As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Configurar e personalizar consultas e geração de respostas
Você pode configurar e personalizar a recuperação e a geração de respostas, aumentando ainda mais a relevância das respostas. Por exemplo, você pode aplicar filtros aos metadados do documento fields/attributes para usar os documentos atualizados mais recentemente ou com horários de modificação recentes.
nota
Todas as configurações a seguir, exceto Orquestração e geração, são aplicáveis somente a fontes de dados não estruturados.
Para saber mais sobre essas configurações no console ou na API, selecione um dos seguintes tópicos:
Quando você consulta uma base de conhecimento, o Amazon Bedrock retorna até cinco resultados na resposta por padrão. Cada resultado corresponde a um fragmento de origem.
nota
O número real de resultados na resposta pode ser menor que o valor numberOfResults especificado, pois esse parâmetro define o número máximo de resultados a serem exibidos. Se você configurou a fragmentação hierárquica para sua estratégia de fragmentação, o parâmetro numberOfResults será associado ao número de fragmentos secundários que a base de conhecimento recuperará. Como os fragmentos secundários que compartilham o mesmo fragmento principal são substituídos pelo fragmento principal na resposta final, o número de resultados exibidos pode ser menor do que o valor solicitado.
Para modificar o número máximo de resultados a serem exibidos, escolha a guia correspondente ao método de sua preferência e siga as etapas:
O tipo de pesquisa define como fontes de dados na base de conhecimento são consultadas. Estes tipos de pesquisa são possíveis:
nota
A pesquisa híbrida só é compatível com os armazenamentos vetoriais Amazon RDS, Amazon OpenSearch Serverless e MongoDB que contêm um campo de texto filtrável. Quando você usa um armazenamento de vetores diferente ou seu armazenamento de vetores não contém um campo de texto filtrável, a consulta usa a pesquisa semântica.
-
Padrão: o Amazon Bedrock decide a estratégia de pesquisa para você.
-
Híbrida: combina pesquisa com incorporações de vetores (pesquisa semântica) com pesquisa no texto bruto.
-
Semântica: só pesquisa incorporações de vetores.
Para saber como definir o tipo de pesquisa, escolha a guia correspondente ao método de sua preferência e siga as etapas:
Você pode aplicar filtros ao documento fields/attributes para ajudá-lo a melhorar ainda mais a relevância das respostas. Suas fontes de dados podem incluir metadados do documento attributes/fields para filtrar e especificar quais campos incluir nas incorporações.
Considerações sobre a base de conhecimento gerenciada
Ao usar a filtragem de metadados com uma base de conhecimento gerenciada:
-
Os filtros de
stringContainsmetadadosstartsWithe não são compatíveis. Em vez dissoequalsgreaterThanlessThan, usenotInoperadoresin,,, ou. -
Para bases de conhecimento personalizadas, os campos de metadados prefixados com
x-amz-bedrocksão reservados pelo serviço. Para bases de conhecimento totalmente gerenciadas, os campos de metadados reservados usam um prefixo de sublinhado (por exemplo,,_source_uri)._data_source_idVocê não pode substituir campos de metadados reservados em nenhum dos tipos de base de conhecimento.
Por exemplo, “epoch_modification_time” representa o tempo em segundos desde 1.º de janeiro de 1970 (UTC), quando o documento foi atualizado pela última vez. Você pode filtrar os dados mais recentes, em que “epoch_modification_time” é maior que um determinado número. Esses documentos mais recentes podem ser usados na consulta.
Para usar filtros ao consultar uma base de conhecimento, verifique se a base de conhecimento atende aos seguintes requisitos:
-
Ao configurar o conector da fonte de dados, a maioria dos conectores rastreia os principais campos de metadados dos documentos. Se estiver usando um bucket do Amazon S3 como fonte de dados, o bucket deverá incluir pelo menos um
fileName.extension.metadata.jsonpara o arquivo ou o documento ao qual está associado. Consulte Campos de metadados do documento em Configuração de conexão para ter mais informações sobre como configurar o arquivo de metadados. -
Se o índice vetorial da sua base de conhecimento estiver em um armazenamento vetorial Amazon OpenSearch Serverless, verifique se o índice vetorial está configurado com o
faissmecanismo. Se o índice de vetores estiver configurado com o mecanismonmslib, será necessário fazer o seguinte:-
Crie uma nova base de conhecimento no console e deixe que o Amazon Bedrock crie automaticamente um índice vetorial no Amazon OpenSearch Serverless para você.
-
Criar outro índice de vetores no armazenamento de vetores e selecionar
faisscomo o mecanismo. Em seguida, criar uma base de conhecimento e especificar o novo índice de vetores.
-
-
Se sua base de conhecimento usa um índice de vetores em um bucket de vetores do S3, não é possível usar os filtros
startsWithestringContains. -
Se estiver adicionando metadados a um índice de vetores existente em um cluster de banco de dados do Amazon Aurora, recomendamos que você forneça o nome do campo da coluna de metadados personalizados para armazenar todos os metadados em uma única coluna. Durante a ingestão de dados, essa coluna será usada para preencher todas as informações em os arquivos de metadados de suas fontes de dados. Se você optar por fornecer esse campo, deverá criar um índice nessa coluna.
-
Quando você cria uma base de conhecimento no console e permite que o Amazon Bedrock configure o banco de dados do Amazon Aurora, ele cria automaticamente uma única coluna para você e a preenche com as informações dos seus arquivos de metadados.
-
Ao optar por criar outro índice de vetores no armazenamento de vetores, é necessário fornecer o nome do campo de metadados personalizados para armazenar informações dos arquivos de metadados. Se você não fornecer esse nome de campo, crie uma coluna para cada atributo de metadados nos arquivos e especifique o tipo de dados (texto, número ou booliano). Por exemplo, se o atributo
genreexistir na fonte de dados, você deve adicionar uma coluna chamadagenree especificartextcomo o tipo de dados. Durante a ingestão, essas colunas separadas serão preenchidas com os valores dos atributos correspondentes.
-
Se você tiver documentos PDF em sua fonte de dados e usar o Amazon OpenSearch Serverless ou o Amazon Aurora para seu armazenamento de vetores: as bases de conhecimento do Amazon Bedrock gerarão números de página de documentos e os armazenarão em um metadado chamado x-amz-bedrock-kb-document-page-number. field/attribute Observe que não será possível ter números de página armazenados em um campo de metadados se você optar por não agrupar seus documentos.
Você pode usar os operadores de filtragem para filtrar os resultados ao consultar:
| Operador | Console | Nome do filtro da API | Tipos de dados de atributo compatíveis | Resultados filtrados |
|---|---|---|---|---|
| Igual | = | equals | string, número, booliano | O atributo corresponde ao valor fornecido por você |
| Não é igual a | != | notEquals | string, número, booliano | O atributo não corresponde ao valor fornecido por você |
| Maior que | > | greaterThan | número | O atributo é maior que o valor fornecido por você |
| É maior que ou igual a | >= | maior ThanOrEquals | número | O atributo é maior que ou igual ao valor fornecido por você |
| Menor que | < | lessThan | número | O atributo é menor que o valor fornecido por você |
| Menor ou igual a | <= | menos ThanOrEquals | número | O atributo é menor que ou igual ao valor fornecido por você |
| Em | : | in | lista de strings | O atributo está na lista que você fornece (atualmente é mais compatível com os armazenamentos vetoriais Amazon OpenSearch Serverless e Neptune Analytics GraphRag) |
| Não está em | !: | notIn | lista de strings | O atributo não está na lista que você fornece (atualmente é melhor compatível com os armazenamentos vetoriais Amazon OpenSearch Serverless e Neptune Analytics GraphRag) |
| A string contém | Indisponível | stringContains | string | O atributo deve ser uma string. O nome do atributo corresponde à chave e cujo valor é uma string que contém o valor que você forneceu como substring ou uma lista com um membro que contém o valor que você forneceu como substring (atualmente, melhor suportado pelo Amazon OpenSearch Serverless Vector Store). O armazenamento vetorial GraphRag do Neptune Analytics suporta a variante de string (mas não a variante de lista desse filtro). |
| A lista contém | Indisponível | listContains | string | O atributo deve ser uma lista de strings. O nome do atributo corresponde à chave e cujo valor é uma lista que contém o valor que você forneceu como um de seus membros (atualmente é mais compatível com os armazenamentos vetoriais Amazon OpenSearch Serverless). |
Para combinar operadores de filtragem, você pode usar os seguintes operadores lógicos:
Para saber como filtrar os resultados usando metadados, escolha a guia correspondente ao método de sua preferência e siga as etapas:
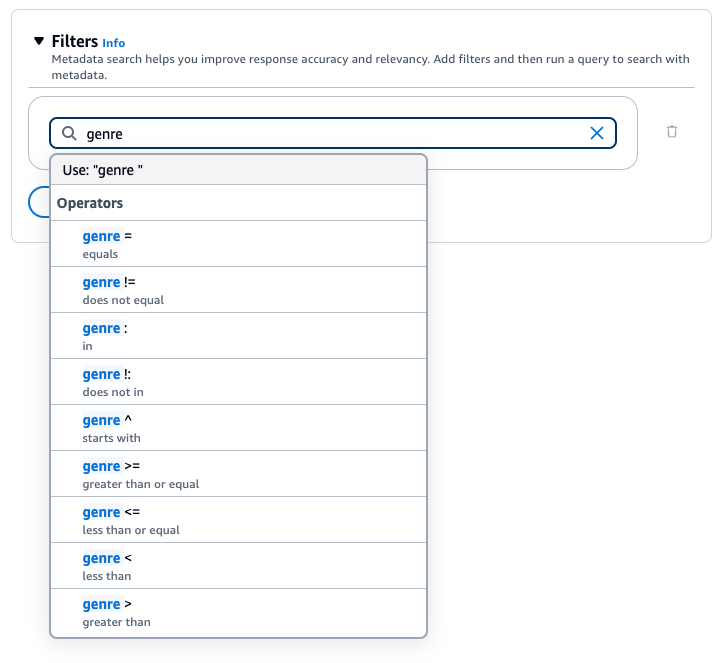

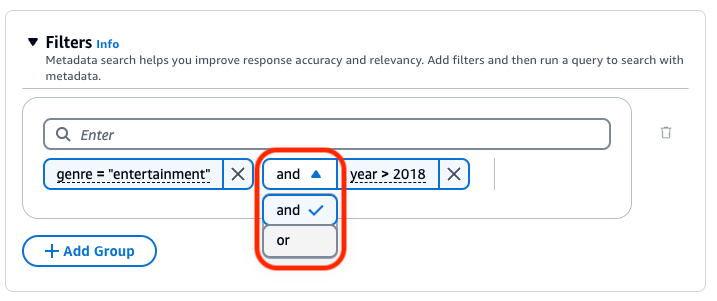
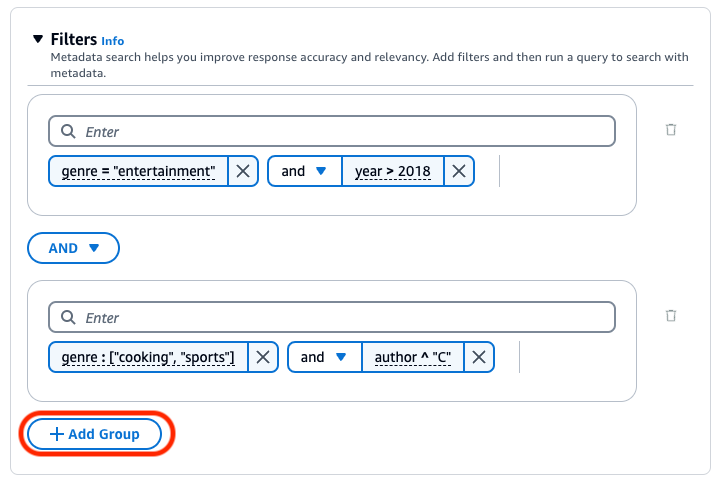
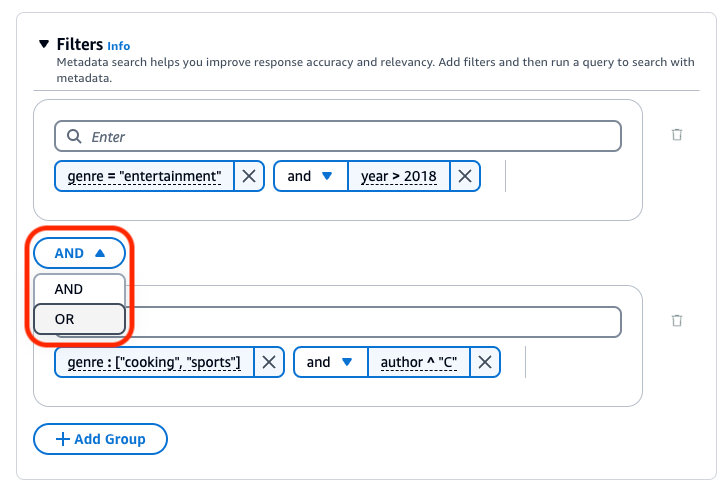
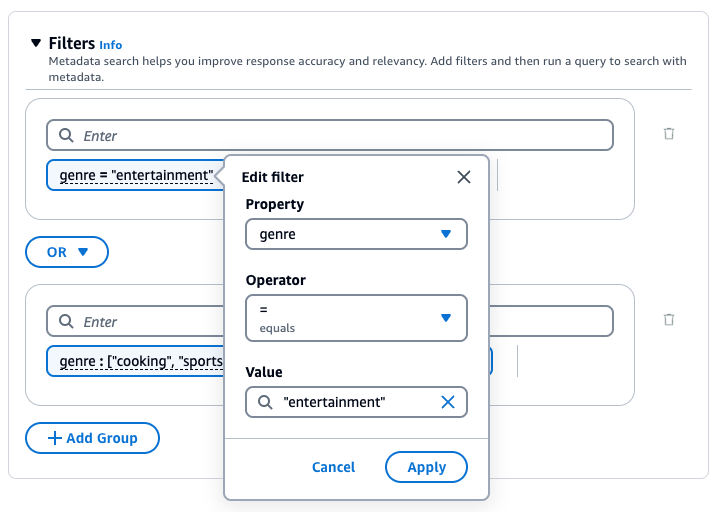
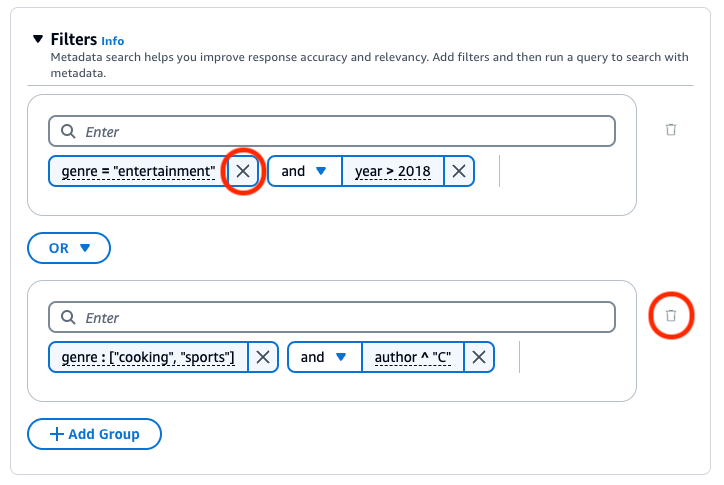
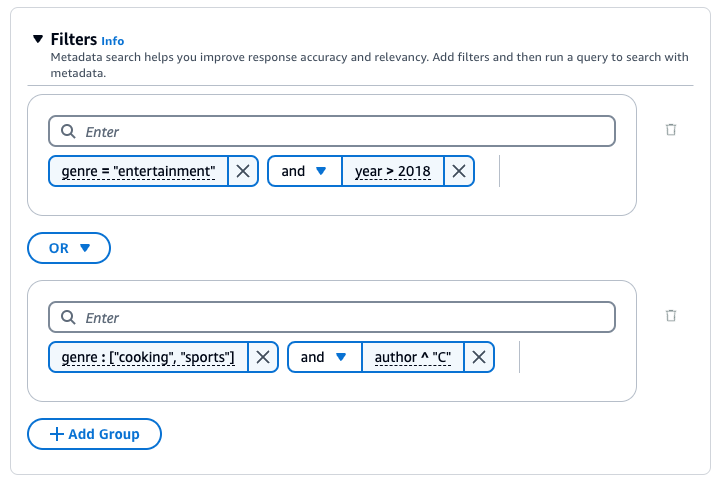
A base de conhecimento do Amazon Bedrock gera e aplica um filtro de recuperação com base na consulta do usuário e em um esquema de metadados.
nota
A filtragem implícita de metadados é suportada por modelos. Anthropic Claude Para obter mais informações sobre os modelos compatíveis, consulte Visão geral dos modelos.
A implicitFilterConfiguration é especificada na vectorSearchConfiguration no corpo da solicitação Retrieve. Inclui os seguintes campos:
-
metadataAttributes: nessa matriz, forneça esquemas que descrevam os atributos de metadados para os quais o modelo gerará um filtro. -
modelArn: o ARN do modelo a ser usado.
Veja a seguir um exemplo de esquemas de metadados que você pode adicionar à matriz metadataAttributes.
[ { "key": "company", "type": "STRING", "description": "The full name of the company. E.g. `Amazon.com, Inc.`, `Alphabet Inc.`, etc" }, { "key": "ticker", "type": "STRING", "description": "The ticker name of a company in the stock market, e.g. AMZN, AAPL" }, { "key": "pe_ratio", "type": "NUMBER", "description": "The price to earning ratio of the company. This is a measure of valuation of a company. The lower the pe ratio, the company stock is considered chearper." }, { "key": "is_us_company", "type": "BOOLEAN", "description": "Indicates whether the company is a US company." }, { "key": "tags", "type": "STRING_LIST", "description": "Tags of the company, indicating its main business. E.g. `E-commerce`, `Search engine`, `Artificial intelligence`, `Cloud computing`, etc" } ]
Você pode implementar barreiras para a base de conhecimento nos casos de uso e políticas de IA responsável. Você pode criar várias barreiras de proteção personalizadas para diferentes casos de uso e aplicá-las em várias condições de solicitação e resposta, proporcionando uma experiência do usuário consistente e padronizando controles de segurança em toda a base de conhecimento. Você pode configurar tópicos negados para evitar tópicos indesejáveis e filtros de conteúdo para bloquear conteúdo prejudicial em entradas e respostas do modelo. Para obter mais informações, consulte Detectar e filtrar conteúdo nocivo usando as Barreiras de Proteção do Amazon Bedrock.
nota
Não é possível usar barreiras de proteção com base contextual para bases de conhecimento no Claude 3 Sonnet e no Haiku.
Para obter diretrizes gerais de engenharia de prompts, consulte Conceitos de engenharia de prompts.
Escolha a guia correspondente ao método de sua preferência e siga as etapas:
Você pode usar um modelo reclassificador para reclassificar os resultados da consulta à base de conhecimento. Siga as etapas do console em Consultar uma base de conhecimento e recuperar dados ou Consultar uma base de conhecimento e gerar respostas com base nos dados recuperados. Ao abrir o painel Configurações, expanda a seção Reclassificação. Selecione um modelo reclassificador, atualize as permissões, se necessário, e modifique as opções adicionais. Insira um prompt e selecione Executar para testar os resultados após a reclassificação.
Decomposição da consulta é uma técnica usada para dividir consultas complexas em subconsultas menores, mais gerenciáveis. Essa abordagem pode ajudar a recuperar informações mais precisas e relevantes, especialmente quando a consulta inicial é multifacetada ou muito abrangente. A habilitação dessa opção pode acarretar a execução de várias consultas na Base de Conhecimento, o que pode ajudar em uma resposta final mais precisa.
Por exemplo, para uma pergunta como “Quem marcou mais na Copa do Mundo FIFA de 2022, Argentina ou França?” , as bases de conhecimento do Amazon Bedrock podem primeiro gerar as seguintes subconsultas, antes de gerar uma resposta final:
-
Quantos gols a Argentina fez na final da Copa do Mundo FIFA de 2022?
-
Quantos gols a França fez na final da Copa do Mundo FIFA de 2022?
Ao gerar respostas com base na recuperação das informações, você pode usar parâmetros de inferência para ter maior controle sobre o comportamento do modelo durante a inferência e influenciar as saídas do modelo.
Para saber como modificar os parâmetros de inferência, escolha a guia correspondente ao método de sua preferência e siga as etapas:
Quando você consulta uma base de conhecimento e solicita a geração de resposta, o Amazon Bedrock usa um modelo de prompt que combina instruções e contexto com a consulta do usuário para criar o prompt de geração enviado ao modelo para geração de respostas. É possível personalizar o prompt de orquestração, que transforma o prompt do usuário em uma consulta de pesquisa. Você pode projetar os modelos de prompt com as seguintes ferramentas:
-
Espaços reservados imediatos — Pre-defined variáveis nas bases de conhecimento Amazon Bedrock que são preenchidas dinamicamente em tempo de execução durante a consulta à base de conhecimento. No prompt do sistema, você verá esses espaços reservados entre o símbolo
$. A seguinte lista descreve os espaços reservados que você pode usar:nota
O espaço reservado
$output_format_instructions$é um campo obrigatório para que as citações sejam exibidas na resposta.Variável Modelo de prompt Substituído por Modelo Obrigatório? $query$ Orquestração, geração A consulta do usuário enviada para a base de conhecimento. Claude Instant da Anthropic, Claude v2.x da Anthropic Sim Anthropic Claude 3 Sonnet Não (incluído automaticamente na entrada do modelo) $search_results$ Geração Os resultados recuperados para a consulta do usuário. Todos Sim $output_format_instructions$ Orquestração Instruções subjacentes para formatação da geração de respostas e citações. Difere de modelo para modelo. Se você definir suas próprias instruções de formatação, sugerimos que remova esse espaço reservado. Sem esse espaço reservado, a resposta não conterá citações. Todos Sim $current_time$ Orquestração, geração A hora atual. Todos Não -
Tags XML: os modelos da Anthropic são compatíveis com o uso de tags XML para estruturar e delinear os prompts. Use nomes de tags descritivos para obter os resultados ideais. Por exemplo, no prompt do sistema padrão, você verá a tag
<database>usada para delinear um banco de dados de perguntas feitas anteriormente. Para obter mais informações, consulte Usar tags XML, no Guia do usuário da Anthropic .
Para obter diretrizes gerais de engenharia de prompts, consulte Conceitos de engenharia de prompts.
nota
Quando você não fornece um modelo de solicitação personalizado, o Amazon Bedrock usa uma solicitação padrão do sistema que inclui conteúdo de exemplo genérico (como exemplos de perguntas e respostas sobre tópicos não relacionados) para orientar a formatação da resposta do modelo. Esse prompt padrão é visível nos registros de invocação do modelo. O conteúdo de exemplo no prompt padrão não vem dos dados de outros clientes — é um modelo estático fornecido pelo Amazon Bedrock. Você pode substituir o prompt padrão especificando o seu próprio. textPromptTemplate
Escolha a guia correspondente ao método de sua preferência e siga as etapas:
