Amazon Timestream for LiveAnalytics와 유사한 기능을 원하는 경우 Amazon Timestream for InfluxDB를 고려해 보세요. 간소화된 데이터 수집과 실시간 분석을 위한 10밀리초 미만의 쿼리 응답 시간을 제공합니다. 여기에서 자세히 알아보세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
단순 플릿 수준 집계
이 첫 번째 예제에서는 간단한 예제 컴퓨팅 플릿 수준 집계를 사용하여 예약된 쿼리로 작업할 때 몇 가지 기본 개념을 안내합니다. 이 예제에서는 다음을 학습합니다.
-
집계 통계를 가져와서 예약된 쿼리에 매핑하는 데 사용되는 대시보드 쿼리를 가져오는 방법입니다.
-
Timestream for LiveAnalytics가 예약된 쿼리의 다양한 인스턴스 실행을 관리하는 방법.
-
예약된 쿼리의 여러 인스턴스가 시간 범위에서 겹치도록 하는 방법과 대상 테이블에서 데이터의 정확성을 유지하여 예약된 쿼리의 결과를 사용하는 대시보드가 원시 데이터에 대해 계산된 동일한 집계와 일치하는 결과를 제공하도록 하는 방법.
-
예약된 쿼리의 시간 범위 및 새로 고침 주기를 설정하는 방법입니다.
-
셀프 서비스는 예약된 쿼리의 결과를 추적하여 쿼리 인스턴스의 실행 지연 시간이 대시보드 새로 고침의 허용 가능한 지연 시간 내에 있도록 조정하는 방법입니다.
소스 테이블에서 집계
이 예제에서는 1분마다 지정된 리전 내의 서버에서 내보내는 지표 수를 추적합니다. 아래 그래프는 us-east-1 리전에 대해이 시계열을 표시하는 예제입니다.
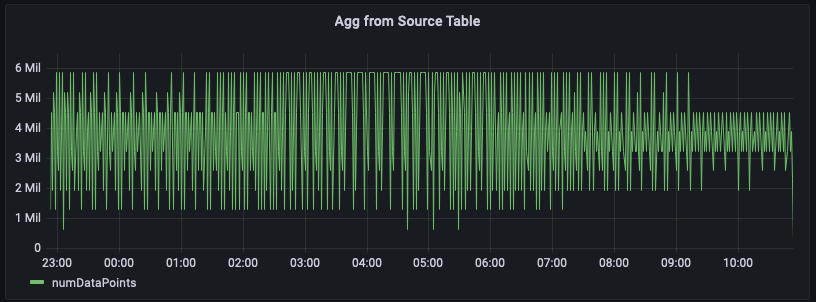
다음은 원시 데이터에서 이 집계를 계산하는 쿼리의 예입니다. 리전 us-east-1의 행을 필터링한 다음 20개 지표(measure_name이 metrics인 경우) 또는 5개 이벤트(measure_name이 events인 경우)를 고려하여 분당 합계를 계산합니다. 이 예제에서 그래프 그림은 내보내는 지표 수가 분당 150만에서 600만 사이임을 보여줍니다. 이 시계열을 몇 시간(이 그림에서 지난 12시간) 동안 그래프로 표시할 때 원시 데이터에 대한이 쿼리는 수억 개의 행을 분석합니다.
WITH grouped_data AS ( SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY region, measure_name, bin(time, 1m) ) SELECT minute, SUM(numDataPoints) AS numDataPoints FROM grouped_data GROUP BY minute ORDER BY 1 desc, 2 desc
집계를 사전 계산하기 위한 예약된 쿼리
더 적은 데이터를 스캔하여 더 빠르게 로드하고 비용을 절감하도록 대시보드를 최적화하려는 경우 예약된 쿼리를 사용하여 이러한 집계를 사전 계산할 수 있습니다. Timestream for LiveAnalytics의 예약된 쿼리를 사용하면 나중에 대시보드에 사용할 수 있는 다른 Timestream for LiveAnalytics 테이블에서 이러한 사전 계산을 구체화할 수 있습니다.
예약된 쿼리를 생성하는 첫 번째 단계는 사전 계산하려는 쿼리를 식별하는 것입니다. 이전 대시보드는 us-east-1 리전에 대해 그려졌습니다. 하지만 다른 사용자는 다른 리전(예: us-west-2 또는 eu-west-1)에 대해 동일한 집계를 원할 수도 있습니다. 이러한 각 쿼리에 대해 예약된 쿼리를 생성하지 않으려면 각 리전의 집계를 사전 계산하고 다른 Timestream for LiveAnalytics 테이블에서 리전별 집계를 구체화할 수 있습니다.
아래 쿼리는 해당 사전 계산의 예를 제공합니다. 보시다시피, 이는 원시 데이터에 대한 쿼리에서 사용된 일반 테이블 표현식 grouped_data와 유사하지만 1) 리전 조건을 사용하지 않아 하나의 쿼리로 모든 리전에 대해 사전 계산을 수행할 수 있고, 2) 아래에서 자세히 설명하는 특수 파라미터 @scheduled_runtime을 사용하는 파라미터화된 시간 조건을 사용한다는 두 가지 차이점이 있습니다.
SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region
다음 사양을 사용하여 이전 쿼리를 예약된 쿼리로 변환할 수 있습니다. 예약된 쿼리에는 사용자에게 친숙한 니모닉인 이름이 할당됩니다. 그런 다음 cron 표현식인 ScheduleConfiguration인 QueryString이 포함됩니다. 쿼리 결과를 Timestream for LiveAnalytics의 대상 테이블에 매핑하는 TargetConfiguration을 지정합니다. 마지막으로 쿼리의 개별 실행에 대해 알림이 전송되는 NotificationConfiguration, 쿼리에 오류가 발생할 경우 보고서가 작성되는 ErrorReportConfiguration, 예약된 쿼리에 대한 작업을 수행하는 데 사용되는 역할인 ScheduledQueryExecutionRoleArn과 같은 여러 다른 구성을 지정합니다.
{ "Name": "MultiPT5mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/5 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt5m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
이 예에서 ScheduleExpression cron(0/5 * * * ? *)은 쿼리가 매일 매시간 5분, 10분, 15분, ..분에 5분마다 실행됨을 의미합니다. 이 쿼리의 특정 인스턴스가 트리거될 때 이러한 타임스탬프는 쿼리에 사용되는 @scheduled_runtime 파라미터로 변환됩니다. 2021-12-01 00:00:00에 실행되는 이 예약된 쿼리의 인스턴스를 예로 들 수 있습니다. 이 인스턴스에 대해 쿼리를 간접적으로 호출할 때 @scheduled_runtime 파라미터는 타임스탬프 2021-12-01 00:00:00으로 초기화됩니다. 따라서 이 특정 인스턴스는 타임스탬프 2021-12-01 00:00:00에 실행되며 시간 범위 2021-11-30 23:50:00에서 2021-12-01 00:01:00까지의 분당 집계를 계산합니다. 마찬가지로 이 쿼리의 다음 인스턴스는 타임스탬프 2021-12-01 00:05:00에 트리거되며,이 경우 쿼리는 시간 범위 2021-11-30 23:55:00에서 2021-12-01 00:06:00까지의 분당 집계를 계산합니다. 따라서 @scheduled_runtime 파라미터는 쿼리에 대한 간접 호출 시간을 사용하여 구성된 시간 범위에 대한 집계를 사전 계산하는 예약된 쿼리를 제공합니다.
쿼리의 두 후속 인스턴스는 시간 범위에서 겹칩니다. 이는 요구 사항에 따라 제어할 수 있는 것입니다. 이 경우 이러한 중복을 통해 이 쿼리는 이 예제에서 최대 5분까지 도착이 약간 지연된 모든 데이터를 기반으로 집계를 업데이트할 수 있습니다. 구체화된 쿼리의 정확성을 보장하기 위해 Timestream for LiveAnalytics는 2021-12-01 00:00:00의 쿼리가 완료된 후에만 2021-12-01 00:05:00의 쿼리가 수행되도록 하며, 후자의 쿼리 결과는 새 값이 생성되는 경우를 사용하여 이전에 구체화된 집계를 업데이트할 수 있습니다. 예를 들어 타임스탬프 2021-11-30 23:59:00의 일부 데이터가 2021-12-01 00:00:00에 대한 쿼리 실행 후 2021-12-01 00:05:00에 대한 쿼리 이전에 도착한 경우 2021-12-01 00:05:00의 실행은 2021-11-30 23:59:00분에 대한 집계를 다시 계산하고 이로 인해 이전 집계가 새로 계산된 값으로 업데이트됩니다. 예약된 쿼리의 이러한 의미에 의존하여 사전 계산을 업데이트하는 속도와 도착이 지연된 일부 데이터를 정상적으로 처리하는 방법 간의 균형을 맞출 수 있습니다. 데이터의 최신성과 이 새로 고침 주기를 절충하는 방법과 훨씬 더 지연된 상태로 도착하는 데이터에 대한 집계 업데이트를 해결하는 방법 또는 예약된 계산의 소스에 집계를 다시 계산해야 하는 업데이트된 값이 있는지 여부에 대한 추가 고려 사항이 아래에 설명되어 있습니다.
예약된 모든 계산에는 Timestream for LiveAnalytics가 예약된 구성의 모든 실행에 대한 알림을 보내는 알림 구성이 있습니다. 각 간접 호출에 대한 알림을 수신하도록 SNS 주제를 구성할 수 있습니다. 특정 인스턴스의 성공 또는 실패 상태 외에도 이 계산이 실행되는 데 걸린 시간, 스캔한 계산 바이트 수, 계산이 대상 테이블에 쓴 바이트 수와 같은 여러 통계가 있습니다. 이러한 통계를 사용하여 쿼리를 추가로 조정하거나, 구성을 예약하거나, 예약된 쿼리에 대한 지출을 추적할 수 있습니다. 주목할 만한 한 가지 측면은 인스턴스의 실행 시간입니다. 이 예제에서는 예약된 계산이 5분마다를 실행하도록 구성됩니다. 실행 시간에 따라 사전 계산을 사용할 수 있는 지연이 결정되며, 대시보드에서 사전 계산된 데이터를 사용할 때 대시보드의 지연 시간도 정의됩니다. 또한 이 지연이 새로 고침 간격보다 일관되게 높은 경우, 예를 들어 5분마다 새로 고치도록 구성된 계산의 실행 시간이 5분 이상인 경우 대시보드에서 추가 지연을 방지하기 위해 더 빠르게 실행되도록 계산을 조정하는 것이 중요합니다.
파생 테이블에서 집계
이제 예약된 쿼리를 설정하고 집계가 미리 계산되어 예약된 계산의 대상 구성에 지정된 다른 Timestream for LiveAnalytics 테이블로 구체화되었으므로 해당 테이블의 데이터를 사용하여 SQL 쿼리를 작성하여 대시보드를 구동할 수 있습니다. 다음은 구체화된 사전 집계를 사용하여 us-east-1에 대한 분당 데이터 포인트 수 집계를 생성하는 쿼리와 동일합니다.
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY bin(time, 1m) ORDER BY 1 desc
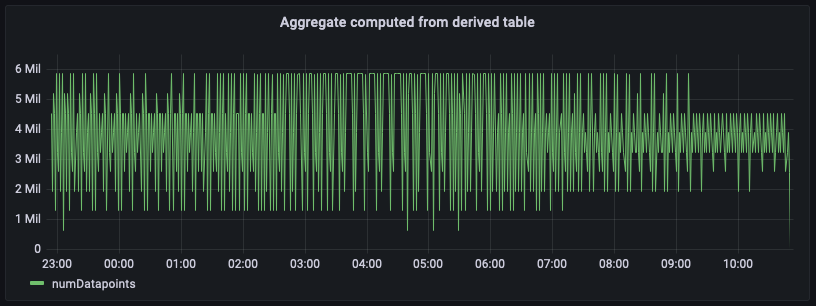
이전 그림은 집계 테이블에서 계산된 집계를 표시합니다. 이 패널을 원시 소스 데이터에서 계산된 패널과 비교하면 정확히 일치하지만 이러한 집계는 예약된 계산에 대해 구성한 새로 고침 간격과 이를 실행하는 시간에 의해 제어되는 몇 분 정도 지연됩니다.
사전 계산된 데이터에 대한이 쿼리는 원시 소스 데이터에 대해 계산된 집계에 비해 몇 배 더 적은 데이터를 스캔합니다. 집계의 세부 수준에 따라 이러한 감소로 인해 비용이 100X 절감되고 쿼리 지연 시간이 발생할 수 있습니다. 이 예약된 계산을 실행하는 데 비용이 발생합니다. 그러나 이러한 대시보드를 새로 고치는 빈도와 이러한 대시보드를 로드하는 동시 사용자 수에 따라 이러한 사전 계산을 사용하여 전체 비용을 크게 절감할 수 있습니다. 또한 대시보드의 로드 시간이 10-100X 빨라졌습니다.
소스 테이블과 파생 테이블의 결합 집계
파생 테이블을 사용하여 생성된 대시보드에는 지연이 있을 수 있습니다. 애플리케이션 시나리오에서 대시보드에 최신 데이터가 있어야 하는 경우 Timestream for LiveAnalytics SQL 지원의 성능과 유연성을 사용하여 소스 테이블의 최신 데이터를 파생 테이블의 과거 집계와 결합하여 병합된 보기를 구성할 수 있습니다. 이 병합된 뷰는 SQL의 조합 시맨틱과 소스 및 파생 테이블의 겹치지 않는 시간 범위를 사용합니다. 아래 예제에서는 "derived"."per_minute_aggs_pt5m" 파생 테이블을 사용하고 있습니다. 파생 테이블에 대한 예약된 계산이 5분마다 한 번씩 새로 고쳐지기 때문에(예약 표현식 사양에 따라) 아래 쿼리는 소스 테이블의 최근 15분 데이터를 사용합니다. 및 파생 테이블에서 15분 이상 지난 모든 데이터를 통합한 다음 결과를 결합하여 두 월드를 모두 최대한 활용하는 병합된 뷰를 생성합니다. 파생 테이블에서 사전 계산된 오래된 집계를 읽고 소스 테이블에서 집계의 최신성을 읽어 실시간 분석 사용 사례를 강화함으로써 경제성과 짧은 지연 시간을 제공합니다.
가장 최근 시간 간격을 채우기 위해 원시 데이터를 실시간으로 집계하므로 이 통합 접근 방식은 파생 테이블만 쿼리하는 것에 비해 쿼리 지연 시간이 약간 더 길고 스캔된 데이터도 약간 더 깁니다. 그러나 이 병합된 뷰는 특히 며칠 또는 몇 주 분량의 데이터를 렌더링하는 대시보드의 경우 소스 테이블에서 즉시 집계하는 것보다 훨씬 빠르고 저렴합니다. 이 예제의 시간 범위를 조정하여 애플리케이션의 새로 고침 요구 사항과 지연 허용치를 조정할 수 있습니다.
WITH aggregated_source_data AS ( SELECT bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDatapoints FROM "raw_data"."devops" WHERE time BETWEEN bin(from_milliseconds(1636743196439), 1m) - 15m AND from_milliseconds(1636743196439) AND region = 'us-east-1' GROUP BY bin(time, 1m) ), aggregated_derived_data AS ( SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996439) AND bin(from_milliseconds(1636743196439), 1m) - 15m AND region = 'us-east-1' GROUP BY bin(time, 1m) ) SELECT minute, numDatapoints FROM ( ( SELECT * FROM aggregated_derived_data ) UNION ( SELECT * FROM aggregated_source_data ) ) ORDER BY 1 desc
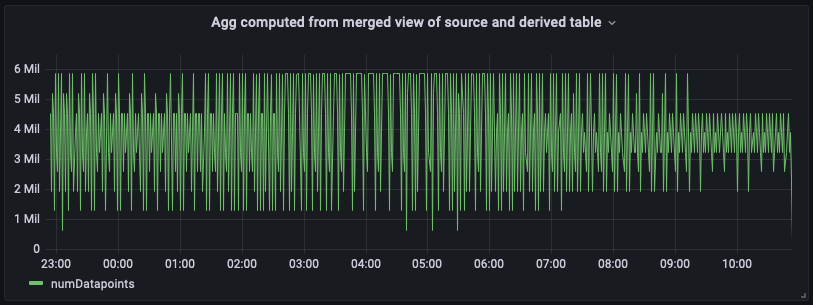
다음은 이 통합 병합 보기가 있는 대시보드 패널입니다. 보시다시피 대시보드는 가장 오른쪽 끝에 up-to-date 집계가 있다는 점을 제외하면 파생 테이블에서 계산된 보기와 거의 동일하게 보입니다.
자주 새로 고쳐지는 예약된 계산에서 집계
대시보드가 로드되는 빈도와 대시보드에 원하는 지연 시간에 따라 대시보드에서 최신 결과를 얻는 또 다른 접근 방식, 즉 예약된 계산으로 집계를 더 자주 새로 고치는 방법이 있습니다. 예를 들어, 아래는 동일한 예약 계산의 구성이지만, 1분마다 새로 고쳐집니다(schedule express cron(0/1 * * * ? *)에 유의). 이 설정으로 인해, 파생 테이블 per_minute_aggs_pt1m은 계산에서 5분마다 한 번씩 새로 고침 일정을 지정했던 시나리오에 비해 훨씬 더 최신의 집계를 갖게 됩니다.
{ "Name": "MultiPT1mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/1 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt1m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt1m" WHERE time BETWEEN from_milliseconds(1636699996446) AND from_milliseconds(1636743196446) AND region = 'us-east-1' GROUP BY bin(time, 1m), region ORDER BY 1 desc
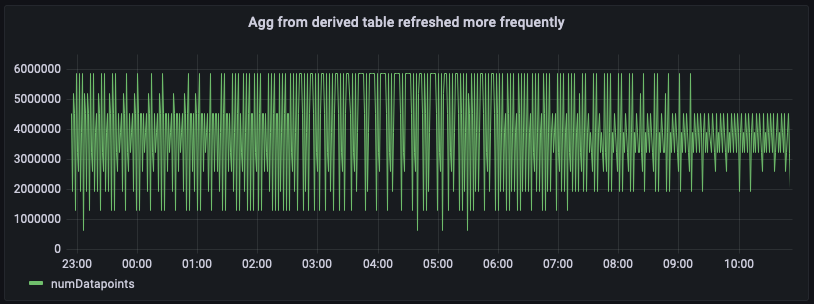
파생 테이블에 더 최신 집계가 있으므로 이제 이전 쿼리와 아래 대시보드 스냅샷에서 볼 수 있듯이 파생 테이블 per_minute_aggs_pt1m을 직접 쿼리하여 더 최신 집계를 가져올 수 있습니다.
예약된 계산을 더 빠른 일정(예: 1분, 5분)으로 새로 고치면 예약된 계산의 유지 관리 비용이 증가합니다. 모든 계산 실행에 대한 알림 메시지는 스캔된 데이터의 양과 파생 테이블에 작성된 데이터의 양에 대한 통계를 제공합니다. 마찬가지로 병합된 뷰를 사용하여 파생 테이블을 결합하는 경우 병합된 뷰의 비용을 쿼리하면 파생 테이블만 쿼리하는 것보다 대시보드 로드 지연 시간이 길어집니다. 따라서 선택하는 접근 방식은 대시보드를 새로 고치는 빈도와 예약된 쿼리의 유지 관리 비용에 따라 달라집니다. 수십 명의 사용자가 1분에 한 번 정도 대시보드를 새로 고치는 경우 파생 테이블을 더 자주 새로 고치면 전반적으로 비용이 절감될 수 있습니다.
