Amazon Timestream for LiveAnalytics와 유사한 기능을 원하는 경우 Amazon Timestream for InfluxDB를 고려해 보세요. 간소화된 데이터 수집과 실시간 분석을 위한 10밀리초 미만의 쿼리 응답 시간을 제공합니다. 여기에서 자세히 알아보세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
UNLOAD 개념
구문
UNLOAD (SELECT statement) TO 's3://bucket-name/folder' WITH ( option = expression [, ...] )
여기서 option은
{ partitioned_by = ARRAY[ col_name[,…] ] | format = [ '{ CSV | PARQUET }' ] | compression = [ '{ GZIP | NONE }' ] | encryption = [ '{ SSE_KMS | SSE_S3 }' ] | kms_key = '<string>' | field_delimiter ='<character>' | escaped_by = '<character>' | include_header = ['{true, false}'] | max_file_size = '<value>' | }
파라미터
- SELECT 명령문
-
하나 이상의 Timestream for LiveAnalytics 테이블에서 데이터를 선택하고 검색하는 데 사용되는 쿼리 문입니다.
(SELECT column 1, column 2, column 3 from database.table where measure_name = "ABC" and timestamp between ago (1d) and now() ) - TO 절
-
TO 's3://bucket-name/folder'또는
TO 's3://access-point-alias/folder'UNLOAD문의TO절은 쿼리 결과의 출력 대상을 지정합니다. Timestream for LiveAnalytics가 출력 파일 객체를 저장하는 Amazon S3 버킷 이름 또는 Amazon S3 액세스 포인트 별칭과 폴더 위치를 포함한 전체 경로를 제공해야 합니다. S3 버킷은 동일한 계정 소유여야 하며 동일한 리전에 있어야 합니다. 쿼리 결과 세트 외에도 Timestream for LiveAnalytics는 지정된 대상 폴더에 매니페스트 및 메타데이터 파일을 씁니다. - PARTITIONED_BY 절
-
partitioned_by = ARRAY [col_name[,…] , (default: none)partitioned_by절은 쿼리에서 데이터를 세분화된 수준으로 그룹화하고 분석하는 데 사용됩니다. S3 버킷으로 쿼리 결과를 내보낼 때 select 쿼리의 하나 이상의 열을 기준으로 데이터를 파티셔닝하도록 선택할 수 있습니다. 데이터를 파티셔닝할 때 내보낸 데이터는 파티션 열을 기준으로 하위 집합으로 분할되고 각 하위 집합은 별도의 폴더에 저장됩니다. 내보낸 데이터가 포함된 결과 폴더 내에 하위 폴더folder/results/partition column = partition value/가 자동으로 생성됩니다. 그러나 파티셔닝된 열은 출력 파일에 포함되지 않습니다.partitioned_by는 구문의 필수 절이 아닙니다. 파티셔닝 없이 데이터를 내보내기로 선택한 경우 구문에서 해당 절을 생략할 수 있습니다.예
웹사이트의 클릭스트림 데이터를 모니터링하고 있으며
direct,Social Media,Organic Search,Other,Referral의 5가지 트래픽 채널이 있다고 가정해 보겠습니다. 데이터를 내보낼 때Channel열을 사용하여 데이터를 파티셔닝하도록 선택할 수 있습니다. 데이터 폴더인s3://bucketname/results안에는 각 채널 이름으로 된 5개의 폴더가 있습니다. 예를 들면s3://bucketname/results/channel=Social Media/.입니다. 이 폴더 안에는Social Media채널을 통해 웹사이트에 방문한 모든 고객의 데이터가 포함되어 있습니다. 나머지 채널을 위한 다른 폴더도 있습니다.채널 열을 기준으로 파티셔닝된 내보낸 데이터
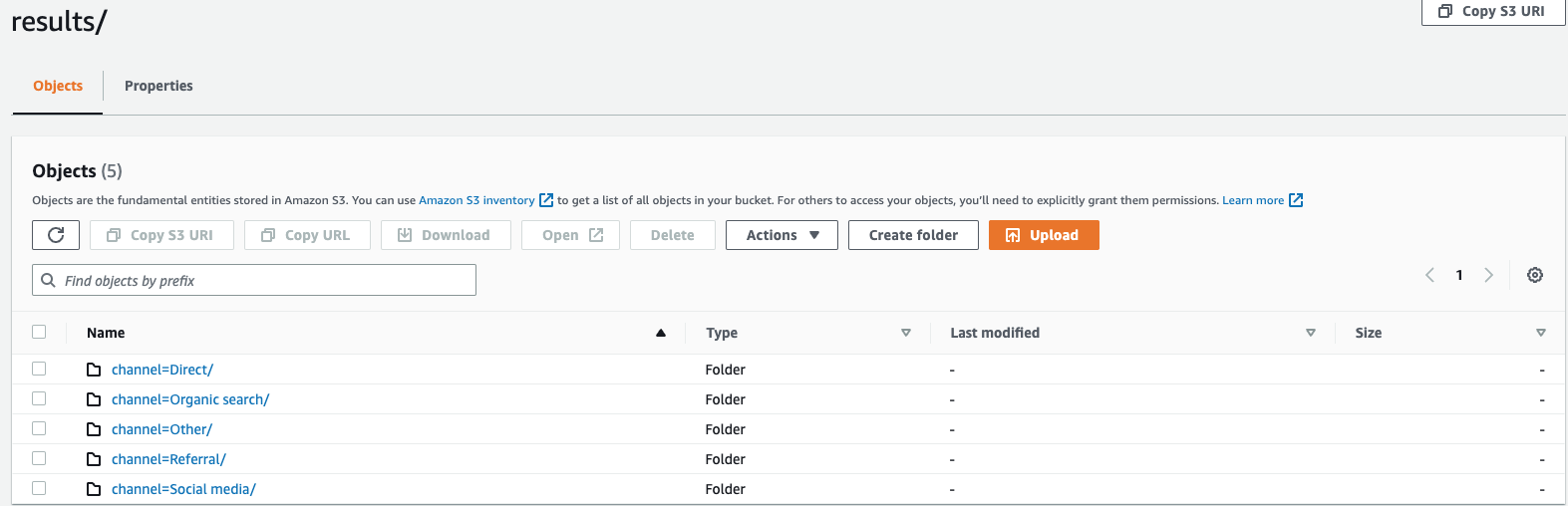
- FORMAT
-
format = [ '{ CSV | PARQUET }' , default: CSVS3 버킷에 작성된 쿼리 결과의 형식을 지정하는 키워드입니다. 쉼표(,)를 기본 구분 기호로 사용하거나 분석을 위한 효율적인 개방형 컬럼형 스토리지 형식인 Apache Parquet 형식으로 데이터를 쉼표로 구분된 값(CSV)으로 내보낼 수 있습니다.
- COMPRESSION
-
compression = [ '{ GZIP | NONE }' ], default: GZIP압축 알고리즘 GZIP을 사용하여 내보낸 데이터를 압축하거나
NONE옵션을 지정하여 압축을 해제할 수 있습니다. - ENCRYPTION
-
encryption = [ '{ SSE_KMS | SSE_S3 }' ], default: SSE_S3Amazon S3의 출력 파일은 선택한 암호화 옵션을 사용하여 암호화됩니다. 데이터 외에도 선택한 암호화 옵션에 따라 매니페스트 파일과 메타데이터 파일도 암호화됩니다. 현재 SSE_S3 및 SSE_KMS 암호화를 지원합니다. SSE_S3는 Amazon S3가 256비트 고급 암호화 표준(AES) 암호화를 사용하여 데이터를 암호화하는 서버 측 암호화입니다. SSE_KMS는 고객 관리형 키를 사용하여 데이터를 암호화하는 서버 측 암호화입니다.
- KMS_KEY
-
kms_key = '<string>'KMS 키는 내보낸 쿼리 결과를 암호화하기 위한 고객 정의 키입니다. KMS 키는 AWS Key Management Service(AWS KMS)에서 안전하게 관리되며 Amazon S3의 데이터 파일을 암호화하는 데 사용됩니다.
- FIELD_DELIMITER
-
field_delimiter ='<character>' , default: (,)데이터를 CSV 형식으로 내보낼 때 이 필드는 파이프 문자(|), 쉼표(,) 또는 탭(\t) 같이 출력 파일에서 필드를 구분할 때 사용할 단일 ASCII 문자를 지정합니다. CSV 파일의 기본 구분 기호는 쉼표 문자입니다. 데이터의 값에 선택한 구분 기호가 포함되어 있으면 해당 구분 기호는 따옴표로 묶입니다. 예를 들어, 데이터의 값에
Time,stream이 포함되어 있으면 이 값은 내보낸 데이터에서"Time,stream"으로 따옴표 처리됩니다. Timestream for LiveAnalytics에서 사용하는 따옴표 문자는 큰따옴표(")입니다.CSV에 헤더를 포함시키려면 캐리지 리턴 문자(ASCII 13, 16진수
0D, 텍스트 '\r') 또는 줄 바꿈 문자(ASCII 10, 16진수 0A, 텍스트 '\n')를FIELD_DELIMITER로 지정하지 마세요. 그러면 많은 파서가 결과 CSV 출력에서 헤더를 제대로 구문 분석하지 못합니다. - ESCAPED_BY
-
escaped_by = '<character>', default: (\)CSV 형식으로 데이터를 내보낼 때 이 필드는 S3 버킷에 작성되는 데이터 파일에서 이스케이프 문자로 처리되어야 하는 문자를 지정합니다. 다음 시나리오에서 이스케이프가 발생할 수 있습니다.
-
자체에 따옴표(") 문자를 포함하는 값은 이스케이프 문자를 사용하여 이스케이프 처리됩니다. 예를 들어, 값이
Time"stream이고 (\)가 구성된 이스케이프 문자인 경우Time\"stream으로 이스케이프 처리됩니다. -
구성된 이스케이프 문자를 포함하는 값은 이스케이프 처리됩니다. 예를 들어 값이
Time\stream인 경우Time\\stream으로 이스케이프 처리됩니다.
참고
배열, 행 또는 시계열과 같은 복소수 데이터 유형을 포함하는 내보낸 출력은 JSON 문자열로 직렬화됩니다. 다음은 한 예입니다.
데이터 유형 실제 값 값이 CSV 형식으로 이스케이프 처리되는 방법 [직렬화된 JSON 문자열] 배열
[ 23,24,25 ]"[23,24,25]"열
( x=23.0, y=hello )"{\"x\":23.0,\"y\":\"hello\"}"시계열
[ ( time=1970-01-01 00:00:00.000000010, value=100.0 ),( time=1970-01-01 00:00:00.000000012, value=120.0 ) ]"[{\"time\":\"1970-01-01 00:00:00.000000010Z\",\"value\":100.0},{\"time\":\"1970-01-01 00:00:00.000000012Z\",\"value\":120.0}]" -
- INCLUDE_HEADER
-
include_header = 'true' , default: 'false'CSV 형식으로 데이터를 내보낼 때 이 필드를 사용하면 내보낸 CSV 데이터 파일의 첫 번째 행으로 열 이름을 포함할 수 있습니다.
허용되는 값은 'true'와 'false'이고 기본값은 'false'입니다.
escaped_by,field_delimiter등의 텍스트 변환 옵션은 헤더에도 적용됩니다.참고
헤더를 포함할 때 캐리지 리턴 문자(ASCII 13, 16진수 0D, 텍스트 '\r') 또는 줄 바꿈 문자(ASCII 10, 16진수 0A, 텍스트 '\n')를
FIELD_DELIMITER로 선택하면 안 됩니다. 그러면 많은 파서가 결과 CSV 출력에서 헤더를 제대로 구문 분석하지 못합니다. - MAX_FILE_SIZE
-
max_file_size = 'X[MB|GB]' , default: '78GB'이 필드는
UNLOAD문이 Amazon S3에 생성하는 파일의 최대 크기를 지정합니다.UNLOAD문은 여러 파일을 생성할 수 있지만 Amazon S3에 작성되는 각 파일의 최대 크기는 이 필드에 지정된 값과 대략 일치합니다.필드 값은 16MB에서 78GB 사이(포함)여야 합니다.
12GB와 같은 정수로 지정하거나0.5GB또는24.7MB와 같은 소수로 지정할 수 있습니다. 기본값은 78GB입니다.파일을 쓸 때 실제 파일 크기는 근사값이므로 실제 최대 크기가 지정한 숫자와 정확히 같지 않을 수 있습니다.
S3 버킷에는 무엇이 작성되나요?
성공적으로 실행된 모든 UNLOAD 쿼리에 대해 Timestream for LiveAnalytics는 S3 버킷에 쿼리 결과, 메타데이터 파일 및 매니페스트 파일을 작성합니다. 데이터를 파티셔닝한 경우 결과 폴더에 모든 파티션 폴더가 있습니다. 매니페스트 파일에는 UNLOAD 명령에 의해 작성된 파일 목록이 포함되어 있습니다. 메타데이터 파일에는 작성된 데이터의 특성과 속성을 설명하는 정보가 포함되어 있습니다.
내보낸 파일 이름은 무엇인가요?
내보낸 파일 이름은 두 가지 구성 요소로 이루어져 있습니다. 첫 번째 구성 요소는 queryID이고, 두 번째 구성 요소는 고유 식별자입니다.
CSV 파일
S3://bucket_name/results/<queryid>_<UUID>.csv S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.csv
압축된 CSV 파일
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.gz
Parquet 파일
S3://bucket_name/results/<partitioncolumn>=<partitionvalue>/<queryid>_<UUID>.parquet
메타데이터 및 매니페스트 파일
S3://bucket_name/<queryid>_<UUID>_manifest.json S3://bucket_name/<queryid>_<UUID>_metadata.json
CSV 형식의 데이터는 파일 수준에서 저장되므로 S3로 내보낼 때 데이터를 압축하면 파일 확장자가 ‘.gz’가 됩니다. 그러나 Parquet의 데이터는 열 수준에서 압축되므로 내보내는 동안 데이터를 압축하더라도 파일 확장자는 여전히 .parquet입니다.
각 파일에는 어떤 정보가 포함되어 있나요?
매니페스트 파일
매니페스트 파일은 UNLOAD 실행 시 내보내지는 파일 목록에 대한 정보를 제공합니다. 매니페스트 파일은 파일 이름이 s3://<bucket_name>/<queryid>_<UUID>_manifest.json인 제공된 S3 버킷에 있습니다. 매니페스트 파일에는 결과 폴더 내 파일의 URL, 각 파일의 레코드 수 및 크기, 쿼리 메타데이터(쿼리에 대해 S3로 내보낸 총 바이트 수와 총 행 수)가 포함됩니다.
{ "result_files": [ { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 32295, "row_count": 10 } }, { "url":"s3://my_timestream_unloads/ec2_metrics/AEDAGANLHLBH4OLISD3CVOZZRWPX5GV2XCXRBKCVD554N6GWPWWXBP7LSG74V2Q_1448466917_szCL4YgVYzGXj2lS.gz", "file_metadata": { "content_length_in_bytes": 62295, "row_count": 20 } }, ], "query_metadata": { "content_length_in_bytes": 94590, "total_row_count": 30, "result_format": "CSV", "result_version": "Amazon Timestream version 1.0.0" }, "author": { "name": "Amazon Timestream", "manifest_file_version": "1.0" } }
Metadata
메타데이터 파일은 데이터세트에 대한 열 이름, 열 유형, 스키마 등의 추가 정보를 제공합니다. 메타데이터 파일은 파일 이름이 S3://bucket_name/<queryid>_<UUID>_metadata.json인 제공된 S3 버킷에서 사용할 수 있습니다.
다음은 메타데이터 파일의 예제입니다.
{ "ColumnInfo": [ { "Name": "hostname", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "region", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "measure_name", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "cpu_utilization", "Type": { "TimeSeriesMeasureValueColumnInfo": { "Type": { "ScalarType": "DOUBLE" } } } } ], "Author": { "Name": "Amazon Timestream", "MetadataFileVersion": "1.0" } }
메타데이터 파일에 공유된 열 정보는 SELECT 쿼리에 대한 쿼리 API 응답에서 전송되는 ColumnInfo와 동일한 구조를 가집니다.
결과
결과 폴더에는 내보낸 데이터가 Apache Parquet 또는 CSV 형식으로 포함되어 있습니다.
예제
쿼리 API를 통해 아래와 같은 UNLOAD 쿼리를 제출하면
UNLOAD(SELECT user_id, ip_address, event, session_id, measure_name, time, query, quantity, product_id, channel FROM sample_clickstream.sample_shopping WHERE time BETWEEN ago(2d) AND now()) TO 's3://my_timestream_unloads/withoutpartition/' WITH ( format='CSV', compression='GZIP')
UNLOAD 쿼리 응답에는 행 1개 * 열 3개가 있습니다. 이러한 3개의 열은 다음과 같습니다.
-
BIGINT 유형의 행 - 내보낸 행 수를 나타냄
-
VARCHAR 유형의 metadataFile - 내보낸 메타데이터 파일의 S3 URI
-
VARCHAR 유형의 manifestFile - 내보낸 매니페스트 파일의 S3 URI
쿼리 API로부터 다음과 같은 응답을 받게 됩니다.
{ "Rows": [ { "Data": [ { "ScalarValue": "20" # No of rows in output across all files }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_metadata.json" #Metadata file }, { "ScalarValue": "s3://my_timestream_unloads/withoutpartition/AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY_<UUID>_manifest.json" #Manifest file } ] } ], "ColumnInfo": [ { "Name": "rows", "Type": { "ScalarType": "BIGINT" } }, { "Name": "metadataFile", "Type": { "ScalarType": "VARCHAR" } }, { "Name": "manifestFile", "Type": { "ScalarType": "VARCHAR" } } ], "QueryId": "AEDAAANGH3D7FYHOBQGQQMEAISCJ45B42OWWJMOT4N6RRJICZUA7R25VYVOHJIY", "QueryStatus": { "ProgressPercentage": 100.0, "CumulativeBytesScanned": 1000, "CumulativeBytesMetered": 10000000 } }
데이터 타입
UNLOAD 문은 지원되는 데이터 유형에 설명된 Timestream for LiveAnalytics의 모든 데이터 유형을 지원하지만 time과 unknown은 지원하지 않습니다.
