Amazon Timestream for LiveAnalytics와 유사한 기능을 원하는 경우 Amazon Timestream for InfluxDB를 고려해 보세요. 간소화된 데이터 수집과 실시간 분석을 위한 10밀리초 미만의 쿼리 응답 시간을 제공합니다. 여기에서 자세히 알아보세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
대시보드 간에 예약된 쿼리를 공유하여 비용 최적화
이 예제에서는 여러 대시보드 패널이 유사한 정보의 변형(높은 CPU 호스트 및 CPU 사용률이 높은 플릿 비율 찾기)을 표시하는 시나리오와 동일한 예약된 쿼리를 사용하여 결과를 미리 계산한 다음 여러 패널을 채우는 방법을 살펴보겠습니다. 이렇게 재사용하면 각 패널마다 하나씩 서로 다른 예약된 쿼리를 사용하는 대신 소유자만 사용하는 비용을 더욱 최적화할 수 있습니다.
원시 데이터가 있는 대시보드 패널
마이크로서비스별 리전당 CPU 사용률
첫 번째 패널은 리전, 셀, 사일로, 가용 영역 및 마이크로서비스 내에서 지정된 배포에 대한 평균 CPU 사용률이 위의 CPU 사용률보다 낮거나 높은 임곗값인 인스턴스를 계산합니다. 그런 다음 사용률이 높은 호스트 비율이 가장 높은 리전과 마이크로서비스를 정렬합니다. 특정 배포의 서버가 얼마나 더운지 식별한 다음 드릴다운하여 문제를 더 잘 이해하는 데 도움이 됩니다.
패널에 대한 쿼리는 일반 테이블 표현식, 창 함수, 조인 등을 사용하여 복잡한 분석 태스크를 수행할 수 있는 Timestream for LiveAnalytics의 SQL 지원의 유연성을 보여줍니다.

쿼리:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization) * 100.0 / COUNT(*), 0) AS percent_low_utilization_hosts FROM instances_above_threshold GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
마이크로서비스로 드릴다운하여 핫스팟 찾기
다음 대시보드를 사용하면 마이크로서비스 중 하나를 심층적으로 분석하여 해당 마이크로서비스의 특정 리전, 셀 및 사일로가 더 높은 CPU 사용률로 플릿의 몇 분이나 실행되고 있는지 확인할 수 있습니다. 예를 들어 플릿 전체 대시보드에서 마이크로서비스 측정기가 상위 몇 개의 순위 위치에 표시되는 것을 확인했으므로 이 대시보드에서는 해당 마이크로서비스를 자세히 살펴보려고 합니다.
이 대시보드는 변수를 사용하여 드릴다운할 마이크로서비스를 선택하고 변수의 값은 차원의 고유 값을 사용하여 채워집니다. 마이크로서비스를 선택하면 나머지 대시보드가 새로 고쳐집니다.
아래에서 볼 수 있듯이 첫 번째 패널은 시간 경과에 따른 배포(마이크로서비스의 경우 리전, 셀 및 사일로)의 호스트 백분율과 대시보드를 표시하는 데 사용되는 해당 쿼리를 표시합니다. 이 플롯 자체는 CPU가 높은 호스트의 비율이 높은 특정 배포를 식별합니다.

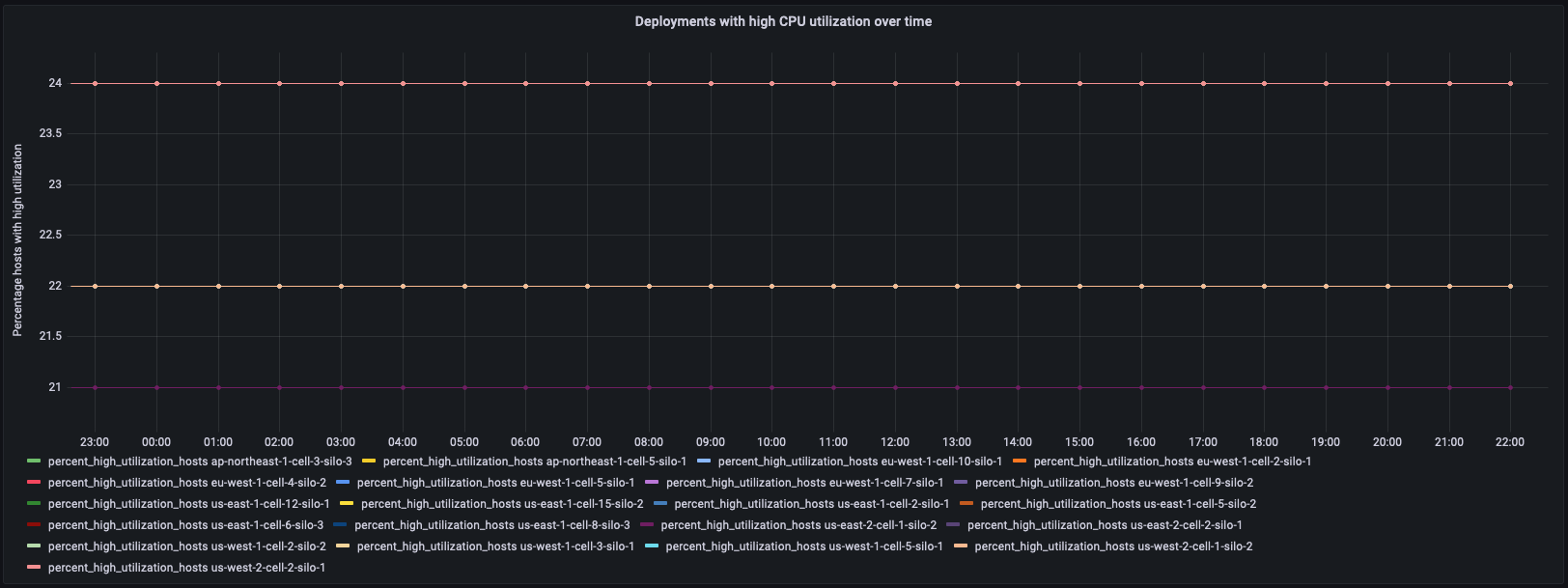
쿼리:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ), high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
단일 예약된 쿼리로 변환하여 재사용 가능
두 대시보드의 여러 패널에서 유사한 계산이 수행된다는 점에 유의해야 합니다. 각 패널에 대해 별도의 예약된 쿼리를 정의할 수 있습니다. 여기에서는 세 패널을 모두 렌더링하는 데 결과를 사용할 수 있는 하나의 예약된 쿼리를 정의하여 비용을 추가로 최적화하는 방법을 확인할 수 있습니다.
다음은 서로 다른 모든 패널에 대해 계산되고 사용되는 집계를 캡처하는 쿼리입니다. 이 예약된 쿼리의 정의에서 몇 가지 중요한 측면을 관찰합니다.
-
일반 테이블 표현식, 조인, 대/소문자 설명 등을 사용할 수 있는 예약된 쿼리에서 지원하는 SQL 표면 영역의 유연성과 기능입니다.
-
하나의 예약된 쿼리를 사용하여 특정 대시보드에 필요할 수 있는 것보다 세분화된 통계와 대시보드가 다양한 변수에 사용할 수 있는 모든 값을 계산할 수 있습니다. 예를 들어 집계는 리전, 셀, 사일로 및 마이크로서비스에서 계산됩니다. 따라서 이를 결합하여 리전 수준 또는 리전과 마이크로서비스 수준 집계를 생성할 수 있습니다. 마찬가지로 동일한 쿼리는 모든 리전, 셀, 사일로 및 마이크로서비스에 대한 집계를 계산합니다. 이를 통해 이러한 열에 필터를 적용하여 값의 하위 집합에 대한 집계를 얻을 수 있습니다. 예를 들어 us-east-1과 같은 리전 하나 또는 리전, 셀, 사일로 및 마이크로서비스 내의 특정 배포에 대해 측정하거나 드릴다운하는 마이크로서비스 하나에 대한 집계를 계산할 수 있습니다. 이 접근 방식은 사전 계산된 집계를 유지하는 데 드는 비용을 더욱 최적화합니다.
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour
다음은 이전 쿼리에 대해 예약된 쿼리 정의입니다. 예약 표현식은 30분마다 새로 고치도록 구성되어 있으며, 최대 1시간 전까지의 데이터를 새로 고칩니다. 이때 bin(@scheduled_runtime, 1h) 구문을 사용하여 해당 시간대의 전체 이벤트를 가져옵니다. 애플리케이션의 최신성 요구 사항에 따라 더 자주 또는 덜 자주 새로 고치도록 구성할 수 있습니다. WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h를 사용하면 15분마다 새로 고치더라도 현재 시간대와 이전 시간대의 전체 1시간 데이터를 얻을 수 있습니다.
나중에 세 개의 패널이 테이블 deployment_cpu_stats_per_hr에 작성된 이러한 집계를 사용하여 패널과 관련된 지표를 시각화하는 방법을 살펴보겠습니다.
{ "Name": "MultiPT30mHighCpuDeploymentsPerHr", "QueryString": "WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/30 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "deployment_cpu_stats_per_hr", "TimeColumn": "hour", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" }, { "Name": "cell", "DimensionValueType": "VARCHAR" }, { "Name": "silo", "DimensionValueType": "VARCHAR" }, { "Name": "microservice_name", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "cpu_user", "MultiMeasureAttributeMappings": [ { "SourceColumn": "num_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "high_utilization_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "low_utilization_hosts", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
사전 계산된 결과의 대시보드
높은 CPU 사용률 호스트
사용률이 높은 호스트의 경우 여러 패널이 deployment_cpu_stats_per_hr의 데이터를 사용하여 패널에 필요한 다양한 집계를 계산하는 방법을 살펴보겠습니다. 예를 들어 이 패널은 리전 수준 정보를 제공하므로 리전 또는 마이크로서비스를 필터링하지 않고 리전 및 마이크로서비스별로 그룹화된 집계를 보고합니다.
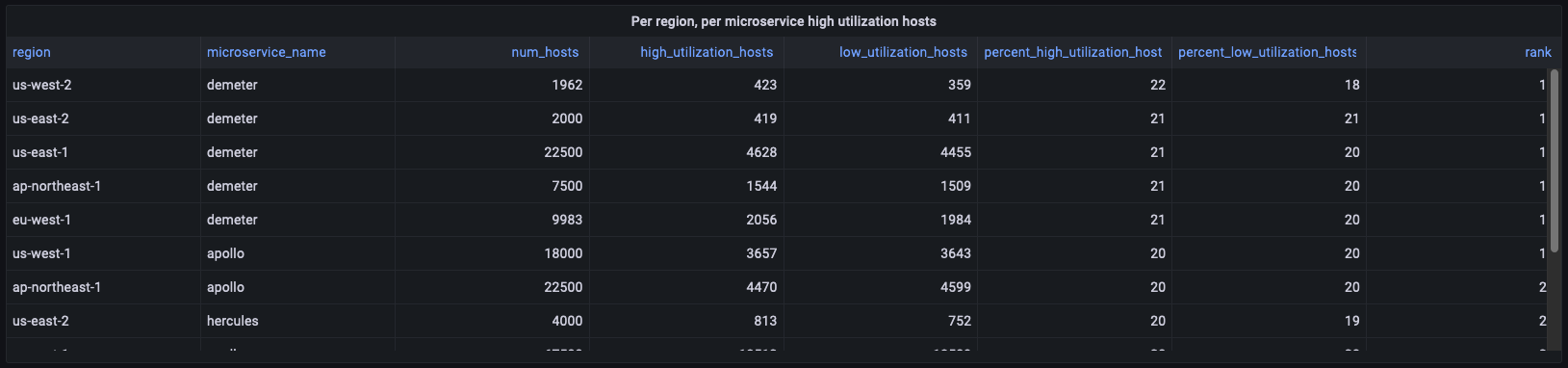
WITH per_deployment_hosts AS ( SELECT region, cell, silo, microservice_name, AVG(num_hosts) AS num_hosts, AVG(high_utilization_hosts) AS high_utilization_hosts, AVG(low_utilization_hosts) AS low_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636567785437) AND from_milliseconds(1636654185437) AND measure_name = 'cpu_user' GROUP BY region, cell, silo, microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, SUM(num_hosts) AS num_hosts, ROUND(SUM(high_utilization_hosts), 0) AS high_utilization_hosts, ROUND(SUM(low_utilization_hosts),0) AS low_utilization_hosts, ROUND(SUM(high_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_low_utilization_hosts FROM per_deployment_hosts GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
마이크로서비스로 드릴다운하여 높은 CPU 사용량 배포 찾기
다음 예제에서는 deployment_cpu_stats_per_hr 파생 테이블을 다시 사용하지만 이번에는 특정 마이크로서비스에 대한 필터를 적용합니다. 이 예제에서는 집계 대시보드에서 높은 사용률의 호스트를 보고했기 때문에 demeter에 대한 필터를 적용합니다. 이 패널은 시간 경과에 따른 높은 CPU 사용률 호스트의 비율을 추적합니다.
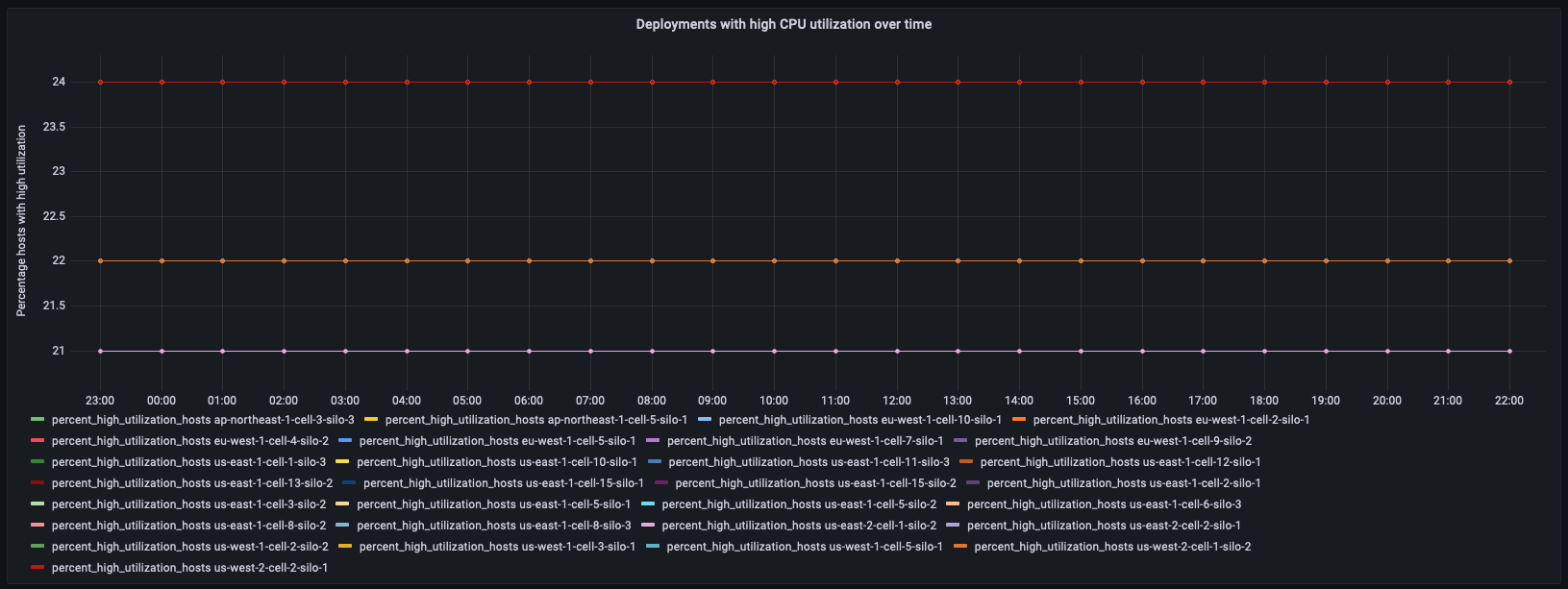
WITH high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, bin(time, 1h) AS hour, MAX(num_hosts) AS num_hosts, MAX(high_utilization_hosts) AS high_utilization_hosts, ROUND(MAX(high_utilization_hosts) * 100.0 / MAX(num_hosts)) AS percent_high_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636525800000) AND from_milliseconds(1636612200000) AND measure_name = 'cpu_user' AND microservice_name = 'demeter' GROUP BY region, cell, silo, microservice_name, bin(time, 1h) ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
