As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Trazendo dados do Amazon Redshift para o AWS Glue Data Catalog
Você pode gerenciar dados analíticos nos armazéns de dados do Amazon Redshift no (Catálogo de dados) e AWS Glue Data Catalog unificar os data lakes do Amazon S3 e os armazéns de dados do Amazon Redshift. O Amazon Redshift é um serviço de armazém de dados totalmente gerenciado em escala de petabytes na nuvem. AWS Um data warehouse do Amazon Redshift é um conjunto de recursos de computação chamados nós, que são organizados em um grupo chamado cluster. Cada cluster executa um mecanismo do Amazon Redshift e contém um ou mais bancos de dados.
No Amazon Redshift, é possível criar clusters provisionados e namespaces sem servidor do Amazon Redshift e registrá-los no Data Catalog. Ao fazer isso, você pode unificar dados no armazenamento gerenciado do Amazon Redshift (RMS) e nos buckets do Amazon S3 e acessar dados de mecanismos de analytics compatíveis com o Apache Iceberg.
Quando você registra namespaces e clusters, pode conceder acesso aos dados sem a necessidade de copiá-los ou movê-los. Para acessar mais informações sobre o registro de clusters e namespaces no Amazon Redshift, consulte Registrar clusters e namespaces do Amazon Redshift no AWS Glue Data Catalog.
No Amazon Redshift, é possível realizar o compartilhamento de dados por meio de unidades de compartilhamento de dados ou registrar namespaces e clusters com o Data Catalog. Com as unidades de compartilhamento de dados, que operam no nível de objeto de banco de dados individual, você precisa habilitar o compartilhamento para cada tabela ou visualização. Por outro lado, a publicação de namespace funciona em nível de cluster ou namespace. Quando você registra um cluster ou namespace no Data Catalog, todos os bancos de dados e tabelas dentro dele são compartilhados automaticamente, sem que você precise configurar o compartilhamento para objetos individuais.
No Data Catalog, você pode criar um catálogo federado para cada namespace ou cluster. Um catálogo é chamado de catálogo federado quando aponta para uma entidade fora do Data Catalog. As tabelas e visualizações no namespace do Amazon Redshift são listadas como tabelas individuais no Data Catalog. É possível compartilhar bancos de dados e tabelas no catálogo federado com entidades principais do IAM e usuários SAML selecionados na mesma conta ou em outra conta com Lake Formation. Você também pode incluir expressões de filtro de linha e coluna para restringir o acesso a determinados dados. Para obter mais informações, consulte Filtragem de dados e segurança por célula no Lake Formation.
O Data Catalog comporta uma hierarquia de metadados de três níveis que inclui catálogos, bancos de dados e tabelas (e visualizações). Quando você registra um namespace no Data Catalog, a hierarquia de dados do Amazon Redshift é associada à hierarquia de três níveis do Data Catalog da seguinte forma:
-
O namespace Amazon Redshift se torna um catálogo de vários níveis no Data Catalog.
O banco de dados associado do Amazon Redshift é registrado como um catálogo no Data Catalog.
-
O esquema do Amazon Redshift se torna um banco de dados no Data Catalog.
-
A tabela do Amazon Redshift se torna uma tabela no Data Catalog.
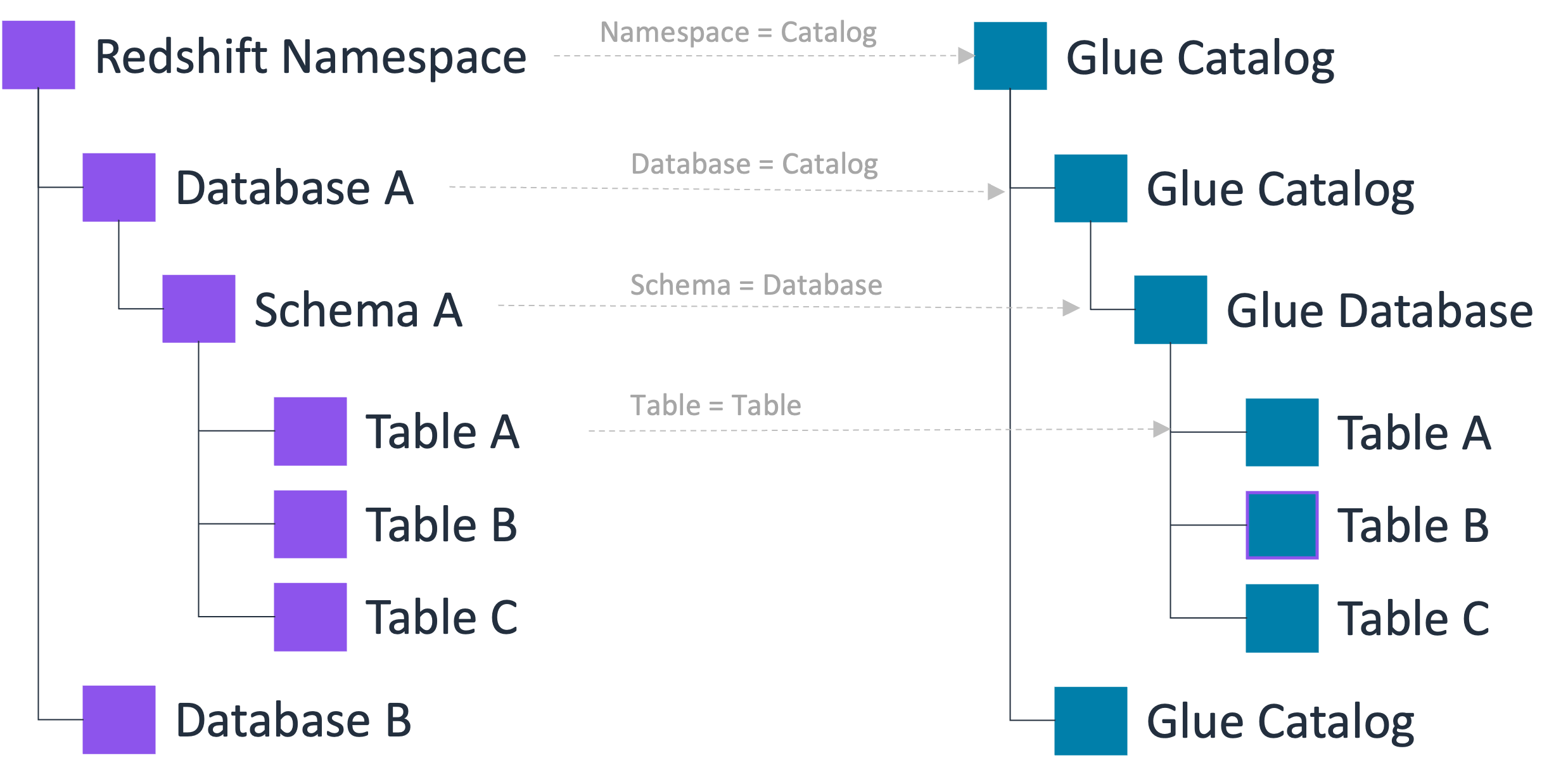
Com essa hierarquia de metadados de três níveis, você pode acessar as tabelas do Amazon Redshift usando a notação em três partes: “catalog1/catalog2.database.table” no Data Catalog. Além disso, as equipes de dados podem manter a mesma organização que o Amazon Redshift usa para organizar tabelas na conta do Data Catalog.
No Lake Formation, você pode gerenciar com segurança os dados do Amazon Redshift usando controle de acesso refinado para os recursos do Data Catalog. Com essa integração, é possível gerenciar, proteger e consultar dados analíticos de um único catálogo com um mecanismo de controle de acesso comum.
Para conhecer as limitações, consulte Limitações para trazer dados do armazém de dados do Amazon Redshift para o AWS Glue Data Catalog.
Benefícios principais
O registro de clusters e namespaces do Amazon Redshift com eles e AWS Glue Data Catalog a unificação de dados nos data lakes do Amazon S3 e nos armazéns de dados do Amazon Redshift oferecem os seguintes benefícios:
Experiência de consulta uniforme: consulte seus dados e dados gerenciados pelo Amazon Redshift nos buckets do Amazon S3 usando qualquer mecanismo de consulta compatível com o Apache Iceberg, como o Amazon EMR Sem Servidor e o Amazon Athena, sem precisar mover ou copiar dados.
-
Acesso consistente aos dados em todos os serviços — Você não precisa atualizar os nomes do banco de dados e das tabelas em seus pipelines de dados ao acessar as mesmas fontes de dados federadas de diferentes serviços de AWS análise, pois as fontes de dados são registradas no Catálogo de Dados.
Controle de acesso refinado: é possível aplicar permissões do Lake Formation para gerenciar o acesso às fontes de dados federadas usando permissões de controle de acesso refinadas.
Perfis e responsabilidades
| Perfil | Responsabilidade |
| Administrador de cluster de produtor do Amazon Redshift |
Registra o cluster ou o namespace no Data Catalog. |
| Administrador do data lake do Lake Formation |
Aceita o convite do cluster ou do namespace, cria catálogos federados e concede acesso aos catálogos federados a outras entidades principais. |
| Administrador somente leitura do Lake Formation | Descobre o catálogo federado e consulta as tabelas do Amazon Redshift no catálogo federado. |
| Perfil de transferência de dados |
O Amazon Redshift assume, em seu nome, a transferência de dados para e do bucket do Amazon S3. |
Veja a seguir as etapas de alto nível para conceder acesso aos usuários a um namespace do Amazon Redshift:
-
No Amazon Redshift, o administrador do cluster produtor registra um cluster ou namespace no Data Catalog.
-
O administrador do data lake aceita o convite do namespace do administrador do cluster produtor do Amazon Redshift e cria um catálogo federado no Data Catalog.
Após concluir essa etapa, você pode gerenciar o catálogo de namespaces do Amazon Redshift dentro do Data Catalog.
-
Conceda permissões a usuários em catálogos, bancos de dados e tabelas. Você pode compartilhar todo o catálogo de namespaces ou um subconjunto de tabelas com os usuários na mesma conta ou em outra conta.
