As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Crie grades de proteção de IA para agentes do Connect AI
Uma barreira de proteção de IA é um recurso que permite que você implemente proteções com base em seus casos de uso e políticas de IA responsável.
Os agentes do Connect AI usam grades de proteção do Amazon Bedrock. Você pode criar e editar essas barreiras de proteção no site de administração do Connect Customer .
Conteúdo
O que é importante saber
-
É possível criar até três barreiras de proteção personalizadas.
-
Os agentes do Guardrails for Connect AI oferecem suporte aos mesmos idiomas do nível clássico de guardrails do Amazon Bedrock. Para acessar uma lista completa de idiomas compatíveis, consulte Idiomas compatíveis com as barreiras de proteção do Amazon Bedrock. A avaliação de conteúdo textual em outros idiomas será ineficaz.
-
Ao configurar ou editar uma barreira de proteção, é altamente recomendável que você faça testes e compare com configurações diferentes. É possível que algumas de suas combinações tenham consequências inesperadas. Teste a barreira de proteção para garantir que os resultados atendam aos requisitos do seu caso de uso.
-
Quando as grades de proteção são ativadas com respostas de streaming, há latência adicional porque os trechos de texto devem ser armazenados em buffer e digitalizados antes de serem entregues. Isso afeta principalmente o time-to-first token (TTFT), pois o sistema precisa acumular texto suficiente para realizar uma avaliação significativa da proteção antes de transmitir a primeira parte para o usuário final. Espera-se uma pequena latência adicional além do TTFT, dependendo das configurações do guardrail. Respostas mais curtas podem apresentar uma latência proporcionalmente mais perceptível, pois a varredura do guardrail ainda precisa processar um buffer mínimo de texto. Essa é uma compensação inerente entre a precisão da segurança do conteúdo e a velocidade de resposta. Se seu caso de uso for sensível à latência, considere se as grades de proteção são necessárias para todas as interações ou se elas podem ser aplicadas seletivamente. Para obter mais informações sobre o modo de streaming síncrono de guardrail, consulte Configurar o comportamento de resposta de streaming para filtrar o conteúdo no Guia do usuário do Amazon Bedrock.
Como criar uma barreira de proteção de IA
-
Faça login no site do Connect Customer administrador com uma conta que tem o designer de agentes de IA, AI guardrails - Crie permissão em seu perfil de segurança.
-
No site do Connect Customer administrador, no menu de navegação à esquerda, escolha AI agent designer, AI guardrails.
-
Na página Barreiras de proteção, escolha Criar barreira de proteção.
-
Na caixa de diálogo Criar barreira de proteção de IA, insira um nome e uma descrição para a barreira de proteção e escolha Criar.
-
Na página Construtor de barreiras de proteção de IA, preencha os seguintes campos conforme necessário para criar políticas para a sua barreira de proteção:
-
Filtros de conteúdo: ajuste a intensidade dos filtros para ajudar a bloquear prompts de entrada ou respostas de modelo que tenham conteúdo prejudicial. A filtragem é feita com base na detecção de determinadas categorias predefinidas de conteúdo prejudicial, como ódio, insultos, sexo, violência, má conduta e ataque de prompt.
-
Tópicos negados: defina um conjunto de tópicos que não são desejáveis no contexto da sua aplicação. O filtro ajudará a bloqueá-los se detectados em consultas do usuário ou nas respostas do modelo. É possível adicionar até 30 tópicos negados.
-
Verificação contextual de aterramento: ajude a detectar e filtrar alucinações nas respostas do modelo de acordo com uma fonte de base e a relevância para a consulta do usuário.
-
Filtros de palavras: configure filtros para ajudar a bloquear palavras, frases e palavrões indesejáveis (correspondência exata). Essas palavras podem incluir termos ofensivos, nomes de concorrentes etc.
-
Filtros de informações confidenciais: configure filtros para ajudar a bloquear ou mascarar informações confidenciais, como informações de identificação pessoal (PII), ou expressões regulares personalizadas nas entradas de usuário e nas respostas do modelo.
O bloqueio ou mascaramento é feito com base na detecção probabilística de informações confidenciais em formatos padrão em entidades como número SSN, data de nascimento, endereço etc. Isso também permite configurar a detecção de padrões baseada em expressões regulares para identificadores.
-
Mensagens bloqueadas: personalize a mensagem padrão que é exibida para o usuário se a barreira de proteção bloquear a entrada ou a resposta do modelo.
O Connect Customer não oferece suporte ao filtro de conteúdo de imagem para ajudar a detectar e filtrar conteúdo de imagem impróprio ou tóxico.
-
-
Quando a barreira de proteção estiver completa, escolha Salvar.
Ao selecionar na lista suspensa de versões, Latest:Draftsempre retorna o estado salvo do guardrail de IA.
-
Selecione Publish. As atualizações na barreira de proteção de IA são salvas, o status de visibilidade da barreira de proteção de IA é definido como Publicada e uma nova versão da barreira de proteção de IA é criada.

Ao selecionar na lista suspensa de versões, Latest:Publishedsempre retorna o estado salvo do guardrail de IA.
Alterar a mensagem padrão de bloqueio
Esta seção explica como acessar o construtor e editor de barreiras de proteção de IA no site de administração do Connect Customer , usando o exemplo de alteração da mensagem de bloqueio que é exibida aos usuários.
A imagem a seguir mostra um exemplo da mensagem de bloqueio padrão exibida para um usuário. A mensagem padrão é “Blocked input text by guardrail”.

Como alterar a mensagem de bloqueio padrão
-
Faça login no site do Connect Customer administrador em https://
instance name.my.connect.aws/. Use uma conta de administrador ou uma conta com o designer de agentes de IA - Guardrails de IA - Crie permissão em seu perfil de segurança. -
No menu de navegação, escolha AI agent designer, AI guardrails.
-
Na página Barreiras de proteção de IA, escolha Criar barreira de proteção de IA. Uma caixa de diálogo é exibida para você atribuir um nome e uma descrição.
-
Na caixa de diálogo Criar barreira de proteção de IA, insira um nome e uma descrição, depois escolha Criar. Se sua empresa já tiver três barreiras de proteção, você receberá uma mensagem de erro, conforme mostrado na imagem a seguir.
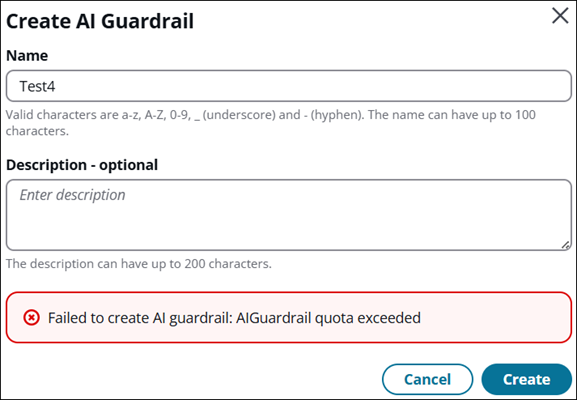
Se você receber essa mensagem, em vez de criar outra barreira de proteção, considere editar uma barreira existente para atender às suas necessidades. Ou exclua uma para poder criar outra.
-
Para alterar a mensagem padrão que é exibida quando a barreira de proteção bloqueia a resposta do modelo, vá até a seção Mensagens bloqueadas.
-
Insira o texto da mensagem de bloqueio que deseja exibir, escolha Salvar e Publicar.
Exemplos de comandos da CLI para configurar políticas de barreira de proteção de IA
Veja a seguir exemplos de como configurar as políticas de barreira de proteção de IA usando a AWS CLI.
Bloquear tópicos indesejáveis
Use o exemplo de comando AWS CLI a seguir para bloquear tópicos indesejáveis.
aws qconnect update-ai-guardrail --cli-input-json { "assistantId": "a0a81ecf-6df1-4f91-9513-3bdcb9497e32", "aiGuardrailId": "9147c4ad-7870-46ba-b6c1-7671f6ca3d95", "blockedInputMessaging": "Blocked input text by guardrail", "blockedOutputsMessaging": "Blocked output text by guardrail", "visibilityStatus": "PUBLISHED", "topicPolicyConfig": { "topicsConfig": [ { "name": "Financial Advice", "definition": "Investment advice refers to financial inquiries, guidance, or recommendations with the goal of generating returns or achieving specific financial objectives.", "examples": ["- Is investment in stocks better than index funds?", "Which stocks should I invest into?", "- Can you manage my personal finance?"], "type": "DENY" } ] } }
Filtrar conteúdo nocivo e impróprio
Use o seguinte exemplo de comando da AWS CLI para filtrar conteúdo nocivo e impróprio.
aws qconnect update-ai-guardrail --cli-input-json { "assistantId": "a0a81ecf-6df1-4f91-9513-3bdcb9497e32", "aiGuardrailId": "9147c4ad-7870-46ba-b6c1-7671f6ca3d95", "blockedInputMessaging": "Blocked input text by guardrail", "blockedOutputsMessaging": "Blocked output text by guardrail", "visibilityStatus": "PUBLISHED", "contentPolicyConfig": { "filtersConfig": [ { "inputStrength": "HIGH", "outputStrength": "HIGH", "type": "INSULTS" } ] } }
Filtrar palavras nocivas e impróprias
Use o exemplo de comando AWS CLI a seguir para filtrar palavras nocivas e inapropriadas.
aws qconnect update-ai-guardrail --cli-input-json { "assistantId": "a0a81ecf-6df1-4f91-9513-3bdcb9497e32", "aiGuardrailId": "9147c4ad-7870-46ba-b6c1-7671f6ca3d95", "blockedInputMessaging": "Blocked input text by guardrail", "blockedOutputsMessaging": "Blocked output text by guardrail", "visibilityStatus": "PUBLISHED", "wordPolicyConfig": { "wordsConfig": [ { "text": "Nvidia", }, ] } }
Detectar alucinações na resposta do modelo
Use o seguinte exemplo de comando AWS CLI para detectar alucinações na resposta do modelo.
aws qconnect update-ai-guardrail --cli-input-json { "assistantId": "a0a81ecf-6df1-4f91-9513-3bdcb9497e32", "aiGuardrailId": "9147c4ad-7870-46ba-b6c1-7671f6ca3d95", "blockedInputMessaging": "Blocked input text by guardrail", "blockedOutputsMessaging": "Blocked output text by guardrail", "visibilityStatus": "PUBLISHED", "contextualGroundPolicyConfig": { "filtersConfig": [ { "type": "RELEVANCE", "threshold": 0.50 }, ] } }
Ocultar informações confidenciais
Use o seguinte exemplo de comando da AWS CLI para redigir informações confidenciais, como informações pessoais identificáveis (PII).
aws qconnect update-ai-guardrail --cli-input-json { "assistantId": "a0a81ecf-6df1-4f91-9513-3bdcb9497e32", "aiGuardrailId": "9147c4ad-7870-46ba-b6c1-7671f6ca3d95", "blockedInputMessaging": "Blocked input text by guardrail", "blockedOutputsMessaging": "Blocked output text by guardrail", "visibilityStatus": "PUBLISHED", "sensitiveInformationPolicyConfig": { "piiEntitiesConfig": [ { "type": "CREDIT_DEBIT_CARD_NUMBER", "action":"BLOCK", }, ] } }
