demanda e sem servidor para o OpenSearch Amazon Service que elimina a complexidade operacional do provisionamento, configuração e ajuste de clusters. OpenSearch É ideal para organizações que preferem não autogerenciar seus clusters ou que não têm recursos e expertise dedicados para operar implantações em grande escala. Com o OpenSearch Serverless, você pode pesquisar e analisar grandes volumes de dados sem gerenciar a infraestrutura subjacente.
Uma coleção OpenSearch sem servidor é um grupo de OpenSearch índices que trabalham juntos para dar suporte a uma carga de trabalho ou caso de uso específico. As coleções simplificam as operações em comparação com OpenSearch clusters autogerenciados, que exigem provisionamento manual.
As coleções usam o mesmo armazenamento de alta capacidade, distribuído e altamente disponível dos domínios de OpenSearch serviços provisionados, mas reduzem ainda mais a complexidade ao eliminar a configuração e o ajuste manuais. Toda comunicação com endpoints OpenSearch sem servidor usa criptografia TLS 1.2, garantindo que os dados sejam criptografados em trânsito do cliente para o endpoint. Os dados também são criptografados em trânsito entre os componentes internos de uma coleção. OpenSearch O Serverless também oferece suporte a OpenSearch painéis, fornecendo uma interface para análise de dados.
OpenSearch O Serverless é compatível com código aberto. OpenSearch À medida que novas versões são lançadas, o OpenSearch Serverless atualiza automaticamente as coleções para incorporar novos recursos, correções de erros e melhorias de desempenho.
OpenSearch O Serverless suporta as mesmas operações de API de ingestão e consulta do pacote de código OpenSearch aberto, para que você possa continuar usando seus clientes e aplicativos existentes. Seus clientes devem ser compatíveis com OpenSearch 3.x para trabalhar com o OpenSearch Serverless. Para obter mais informações, consulte Ingestão de dados em coleções Amazon OpenSearch Serverless.
Tópicos
Casos de uso do OpenSearch Serverless
OpenSearch O Serverless oferece suporte a dois casos de uso principais:
-
Análise de logs: o segmento de analytics de logs se concentra na análise de grandes volumes de dados de séries temporais, semiestruturados e gerados por máquina para obter informações operacionais e de comportamento do usuário.
-
Full-text pesquisa - O segmento de pesquisa de texto completo capacita aplicativos em suas redes internas (sistemas de gerenciamento de conteúdo, documentos legais) e aplicativos voltados para a Internet, como a pesquisa de conteúdo em sites de comércio eletrônico.
Ao criar uma coleção, escolha um desses casos de uso. Para saber mais, consulte Escolha de um tipo de coleção.
Como funciona
OpenSearch Os clusters tradicionais têm um único conjunto de instâncias que realizam operações de indexação e pesquisa, e o armazenamento de índices está estreitamente associado à capacidade computacional. Por outro lado, o OpenSearch Serverless usa uma arquitetura nativa da nuvem que separa os componentes de indexação (ingestão) dos componentes de pesquisa (consulta), com o Amazon S3 como principal armazenamento de dados para índices.
Essa arquitetura desacoplada permite escalar as funções de pesquisa e indexação de forma independente uma da outra e independentemente dos dados indexados no S3. A arquitetura também fornece isolamento para operações de ingestão e consulta para que elas possam ser executadas simultaneamente, sem contenção de recursos.
Quando você grava dados em uma coleção, o OpenSearch Serverless os distribui para as unidades computacionais de indexação. As unidades computacionais de indexação ingerem os dados recebidos e movem os índices para S3. Quando você realiza uma pesquisa nos dados da coleta, o OpenSearch Serverless encaminha as solicitações para as unidades computacionais de pesquisa que contêm os dados que estão sendo consultados. As unidades computacionais de pesquisa baixam os dados indexados diretamente do S3 (se ainda não estiverem armazenados em cache localmente), executam operações de pesquisa e realizam agregações.
A imagem a seguir ilustra essa arquitetura desacoplada:
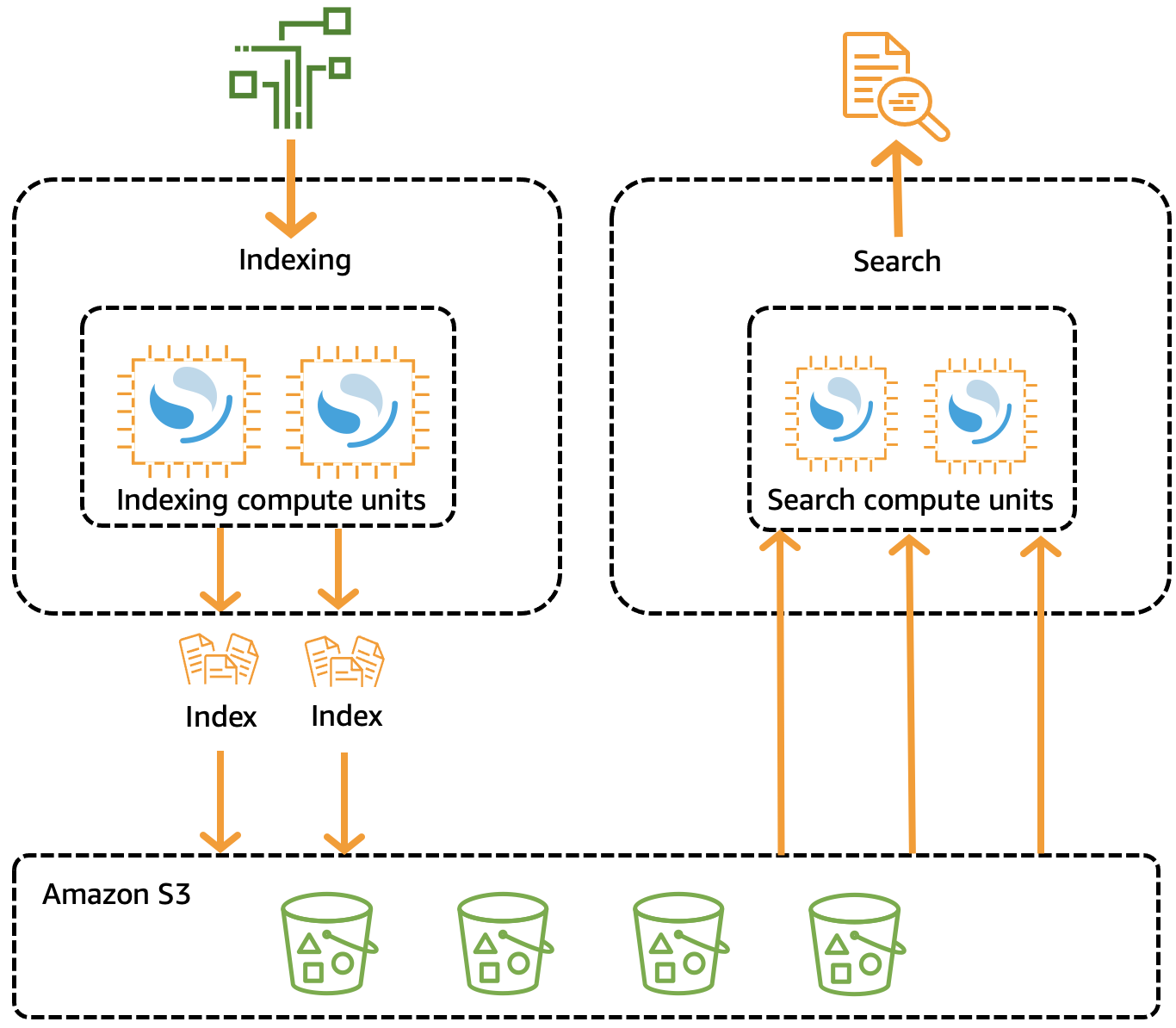
OpenSearch A capacidade computacional sem servidor para ingestão, pesquisa e consulta de dados é medida em unidades de OpenSearch computação (OCUs). Cada OCU é uma combinação de 6 GiB de memória e CPU virtual (vCPU) correspondente e cria um pipeline de dados para o Amazon S3.
OpenSearch O Serverless provisiona OCUs separadamente para pesquisa e indexação. OpenSearch O Serverless adiciona apenas OCUs adicionais para pesquisa e ingestão, conforme necessário, para dar suporte às coleções, de acordo com os limites de capacidade que você especificar. A capacidade é reduzida à medida que o uso da computação diminui.
Para obter informações sobre como você é cobrado por essas OCUs, consulte os preços do Amazon OpenSearch Service
Escolha de um tipo de coleção
OpenSearch O Serverless oferece suporte a três tipos principais de coleção:
Séries temporais: o segmento de analytics de log que analisa em tempo real grandes volumes de dados semiestruturados gerados por máquinas, fornecendo insights sobre operações, segurança, comportamento do usuário e desempenho dos negócios.
nota
As coleções de séries temporais só estão disponíveis para coleções clássicas. NextGenNo momento, as coleções suportam somente os tipos de pesquisa de pesquisa e de vetor.
Pesquisa — Full-text pesquisa que habilita aplicativos em redes internas, como sistemas de gerenciamento de conteúdo e repositórios de documentos legais, bem como aplicativos voltados para a Internet, como pesquisa em sites de comércio eletrônico e descoberta de conteúdo.
Pesquisa vetorial: a pesquisa semântica em incorporações vetoriais simplifica o gerenciamento de dados vetoriais e possibilita experiências de pesquisa aprimorada por machine learning (ML). É compatível com aplicações de IA generativa, como chatbots, assistentes pessoais e detecção de fraudes.
Você escolhe um tipo de coleção ao criar uma coleção pela primeira vez:
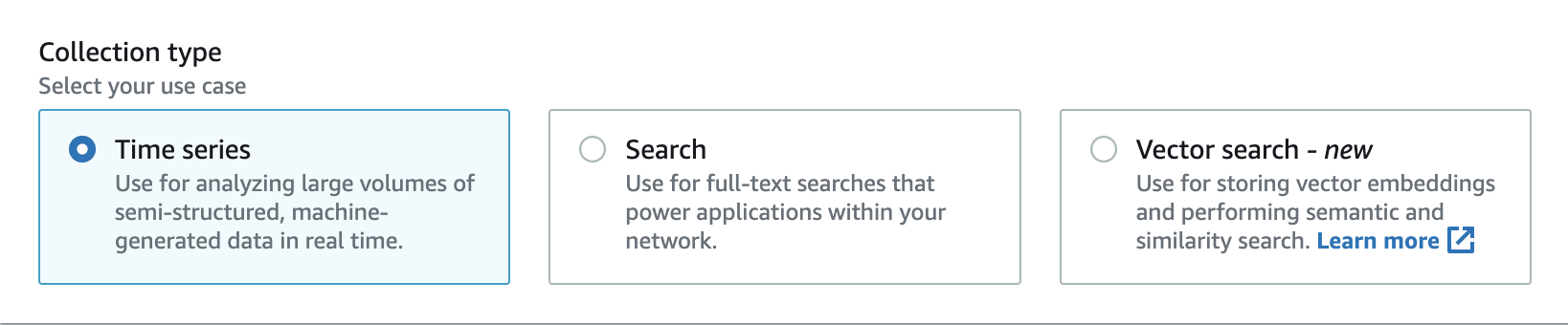
O tipo de coleção que você escolhe depende do tipo dos dados que planeja ingerir na coleção e de como você planeja consultá-los. Não é possível alterar o tipo da coleção depois de criá-la.
Os tipos de coleção têm as seguintes diferenças notáveis:
-
Para coleções de pesquisa e pesquisa vetorial, todos os dados são armazenados no armazenamento a quente para garantir tempos de resposta rápidos às consultas. As coleções de séries temporais usam uma combinação de armazenamento de atividade alta e muito alta, em que os dados mais recentes são mantidos em armazenamento de atividade muito alta para otimizar os tempos de resposta da consulta para dados acessados com mais frequência.
-
Para coleções de séries temporais, você não pode indexar por ID de documento personalizado nem atualizar por meio de solicitações upsert. Essa operação é reservada para casos de uso de pesquisa. Em vez disso, você pode atualizar por ID do documento. Para saber mais, consulte Operações e permissões de OpenSearch API suportadas.
-
Para pesquisas e coleções de séries temporais, você não pode usar índices do tipo k-NN.
Compatível Regiões da AWS
OpenSearch O Serverless está disponível em um subconjunto Regiões da AWS desse OpenSearch Serviço disponível em. Para obter uma lista das regiões suportadas, consulte os endpoints e cotas do Amazon OpenSearch Service no. Referência geral da AWS
Limitações
OpenSearch O Serverless tem as seguintes limitações:
-
Algumas operações de OpenSearch API não são suportadas. Consulte Operações e permissões de OpenSearch API suportadas.
-
Alguns OpenSearch plug-ins não são compatíveis. Consulte OpenSearch Plugins compatíveis.
-
Atualmente, não há como migrar automaticamente seus dados de um domínio de OpenSearch serviço gerenciado para uma coleção sem servidor. É necessário reindexar seus dados de um domínio para uma coleção.
-
Cross-account o acesso às coleções não é suportado. Não é possível incluir coleções de outras contas em suas políticas de criptografia ou acesso a dados.
-
Não há suporte para OpenSearch plug-ins personalizados.
-
Instantâneos automatizados são compatíveis com coleções OpenSearch sem servidor. Não há suporte para instantâneos manuais. Para obter mais informações, consulte Fazer backup de coleções usando snapshots.
-
Cross-Region a pesquisa e a replicação não são suportadas.
-
Há limites no número de recursos de tecnologia sem servidor possíveis em uma única conta e região. Consulte Cotas OpenSearch sem servidor.
-
O intervalo de atualização dos índices nas coleções de pesquisa e série temporal é de aproximadamente 10 segundos.
-
O número de fragmentos, o número de intervalos e o intervalo de atualização não são modificáveis e são gerenciados pelo Serverless. OpenSearch A estratégia de fragmentação é baseada no tipo de coleta e no tráfego. Por exemplo, uma coleção de séries temporais dimensiona os fragmentos primários com base nos gargalos do tráfego de gravação.
