기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Managed Service for Apache Flink란 무엇인가요?
Amazon Managed Service for Apache Flink에서는 Java, Scala, Python 또는 SQL을 사용하여 스트리밍 데이터를 처리하고 분석할 수 있습니다. 이 서비스를 사용하면 스트리밍 소스와 정적 소스를 대상으로 코드를 작성하고 실행하여 시계열 분석을 수행하고 실시간 대시보드와 지표에 데이터를 제공할 수 있습니다.
Apache Flink
Managed Service for Apache Flink는 Apache Flink 애플리케이션을 위한 기본 인프라를 제공합니다. 컴퓨팅 리소스 프로비저닝, AZ 장애 조치 복원력, 병렬 계산, 자동 규모 조정, 애플리케이션 백업(체크포인트 및 스냅샷으로 구현)과 같은 핵심 기능을 처리합니다. Flink 인프라를 직접 호스팅할 때 사용하는 것과 동일한 방식으로 고급 Flink 프로그래밍 기능(예: 연산자, 함수, 소스, 싱크)을 사용할 수 있습니다.
Managed Service for Apache Flink와 Managed Service for Apache Flink Studio 중 어떤 서비스를 사용할지 결정
Amazon Managed Service for Apache Flink에서 Flink 작업을 실행하는 데는 두 가지 옵션이 있습니다. Managed Service for Apache Flink를 사용하면 원하는 IDE에서 Java, Scala 또는 Python(및 임베딩된 SQL)으로 Flink 애플리케이션을 개발하고 Apache Flink Datastream 또는 Table API를 활용할 수 있습니다. Managed Service for Apache Flink Studio를 사용하면 실시간으로 데이터 스트림을 대화식으로 쿼리하고 표준 SQL, Python 및 Scala를 사용하여 스트림 처리 애플리케이션을 쉽게 빌드하고 실행할 수 있습니다.
사용 사례에 가장 적합한 방식을 선택할 수 있습니다. 확실하지 않으면 이 섹션에서 제공하는 전체적인 지침을 참조하세요.
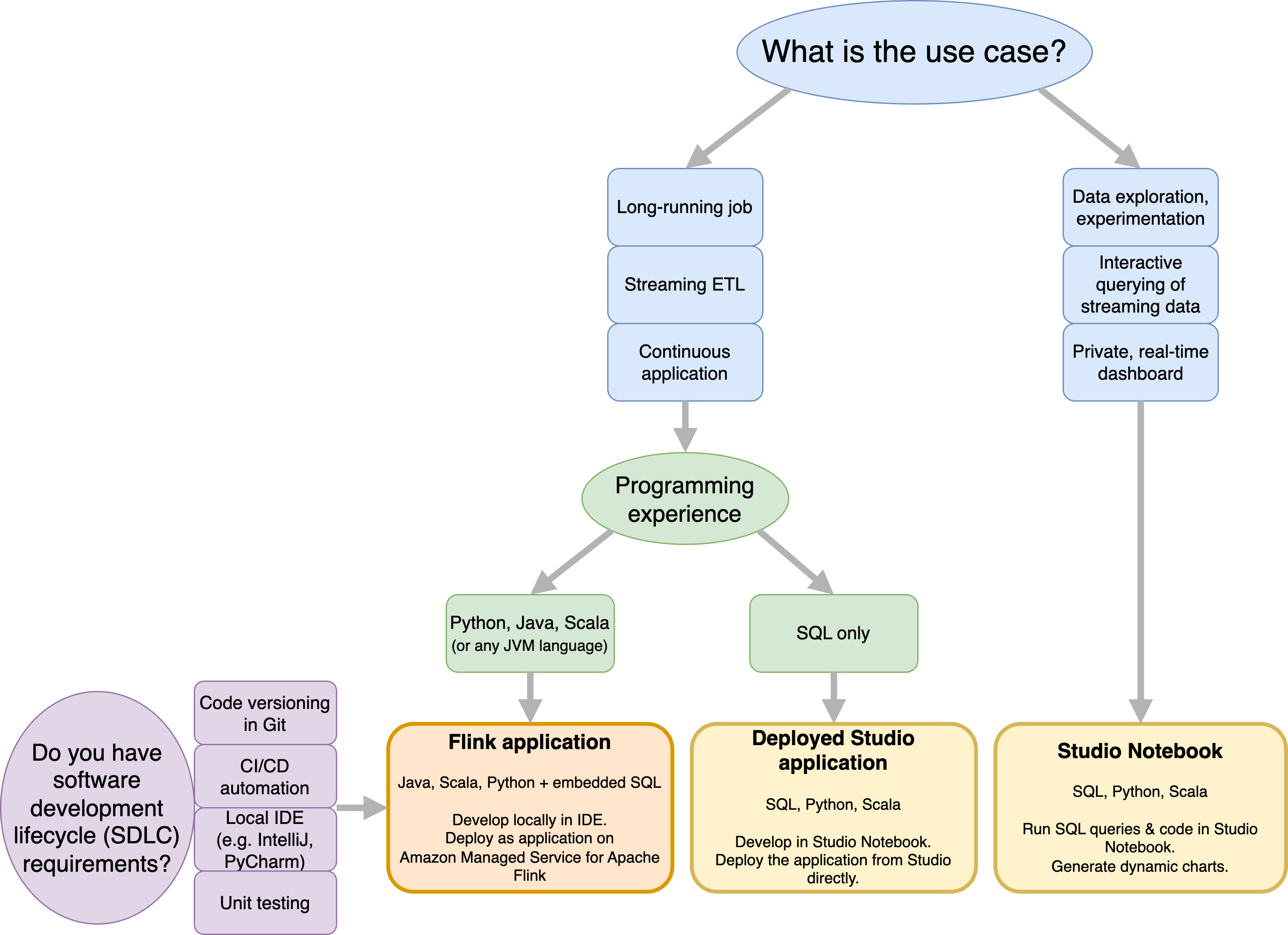
Amazon Managed Service for Apache Flink와 Amazon Managed Service for Apache Flink Studio 중 무엇을 사용할지 결정하기 전에 먼저 사용 사례를 고려해야 합니다.
스트리밍 ETL이나 지속적인 애플리케이션과 같은 워크로드를 수행할 장기 실행 애플리케이션을 운영할 계획이면 Managed Service for Apache Flink 사용을 고려해야 합니다. 그 이유는 사용자가 원하는 IDE에서 Flink API를 직접 사용해 Flink 애플리케이션을 생성할 수 있기 때문입니다. 또한 IDE를 사용하여 로컬에서 개발하면 소프트웨어 개발 수명 주기(SDLC)의 공통 프로세스와 Git 기반 코드 버전 관리, CI/CD 자동화 또는 유닛 테스트와 같은 도구를 활용할 수 있습니다.
애드혹 데이터 탐색에 관심이 있거나 스트리밍 데이터를 대화식으로 쿼리하고 싶거나 개인용 실시간 대시보드를 만들고 싶으면 Managed Service for Apache Flink Studio는 몇 번의 클릭만으로 이러한 목표를 달성하도록 도와줍니다. SQL에 익숙한 사용자는 Studio에서 바로 장기 실행 애플리케이션을 배포하는 것을 고려할 수 있습니다.
참고
Studio 노트북을 장기 실행 애플리케이션으로 전환할 수 있습니다. 그러나 Git 기반 코드 버전 관리나 CI/CD 자동화와 같은 SDLC 도구 또는 유닛 테스트와 같은 기법과 통합하려면 원하는 IDE를 사용하는 Managed Service for Apache Flink를 권장합니다.
Managed Service for Apache Flink에서 사용할 Apache Flink API 선택
선택한 IDE에서 Apache Flink API를 사용하여 Managed Service for Apache Flink에서 Java, Python 및 Scala를 사용하여 애플리케이션을 빌드할 수 있습니다. Flink Datastream 및 Table API를 사용해 애플리케이션을 빌드하는 방법에 대한 지침은 설명서에서 확인할 수 있습니다. 애플리케이션과 운영 요구 사항을 가장 잘 충족하도록 Flink 애플리케이션을 생성할 때 사용할 언어와 API를 선택할 수 있습니다. 확실하지 않으면 이 섹션에서 제공하는 전체적인 지침을 참조하세요.
Flink API 선택
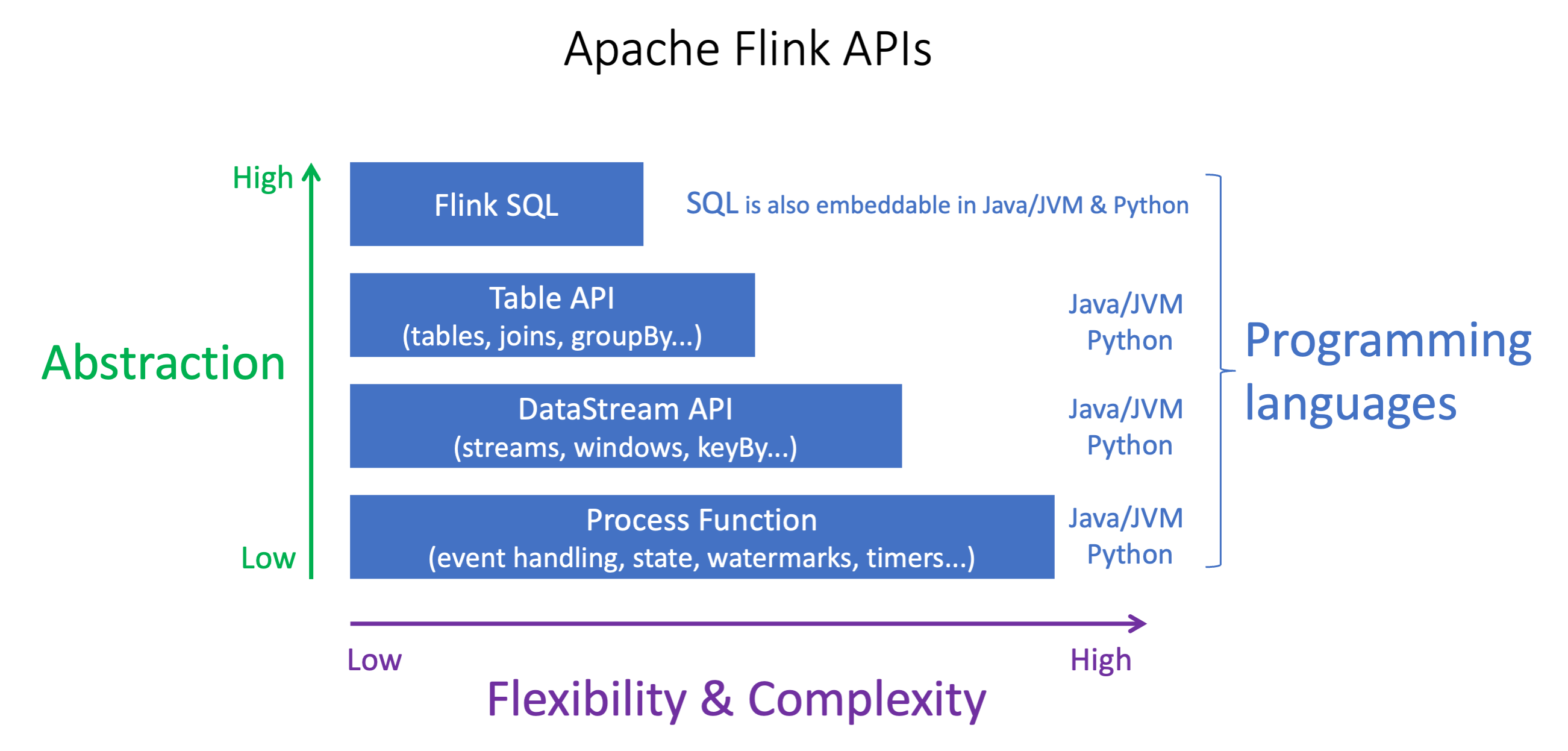
Apache Flink API는 추상화 수준이 서로 달라 애플리케이션을 어떻게 빌드할지 결정하는 데 영향을 줄 수 있습니다. 이 API들은 표현력이 뛰어나고 유연하며 함께 사용해 애플리케이션을 빌드할 수 있습니다. 하나의 Flink API만 사용할 필요는 없습니다. Flink API에 관한 자세한 내용은 Apache Flink 설명서
Flink는 Flink SQL, Table API, DataStream API 그리고 DataStream API와 함께 사용되는 Process Function 등 네 가지 수준의 API 추상화를 제공합니다. 이 모든 API는 Amazon Managed Service for Apache Flink에서 지원됩니다. 가능하면 더 높은 수준의 추상화부터 시작하는 것이 좋습니다. 그러나 일부 Flink 기능은 Java, Python 또는 Scala로 애플리케이션을 생성할 수 있는 Datastream API에서만 사용할 수 있습니다. 다음과 같은 요구 사항이 있으면 Datastream API 사용을 고려해야 합니다.
상태에 대한 세밀한 제어가 필요한 경우
외부 데이터베이스나 엔드포인트를 비동기적으로 직접적으로 호출해야 하는 경우(예: 추론 작업)
사용자 지정 타이머가 필요한 경우(예: 사용자 정의 윈도우 설정 또는 지연 이벤트 처리 구현)
-
상태를 초기화하지 않고 애플리케이션의 흐름을 변경하려는 경우
참고
DataStream API와 함께 사용할 언어 선택:
SQL은 선택한 프로그래밍 언어와 관계없이 모든 Flink 애플리케이션에 임베딩할 수 있습니다.
DataStream API를 사용할 계획이라면 Python에서는 모든 커넥터가 지원되지 않는다는 점을 고려해야 합니다.
낮은 지연 시간과 높은 처리량이 요구되면 API 종류와 관계없이 Java/Scala 사용을 고려해야 합니다.
Process Functions API에서 Async IO를 사용하려면 Java를 사용해야 합니다.
API 선택은 상태를 초기화하지 않고 애플리케이션 로직을 발전시킬 수 있는 능력에도 영향을 줄 수 있습니다. 이는 연산자에 UID를 설정하는 기능이라는 특정 기능에 따라 달라지며, 이 기능은 Java와 Python 모두 해당 DataStream API에서만 사용할 수 있습니다. 자세한 내용을 알아보려면 Apache Flink 설명서의 모든 연산자에 UUID 설정
스트리밍 데이터 애플리케이션 시작
스트리밍 데이터를 지속적으로 읽고 처리하는 Managed Service for Apache Flink 애플리케이션을 생성하는 것부터 시작할 수 있습니다. 그런 다음 선택한 IDE를 사용하여 코드를 작성하고 라이브 스트리밍 데이터로 테스트하십시오. Managed Service for Apache Flink가 결과를 전송하려는 대상을 구성할 수도 있습니다.
시작하려면 다음 섹션을 읽어보는 것이 좋습니다.
또는 Managed Service for Apache Flink Studio 노트북을 만들어 시작할 수도 있습니다. 이 노트북을 사용하면 실시간으로 데이터 스트림을 대화식으로 쿼리하고 표준 SQL, Python 및 Scala를 사용하여 스트림 처리 애플리케이션을 쉽게 빌드하고 실행할 수 있습니다. 에서 몇 번의 클릭만으로 서버리스 노트북을 시작하여 데이터 스트림을 쿼리하고 몇 초 만에 결과를 얻을 AWS Management Console수 있습니다. 시작하려면 다음 섹션을 읽어보는 것이 좋습니다.
