As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Ingestão de dados em coleções Amazon OpenSearch Serverless
Essas seções fornecem detalhes sobre os pipelines de ingestão compatíveis para ingestão de dados em coleções Amazon OpenSearch Serverless. Eles também abrangem alguns dos clientes que você pode usar para interagir com as operações da OpenSearch API. Seus clientes devem ser compatíveis com OpenSearch 2.x para se integrarem ao OpenSearch Serverless.
Tópicos
Permissões mínimas necessárias
Para ingerir dados em uma coleção OpenSearch sem servidor, o diretor que está gravando os dados deve ter as seguintes permissões mínimas atribuídas em uma política de acesso a dados:
[ { "Rules":[ { "ResourceType":"index", "Resource":[ "index/target-collection/logs" ], "Permission":[ "aoss:CreateIndex", "aoss:WriteDocument", "aoss:UpdateIndex" ] } ], "Principal":[ "arn:aws:iam::123456789012:user/my-user" ] } ]
As permissões podem ser mais amplas se você planejar gravar em índices adicionais. Por exemplo, em vez de especificar um único índice de destino, você pode conceder permissão para todos os índices (índice/ target-collection /*) ou para um subconjunto de índices (índice//). target-collection logs*
Para obter uma referência de todas as operações de OpenSearch API disponíveis e suas permissões associadas, consulteOperações e plug-ins compatíveis no Amazon OpenSearch Serverless.
OpenSearch Ingestão
Em vez de usar um cliente terceirizado para enviar dados diretamente para uma coleção OpenSearch sem servidor, você pode usar o Amazon OpenSearch Ingestion. Você configura seus produtores de dados para enviar dados para OpenSearch ingestão, e ele entrega automaticamente os dados para a coleção que você especificar. Você também pode configurar a OpenSearch ingestão para transformar seus dados antes de entregá-los. Para obter mais informações, consulte Visão geral da OpenSearch ingestão da Amazon.
Um pipeline OpenSearch de ingestão precisa de permissão para gravar em uma coleção OpenSearch Serverless configurada como coletor. Essas permissões incluem a capacidade de descrever a coleção e enviar solicitações HTTP para ela. Para obter instruções sobre como usar a OpenSearch ingestão para adicionar dados a uma coleção, consulteConcedendo aos pipelines do Amazon OpenSearch Ingestion acesso às coleções.
Para começar a usar a OpenSearch ingestão, consulteTutorial: Ingestão de dados em uma coleção usando o Amazon OpenSearch Ingestion.
Fluent Bit
Você pode usar AWS
a imagem Fluent Bit
nota
Você deve ter a versão 2.30.0 ou posterior da imagem AWS for Fluent Bit para se integrar ao Serverless. OpenSearch
Exemplo de configuração:
Este exemplo de seção de saída do arquivo de configuração mostra como usar uma coleção OpenSearch Serverless como destino. A adição importante é o parâmetro AWS_Service_Name, que é aoss. Host é o endpoint da coleção.
[OUTPUT] Name opensearch Match * Hostcollection-endpoint.us-west-2.aoss.amazonaws.com Port 443 Indexmy_indexTrace_Error On Trace_Output On AWS_Auth On AWS_Region<region>AWS_Service_Name aoss tls On Suppress_Type_Name On
Amazon Data Firehose
O Firehose oferece suporte ao OpenSearch Serverless como destino de entrega. Para obter instruções sobre como enviar dados para o OpenSearch Serverless, consulte Criação de um stream de entrega do Kinesis Data Firehose e OpenSearch Escolha sem servidor para seu destino no Guia do desenvolvedor do Amazon Data Firehose.
O perfil do IAM que você fornece ao Firehose para entrega deve ser especificado em uma política de acesso a dados com a permissão mínima de aoss:WriteDocument para a coleção de destino, e você deve ter um índice preexistente para o qual enviar os dados. Para obter mais informações, consulte Permissões mínimas necessárias.
Antes de enviar dados para o OpenSearch Serverless, talvez seja necessário realizar transformações nos dados. Para saber mais sobre como usar funções do Lambda para executar essa tarefa, consulte Transformação de dados do Amazon Kinesis Data Firehose no mesmo guia.
Go
O código de exemplo a seguir usa o cliente opensearch-goregion e host.
package main import ( "context" "log" "strings" "github.com/aws/aws-sdk-go-v2/aws" "github.com/aws/aws-sdk-go-v2/config" opensearch "github.com/opensearch-project/opensearch-go/v2" opensearchapi "github.com/opensearch-project/opensearch-go/v2/opensearchapi" requestsigner "github.com/opensearch-project/opensearch-go/v2/signer/awsv2" ) const endpoint = "" // serverless collection endpoint func main() { ctx := context.Background() awsCfg, err := config.LoadDefaultConfig(ctx, config.WithRegion("<AWS_REGION>"), config.WithCredentialsProvider( getCredentialProvider("<AWS_ACCESS_KEY>", "<AWS_SECRET_ACCESS_KEY>", "<AWS_SESSION_TOKEN>"), ), ) if err != nil { log.Fatal(err) // don't log.fatal in a production-ready app } // create an AWS request Signer and load AWS configuration using default config folder or env vars. signer, err := requestsigner.NewSignerWithService(awsCfg, "aoss") // "aoss" for Amazon OpenSearch Serverless if err != nil { log.Fatal(err) // don't log.fatal in a production-ready app } // create an opensearch client and use the request-signer client, err := opensearch.NewClient(opensearch.Config{ Addresses: []string{endpoint}, Signer: signer, }) if err != nil { log.Fatal("client creation err", err) } indexName := "go-test-index" // define index mapping mapping := strings.NewReader(`{ "settings": { "index": { "number_of_shards": 4 } } }`) // create an index createIndex := opensearchapi.IndicesCreateRequest{ Index: indexName, Body: mapping, } createIndexResponse, err := createIndex.Do(context.Background(), client) if err != nil { log.Println("Error ", err.Error()) log.Println("failed to create index ", err) log.Fatal("create response body read err", err) } log.Println(createIndexResponse) // delete the index deleteIndex := opensearchapi.IndicesDeleteRequest{ Index: []string{indexName}, } deleteIndexResponse, err := deleteIndex.Do(context.Background(), client) if err != nil { log.Println("failed to delete index ", err) log.Fatal("delete index response body read err", err) } log.Println("deleting index", deleteIndexResponse) } func getCredentialProvider(accessKey, secretAccessKey, token string) aws.CredentialsProviderFunc { return func(ctx context.Context) (aws.Credentials, error) { c := &aws.Credentials{ AccessKeyID: accessKey, SecretAccessKey: secretAccessKey, SessionToken: token, } return *c, nil } }
Java
O código de exemplo a seguir usa o cliente opensearch-javaregion e host.
A diferença importante em relação aos domínios OpenSearch de serviço é o nome do serviço (aossem vez dees).
// import OpenSearchClient to establish connection to OpenSearch Serverless collection import org.opensearch.client.opensearch.OpenSearchClient; import software.amazon.awssdk.auth.credentials.AwsCredentialsProvider; import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider; // Configure credential provider AwsCredentialsProvider credentialsProvider = DefaultCredentialsProvider.create(); SdkHttpClient httpClient = ApacheHttpClient.builder().build(); // create an opensearch client and use the request-signer OpenSearchClient client = new OpenSearchClient( new AwsSdk2Transport( httpClient, "...us-west-2.aoss.amazonaws.com", // serverless collection endpoint "aoss" // signing service name Region.US_WEST_2, // signing service region AwsSdk2TransportOptions.builder().build() ) ); String index = "sample-index"; // create an index CreateIndexRequest createIndexRequest = new CreateIndexRequest.Builder().index(index).build(); CreateIndexResponse createIndexResponse = client.indices().create(createIndexRequest); System.out.println("Create index reponse: " + createIndexResponse); // delete the index DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest.Builder().index(index).build(); DeleteIndexResponse deleteIndexResponse = client.indices().delete(deleteIndexRequest); System.out.println("Delete index reponse: " + deleteIndexResponse); httpClient.close();
O exemplo de código a seguir estabelece novamente uma conexão segura e depois pesquisa um índice.
import org.opensearch.client.opensearch.OpenSearchClient; SdkHttpClient httpClient = ApacheHttpClient.builder().build(); OpenSearchClient client = new OpenSearchClient( new AwsSdk2Transport( httpClient, "...us-west-2.aoss.amazonaws.com", // serverless collection endpoint "aoss" // signing service name Region.US_WEST_2, // signing service region AwsSdk2TransportOptions.builder().build() ) ); Response response = client.generic() .execute( Requests.builder() .endpoint("/" + "users" + "/_search?typed_keys=true") .method("GET") .json("{" + " \"query\": {" + " \"match_all\": {}" + " }" + "}") .build()); httpClient.close();
O código de exemplo a seguir estabelece uma conexão segura e indexa um documento em uma coleção.
import org.opensearch.client.opensearch.OpenSearchClient; import org.opensearch.client.opensearch.core.IndexRequest; import org.opensearch.client.opensearch.core.IndexResponse; import java.util.HashMap; import java.util.Map; SdkHttpClient httpClient = ApacheHttpClient.builder().build(); OpenSearchClient client = new OpenSearchClient( new AwsSdk2Transport( httpClient, "...us-west-2.aoss.amazonaws.com", // serverless collection endpoint "aoss" // signing service name Region.US_WEST_2, // signing service region AwsSdk2TransportOptions.builder().build() ) ); // index a document Map<String, Object> document = new HashMap<>(); document.put("title", "The Green Mile"); document.put("director", "Frank Darabont"); document.put("year", "1999"); IndexRequest<Map<String, Object>> indexRequest = IndexRequest.of(i -> i .index("books-index") .document(document) ); IndexResponse indexResponse = client.index(indexRequest); System.out.println("Index response: " + indexResponse.result()); httpClient.close();
JavaScript
O código de exemplo a seguir usa o cliente opensearch-jsnode e region.
A diferença importante em relação aos domínios OpenSearch de serviço é o nome do serviço (aossem vez dees).
Logstash
Você pode usar o OpenSearch plug-in Logstash
Para usar o Logstash para enviar dados para o Serverless OpenSearch
-
Instale a versão 2.0.0 ou posterior do plug-in logstash-output-opensearch
usando Docker ou Linux. -
Para que o plug-in OpenSearch de saída funcione com o OpenSearch Serverless, você deve fazer as seguintes modificações na seção de
opensearchsaída do logstash.conf:-
Especifique
aosscomo oservice_nameemauth_type. -
Especifique seu endpoint de coleção para
hosts. -
Adicione os parâmetros
default_server_major_versionelegacy_template. Esses parâmetros são necessários para que o plug-in funcione com o OpenSearch Serverless.
output { opensearch { hosts => "collection-endpoint:443" auth_type => { ... service_name => 'aoss' } default_server_major_version => 2 legacy_template => false } }Esse exemplo de arquivo de configuração obtém sua entrada de arquivos em um bucket do S3 e os envia para uma coleção OpenSearch Serverless:
input { s3 { bucket => "my-s3-bucket" region => "us-east-1" } } output { opensearch { ecs_compatibility => disabled hosts => "https://my-collection-endpoint.us-east-1.aoss.amazonaws.com:443" index =>my-indexauth_type => { type => 'aws_iam' aws_access_key_id => 'your-access-key' aws_secret_access_key => 'your-secret-key' region => 'us-east-1' service_name => 'aoss' } default_server_major_version => 2 legacy_template => false } } -
-
Em seguida, execute o Logstash com a nova configuração para testar o plug-in:
bin/logstash -f config/test-plugin.conf
Python
O código de exemplo a seguir usa o cliente opensearch-pyregion e host.
A diferença importante em relação aos domínios OpenSearch de serviço é o nome do serviço (aossem vez dees).
from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth import boto3 host = '' # serverless collection endpoint, without https:// region = '' # e.g. us-east-1 service = 'aoss' credentials = boto3.Session().get_credentials() auth = AWSV4SignerAuth(credentials, region, service) # create an opensearch client and use the request-signer client = OpenSearch( hosts=[{'host': host, 'port': 443}], http_auth=auth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection, pool_maxsize=20, ) # create an index index_name = 'books-index' create_response = client.indices.create( index_name ) print('\nCreating index:') print(create_response) # index a document document = { 'title': 'The Green Mile', 'director': 'Stephen King', 'year': '1996' } response = client.index( index = 'books-index', body = document, id = '1' ) delete_response = client.indices.delete( index_name ) print('\nDeleting index:') print(delete_response)
nota
O id = '1' parâmetro neste exemplo especifica uma ID de documento personalizada. IDs de documentos personalizados só são compatíveis com coleções de pesquisa. Para séries temporais e coleções de pesquisa vetorial, a indexação com uma ID de documento personalizada não é suportada e retornará um erro. Omita o id parâmetro ao indexar em séries temporais ou coleções de pesquisa vetorial.
Ruby
A opensearch-aws-sigv4 gema fornece acesso ao OpenSearch Serverless, junto com o OpenSearch Service, pronto para uso. Ele tem todos os recursos do cliente opensearch-ruby
Ao instanciar o signatário do Sigv4, especifique aoss como nome do serviço:
require 'opensearch-aws-sigv4' require 'aws-sigv4' signer = Aws::Sigv4::Signer.new(service: 'aoss', region: 'us-west-2', access_key_id: 'key_id', secret_access_key: 'secret') # create an opensearch client and use the request-signer client = OpenSearch::Aws::Sigv4Client.new( { host: 'https://your.amz-opensearch-serverless.endpoint', log: true }, signer) # create an index index = 'prime' client.indices.create(index: index) # insert data client.index(index: index, id: '1', body: { name: 'Amazon Echo', msrp: '5999', year: 2011 }) # query the index client.search(body: { query: { match: { name: 'Echo' } } }) # delete index entry client.delete(index: index, id: '1') # delete the index client.indices.delete(index: index)
Assinar solicitações HTTP com outros clientes
Os requisitos a seguir se aplicam ao assinar solicitações em coleções OpenSearch sem servidor quando você cria solicitações HTTP com outros clientes.
-
O nome do serviço deve ser especificado como
aoss. -
O cabeçalho
x-amz-content-sha256é obrigatório para todas as solicitações do AWS Signature Version 4. Ele fornece um hash da carga da solicitação. Se houver uma carga de solicitação, defina o valor como seu hash criptográfico (SHA256) do Secure Hash Algorithm (SHA). Se não houver carga de solicitação, defina o valor comoe3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855, que é o hash de uma string vazia.
Indexar com cURL
O exemplo de solicitação a seguir usa a Client URL Request Library (cURL) para enviar um único documento para um índice denominado movies-index em uma coleção:
curl -XPOST \ --user "$AWS_ACCESS_KEY_ID":"$AWS_SECRET_ACCESS_KEY" \ --aws-sigv4 "aws:amz:us-east-1:aoss" \ --header "x-amz-content-sha256: $REQUEST_PAYLOAD_SHA_HASH" \ --header "x-amz-security-token: $AWS_SESSION_TOKEN" \ "https://my-collection-endpoint.us-east-1.aoss.amazonaws.com/movies-index/_doc" \ -H "Content-Type: application/json" -d '{"title": "Shawshank Redemption"}'
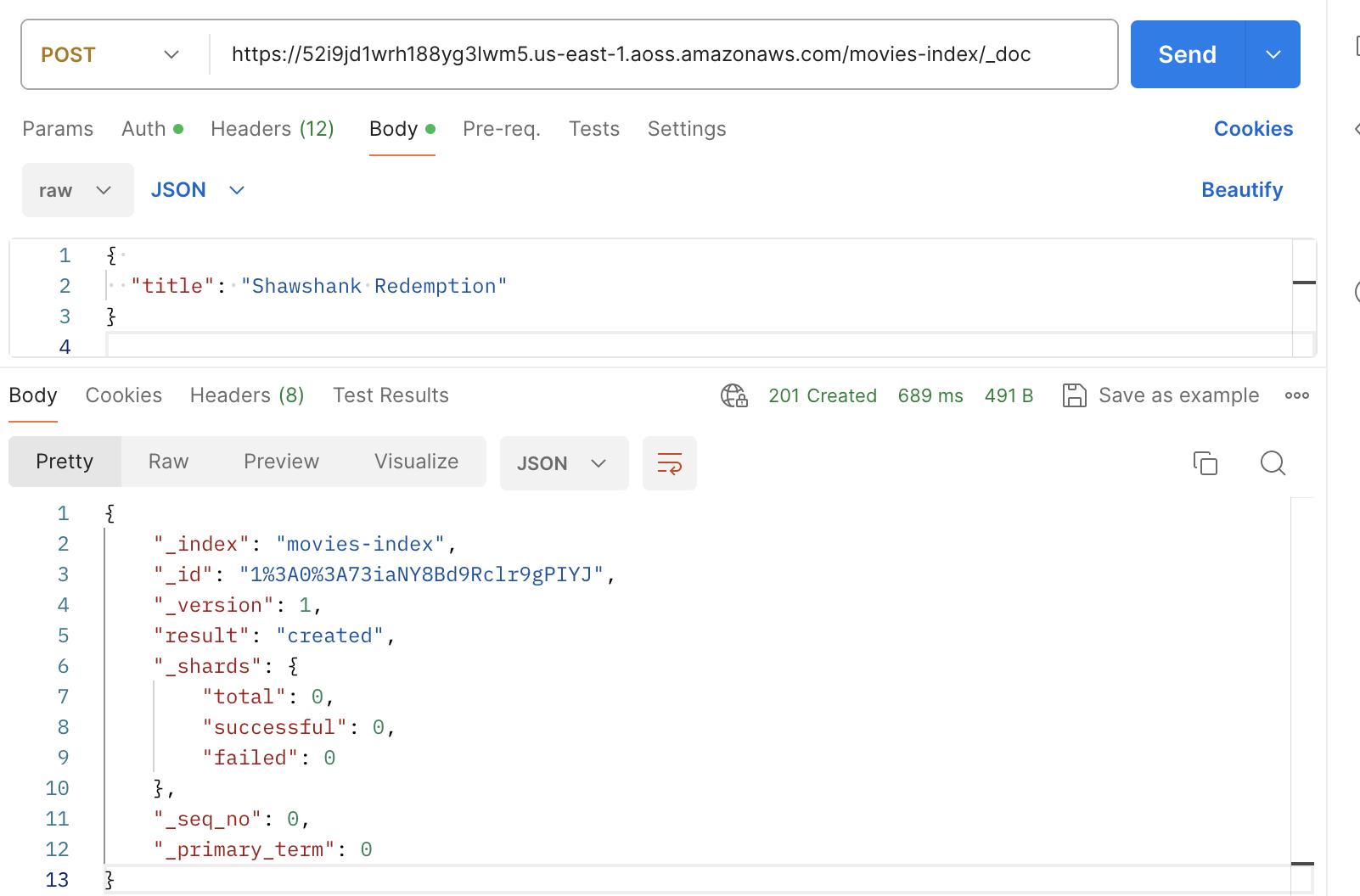
Indexar com o Postman
A imagem a seguir mostra como enviar solicitações para uma coleção usando o Postman. Para obter instruções sobre como autenticar, consulte Fluxo de trabalho de autenticação com AWS assinatura no Postman