기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
고급 규칙 유형을 사용하여 규칙 기반 일치 워크플로 생성
사전 조건
규칙 기반 매칭 워크플로를 생성하기 전에 다음을 수행해야 합니다.
-
스키마 매핑을 생성합니다. 자세한 내용은 스키마 매핑 생성 단원을 참조하십시오.
-
Connect Customer Profiles를 출력 대상으로 사용하는 경우 적절한 권한이 구성되어 있는지 확인합니다.
다음 절차에서는 AWS Entity Resolution 콘솔 또는 CreateMatchingWorkflow API를 사용하여 고급 규칙 유형을 사용하여 규칙 기반 일치 워크플로를 생성하는 방법을 보여줍니다.
- Console
-
콘솔을 사용하여 고급 규칙 유형을 사용하여 규칙 기반 일치 워크플로를 생성하려면
-
에 로그인 AWS Management Console 하고 https://console.aws.amazon.com/entityresolution/
AWS Entity Resolution 콘솔을 엽니다. -
왼쪽 탐색 창의 워크플로에서 일치를 선택합니다.
-
매칭 워크플로 페이지의 오른쪽 상단 모서리에서 매칭 워크플로 생성을 선택합니다.
-
1단계: 일치하는 워크플로 세부 정보 지정에서 다음을 수행합니다.
-
일치하는 워크플로 이름과 선택적 설명을 입력합니다.
-
데이터 입력에서 , AWS 리전 AWS Glue 데이터베이스, AWS Glue 테이블, 해당 스키마 매핑을 차례로 선택합니다.
최대 19개의 데이터 입력을 추가할 수 있습니다.
참고
고급 규칙을 사용하려면 스키마 매핑이 다음 요구 사항을 충족해야 합니다.
-
필드가 함께 그룹화되지 않는 한 각 입력 필드는 고유한 일치 키에 매핑되어야 합니다.
-
입력 필드가 함께 그룹화된 경우 동일한 일치 키를 공유할 수 있습니다.
예를 들어 다음 스키마 매핑은 고급 규칙에 유효합니다.
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }이 경우
firstName및lastName필드가 함께 그룹화되고 허용되는 동일한 이름 일치 키가 공유됩니다.스키마 매핑을 검토하고 필드를 올바르게 그룹화하지 않는 한이 one-to-one 일치 규칙을 따르도록 업데이트하여 고급 규칙을 사용합니다.
-
데이터 테이블에 DELETE 열이 있는 경우 스키마 매핑의 유형은 여야 하며
String및matchKey를 가질 수 없습니다groupName.
-
-
데이터 정규화 옵션은 일치 전에 데이터 입력이 정규화되도록 기본적으로 선택됩니다. 데이터를 정규화하지 않으려면 데이터 정규화 옵션을 선택 취소합니다.
참고
정규화는 스키마 매핑 생성의 다음 시나리오에서만 지원됩니다.
-
이름 하위 유형이 그룹화된 경우: 이름, 중간 이름, 성.
-
주소 하위 유형이 그룹화된 경우: 거리 주소 1, 거리 주소 2, 거리 주소 3, 도시, 주, 국가, 우편 번호.
-
전화 번호, 전화 국가 코드 등의 전화 하위 유형이 그룹화된 경우.
-
-
서비스 액세스 권한을 지정하려면 옵션을 선택하고 권장 조치를 취합니다.
옵션 권장 조치 새 서비스 역할 생성 및 사용 -
AWS Entity Resolution 는이 테이블에 필요한 정책을 사용하여 서비스 역할을 생성합니다.
-
기본 서비스 역할 이름은
entityresolution-matching-workflow-<timestamp>입니다. -
역할을 생성하고 정책을 연결할 수 있는 권한이 있어야 합니다.
-
입력 데이터가 암호화된 경우 이 데이터는 KMS 키로 암호화됨 옵션을 선택한 다음 데이터 입력을 복호화하는 데 사용할 AWS KMS 키를 입력할 수 있습니다.
기존 서비스 역할 사용 -
드롭다운 목록에서 기존 서비스 역할 이름을 선택합니다.
역할을 나열할 권한이 있는 경우 역할 목록이 표시됩니다.
역할을 나열할 수 있는 권한이 없는 경우 사용하려는 역할의 Amazon 리소스 이름(ARN)을 입력할 수 있습니다.
기존 서비스 역할이 없는 경우 기존 서비스 역할 사용 옵션을 사용할 수 없습니다.
-
IAM에서 보기 외부 링크를 선택하여 서비스 역할을 확인합니다.
기본적으로 AWS Entity Resolution 는 필요한 권한을 추가하기 위해 기존 역할 정책을 업데이트하려고 시도하지 않습니다.
-
-
(선택 사항) 리소스에 대해 태그를 활성화하려면 새 태그 추가를 선택한 다음 키 및 값 페어를 입력합니다.
-
다음을 선택합니다.
-
-
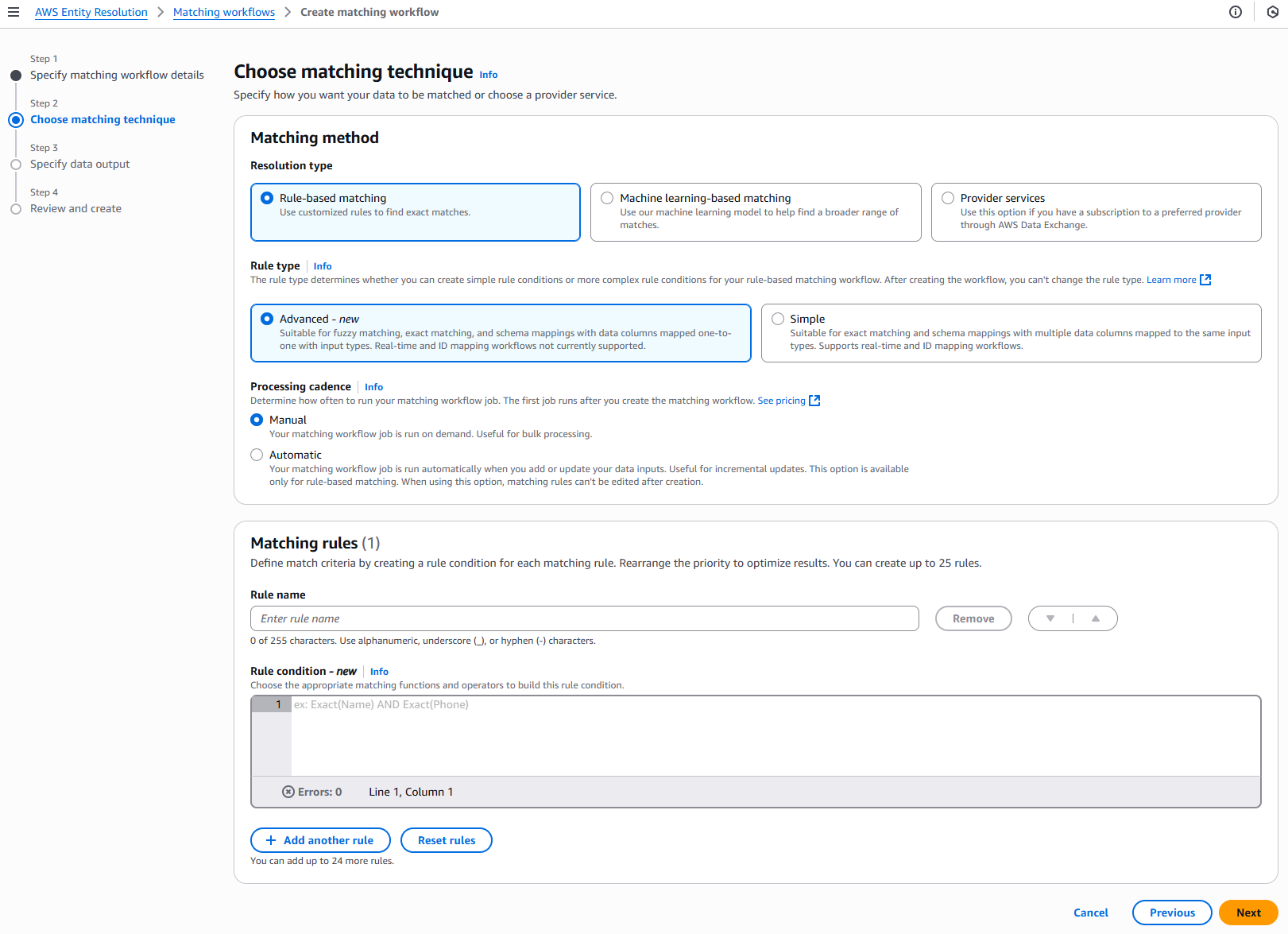
2단계: 매칭 기법 선택:
-
일치 방법에서 규칙 기반 일치를 선택합니다.
-
규칙 유형에서 고급을 선택합니다.
-
케이던스 처리에서 다음 옵션 중 하나를 선택합니다.
-
수동을 선택하여 대량 업데이트에 대해 온디맨드로 워크플로 실행
-
새 데이터가 S3 버킷에 저장되는 즉시 워크플로를 실행하려면 자동을 선택합니다.
참고
자동을 선택한 경우 S3 버킷에 대해 Amazon EventBridge 알림이 켜져 있는지 확인합니다. S3 콘솔을 사용하여 Amazon EventBridge를 활성화하는 방법에 대한 지침은 Amazon Amazon S3 사용 설명서의 Amazon EventBridge 활성화를 참조하세요.
-
-
일치 규칙의 경우 규칙 이름을 입력한 다음 목표에 따라 드롭다운 목록에서 적절한 일치 함수와 연산자를 선택하여 규칙 조건을 빌드합니다.
최대 25개의 규칙을 생성할 수 있습니다.
참고
AND 연산자를 사용하여 퍼지 일치 함수(Cosine, Levenshtein 또는 Soundex)를 정확한 일치 함수(Exact, ExactManyToMany)와 결합해야 합니다.
다음 표를 사용하여 목표에 따라 사용할 함수 또는 연산자 유형을 결정할 수 있습니다.
목표 권장 함수 또는 연산자 권장 선택적 한정자 장점 정확한 데이터의 동일한 문자열은 일치하지만 빈 값은 일치하지 않습니다. 정확한 조합 EmptyValues=프로세스 정확한 데이터에서 동일한 문자열을 일치시키고 빈 값은 무시합니다. Exact( matchKey)EmptyValues=무시 일치 키 간에 여러 레코드를 일치시킵니다. 유연한 페어링에 적합합니다. 제한: 일치 키 15개 ExactManyToMany( matchKey,matchKey, ...)해당 사항 없음 데이터의 수치 표현 간 유사성을 측정하지만 빈 값에서는 일치하지 않습니다. 텍스트, 숫자 또는 둘 다에 적합합니다. 코사인 EmptyValues=프로세스 간단하고 효율적입니다.
TF-IDF 가중치와 결합할 때 긴 텍스트에 적합합니다.
정확한 단어 기반 일치에 적합합니다.
데이터의 수치 표현 간 유사성을 측정하고 빈 값을 무시합니다. Cosine( matchKey,threshold, ...)EmptyValues=무시 오타, 철자 오류를 처리하고 트랜스포지션을 잘 수행합니다.
다양한 PII 유형에 효과적입니다.
짧은 문자열(예: 이름 또는 전화번호)에 적합합니다.
한 단어를 다른 단어로 변경하는 데 필요하지만 빈 값에서는 일치하지 않는 최소 변경 횟수를 계산합니다. 철자가 약간 다른 텍스트에 적합합니다. Levenshtein EmptyValues=프로세스 한 단어를 다른 단어로 변경하고 빈 값을 무시하는 데 필요한 최소 변경 횟수를 계산합니다. Levenshtein( matchKey,threshold, ...)EmptyValues=무시 텍스트 문자열의 사운드는 비슷하지만 빈 값에서는 일치하지 않는 정도에 따라 텍스트 문자열을 비교하고 일치시킵니다. 철자 또는 발음이 다른 텍스트에 적합합니다. Soundex EmptyValues=프로세스 음성 일치에 효과적이며 비슷한 사운드의 단어를 식별합니다.
빠르고 계산 비용이 저렴합니다.
발음은 비슷하지만 철자가 다른 이름을 일치시키는 데 적합합니다.
텍스트 문자열의 사운드가 얼마나 유사한지에 따라 텍스트 문자열을 비교 및 일치시키고 빈 값을 무시합니다. Soundex( matchKey)EmptyValues=무시 함수를 결합합니다. AND 해당 사항 없음 함수를 구분합니다. 또는 해당 사항 없음 조건을 그룹화하여 중첩 조건을 생성합니다. (…) 해당 사항 없음 예전화번호 및 이메일과 일치하는 규칙 조건
다음은 전화번호(전화 일치 키) 및 이메일 주소(이메일 주소 일치 키)의 레코드와 일치하는 규칙 조건의 예입니다.
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)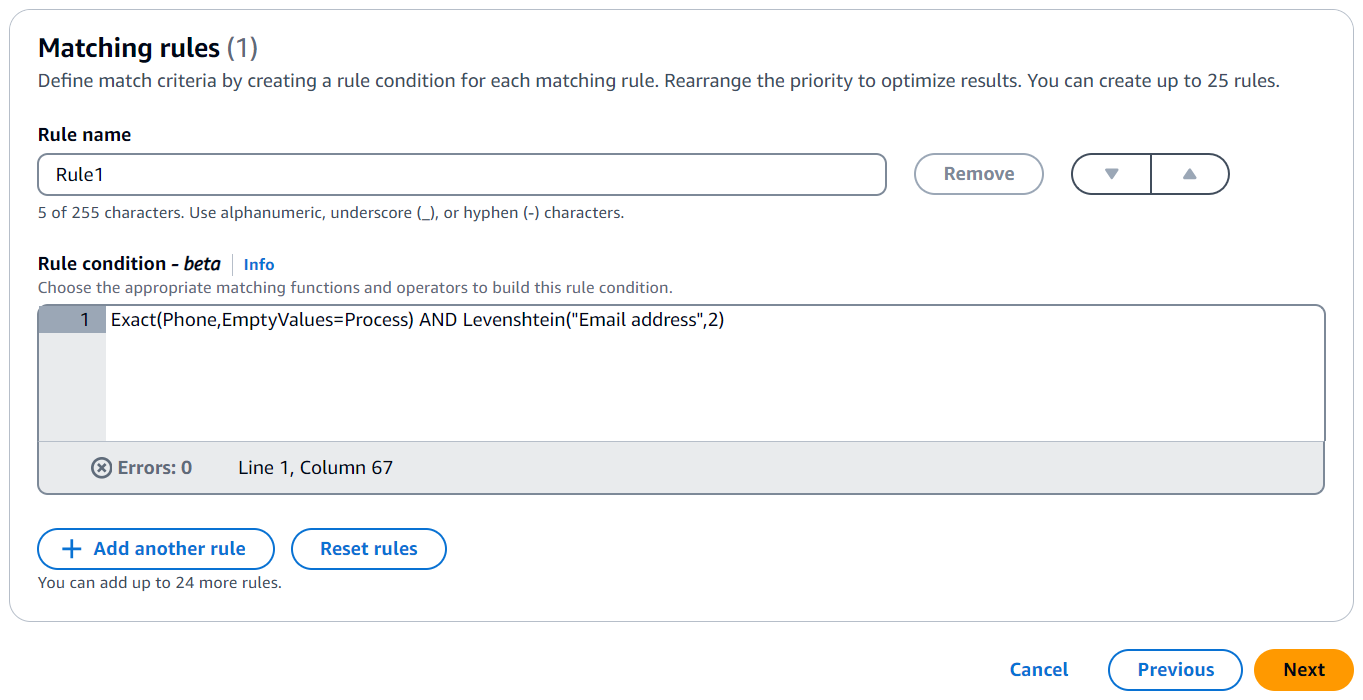
전화 일치 키는 정확한 일치 함수를 사용하여 동일한 문자열을 일치시킵니다. 전화 일치 키는 EmptyValues=Process modifier를 사용하여 일치하는 빈 값을 처리합니다.
이메일 주소 일치 키는 Levenshtein 일치 함수를 사용하여 기본 Levenshtein 거리 알고리즘 임계값인 2를 사용하여 데이터를 오타와 일치시킵니다. 이메일 일치 키는 선택적 한정자를 사용하지 않습니다.
AND 연산자는 정확한 일치 함수와 Levenshtein 일치 함수를 결합합니다.
예 ExactManyToMany를 사용하여 매치키 매칭을 수행하는 규칙 조건
다음은 세 개의 주소 필드(HomeAddress 일치 키, BillingAddress 일치 키 및 ShippingAddress 일치 키)의 레코드와 일치하는 규칙 조건의 예제로, 값이 동일한지 확인하여 잠재적 일치 항목을 찾습니다.
연
ExactManyToMany산자는 지정된 주소 필드의 가능한 모든 조합을 평가하여 둘 이상의 주소 간의 정확한 일치를 식별합니다. 예를 들어가BillingAddress또는와HomeAddress일치하는지ShippingAddress또는 세 주소가 모두 정확히 일치하는지 감지합니다.ExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)예클러스터링을 사용하는 규칙 조건
퍼지 조건을 사용한 고급 규칙 기반 일치에서 시스템은 먼저 정확한 일치를 기반으로 레코드를 클러스터로 그룹화합니다. 이러한 초기 클러스터가 구성되면 시스템은 퍼지 일치 필터를 적용하여 각 클러스터 내에서 추가 일치 항목을 식별합니다. 최적의 성능을 얻으려면 데이터 패턴을 기반으로 정확한 일치 조건을 선택하여 잘 정의된 초기 클러스터를 생성해야 합니다.
다음은 여러 정확한 일치를 퍼지 일치 요구 사항과 결합하는 규칙 조건의 예입니다. 연
AND산자를 사용하여FullName, 생년월일(DOB) 및Address의 세 필드가 레코드 간에 정확히 일치하는지 확인합니다. 또한 Levenshtein 거리를 사용하여InternalID필드를 약간 변경할 수 있습니다1. Levenshtein 거리는 한 문자열을 다른 문자열로 변경하는 데 필요한 단일 문자 편집의 최소 수를 측정합니다. 거리가 1이면 한 문자(예: 단일 오타, 삭제 또는 삽입)만InternalIDs다르게 일치합니다. 이러한 조건 조합은 식별자에 약간의 불일치가 있더라도 동일한 개체를 나타낼 가능성이 매우 높은 레코드를 식별하는 데 도움이 됩니다.Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
다음을 선택합니다.
-
-
3단계: 데이터 출력 및 형식 지정:
-
데이터 출력 대상 및 형식에서 데이터 출력의 Amazon S3 위치와 데이터 형식이 정규화된 데이터인지 원래 데이터인지 선택합니다.
-
암호화에 암호화 설정 사용자 지정을 선택한 경우 AWS KMS 키 ARN을 입력합니다.
-
시스템 생성 출력을 봅니다.
-
데이터 출력에서 포함하거나 숨기거나 마스킹할 필드를 결정한 다음 목표에 따라 권장 조치를 취합니다.
목표 권장 조치 필드 포함 출력 상태를 포함으로 유지합니다. 필드 숨기기(출력에서 제외) 출력 필드를 선택한 다음 숨기기를 선택합니다. 필드 마스킹 출력 필드를 선택한 다음 해시 출력을 선택합니다. 이전 설정 재설정 재설정을 선택합니다. -
다음을 선택합니다.
-
-
4단계: 검토 및 생성의 경우:
-
이전 단계에서 선택한 내용을 검토하고 필요한 경우 편집하세요.
-
[Create and run]을 선택합니다.
일치하는 워크플로가 생성되었고 작업이 시작되었음을 나타내는 메시지가 나타납니다.
-
-
일치하는 워크플로 세부 정보 페이지의 지표 탭에서 마지막 작업 지표에서 다음을 확인합니다.
-
작업 ID입니다.
-
일치하는 워크플로 작업의 상태: 대기 중, 진행 중, 완료됨, 실패
-
워크플로 작업에 대해 완료된 시간입니다.
-
처리된 레코드 수입니다.
-
처리되지 않은 레코드 수입니다.
-
생성된 고유 일치 IDs.
-
입력 레코드 수입니다.
작업 기록에서 이전에 실행된 일치하는 워크플로 작업에 대한 작업 지표를 볼 수도 있습니다.
-
-
일치하는 워크플로 작업이 완료된 후(상태가 완료됨) 데이터 출력 탭으로 이동한 다음 Amazon S3 위치를 선택하여 결과를 볼 수 있습니다.
-
(수동 처리 유형만 해당) 수동 처리 유형으로 규칙 기반 매칭 워크플로를 생성한 경우 매칭 워크플로 세부 정보 페이지에서 워크플로 실행을 선택하여 언제든지 매칭 워크플로를 실행할 수 있습니다.
-
(자동 처리 유형만 해당) 데이터 테이블에 DELETE 열이 있는 경우:
-
DELETE 열에서
true로 설정된 레코드는 삭제됩니다. -
DELETE 열에서
false로 설정된 레코드는 S3에 수집됩니다.
자세한 내용은 1단계: 자사 데이터 테이블 준비 단원을 참조하십시오.
-
-
- API
-
API를 사용하여 고급 규칙 유형으로 규칙 기반 일치 워크플로를 생성하려면
참고
기본적으로 워크플로는 표준(배치) 처리를 사용합니다. 증분(자동 처리를 사용하려면 명시적으로 구성해야 합니다.
-
터미널 또는 명령 프롬프트를 열어 API를 요청합니다.
-
다음 엔드포인트에 대한 POST 요청을 생성합니다.
/matchingworkflows -
요청 헤더에서 Content-type을 application/json으로 설정합니다.
참고
지원되는 프로그래밍 언어의 전체 목록은 AWS Entity Resolution API 참조를 참조하세요.
-
요청 본문에 대해 다음과 같은 필수 JSON 파라미터를 제공합니다.
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "string위치:
-
workflowName(필수) - 고유해야 하며 [a-zA-Z_0-9-]*와 일치하는 패턴은 1~255자여야 합니다. -
inputSourceConfig(필수) - 1~20개의 입력 소스 구성 목록 -
outputSourceConfig(필수) - 정확히 하나의 출력 소스 구성 -
resolutionTechniques(필수) - 규칙 기반 일치를 위한 resolutionType으로 "RULE_MATCHING"으로 설정합니다. -
roleArn(필수) - 워크플로 실행을 위한 IAM 역할 ARN -
ruleConditionProperties(필수) - 규칙 조건 목록과 일치하는 규칙의 이름입니다.
선택적 파라미터는 다음과 같습니다.
-
description- 최대 255자 -
incrementalRunConfig- 증분 실행 유형 구성 -
tags- 최대 200개의 키-값 페어
-
-
(선택 사항) 기본 표준(배치) 처리 대신 증분 처리를 사용하려면 요청 본문에 다음 파라미터를 추가합니다.
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
요청을 보냅니다.
-
성공하면 상태 코드 200과 다음을 포함하는 JSON 본문이 포함된 응답을 받게 됩니다.
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
호출에 실패하면 다음 오류 중 하나가 발생할 수 있습니다.
-
400 - 워크플로 이름이 이미 있는 경우 ConflictException
-
400 - 입력이 검증에 실패한 경우 ValidationException
-
402 - 계정 한도를 초과하는 경우 ExceedsLimitException
-
403 - 충분한 액세스 권한이 없는 경우 AccessDeniedException
-
429 - 요청이 제한된 경우 ThrottlingException
-
500 - 내부 서비스 장애가 있는 경우 InternalServerException
-
-
