기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Connect 고객 분석 데이터 레이크에서 데이터 예약
이 주제에서는 Connect Customer 데이터 레이크 예약 테이블의 내용을 자세히 설명합니다. 테이블에는 콘텐츠의 열, 유형 및 설명이 나열됩니다.
분석 데이터 레이크에 액세스하고 공유할 데이터를 구성하는 두 가지 방법이 있습니다.
옵션 1을 사용하여 예약 테이블에 액세스할 수 없는 경우 옵션 2를 사용해 보세요.
내용
직원 일정 프로필
테이블 이름: staff_scheduling_profile
복합 프라이머리 키:{instance_id, agent_arn,
staff_scheduling_profile_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| agent_arn | 문자열 | 에이전트의 ARN입니다. |
| staff_scheduling_profile_version | bigint | 직원 일정 프로필 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| staffing_group_arn | 문자열 | 에이전트가 할당된 인력 배치 그룹의 ARN입니다. |
| start_timestamp | 타임스탬프 | 직원 규칙에 구성된 에이전트의 StartTimestamp입니다(일정은 이 타임스탬프 이후에만 생성됨). |
| end_timestamp | 타임스탬프 | 직원 규칙에 구성된 에이전트의 EndTimestamp입니다(이 타임스탬프 이후에는 일정이 생성되지 않음). |
| shift_profile_arn | 문자열 | 직원 내 에이전트 규칙에 할당된 교대 근무 프로필의 ARN입니다. 교대 근무 교체 패턴에는 상호 배타적입니다. |
| 교대_회전_패턴_arn | 문자열 | 직원 내 에이전트 규칙에 할당된 교대 근무 교체 패턴의 ARN입니다. Shift Profile과 상호 배타적입니다. |
| shift_rotation_start_step_id | bigint | 에이전트가 할당된 교대 근무 교체 패턴에서 시작하는 단계 ID입니다. |
| timezone | 문자열 | 에이전트에 대해 구성된 시간대입니다. |
| is_deleted | 부울 | 에이전트가 삭제된 경우 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| last_updated_timestamp | 타임스탬프 | 직원 예약 프로필이 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
교대 근무 활동
테이블 이름: shift_activities
복합 프라이머리 키:{instance_id, shift_activity_arn,
shift_activity_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| shift_activity_arn | 문자열 | 교대 근무 활동의 ARN입니다. |
| shift_activity_version | bigint | 교대 근무 활동 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| shift_activity_name | 문자열 | 교대 근무 활동의 이름입니다. |
| type | 문자열 | 교대 근무 활동의 유형입니다. 가능한 값은 PRODUCTIVE, NON_PRODUCTIVE, LEAVE입니다. |
| sub_type | 문자열 | 교대 근무 활동의 하위 유형입니다. 이는 NON_PRODUCTIVE 유형 활동에만 유효합니다. 가능한 값은 BREAK_OR_MEAL과 NONE입니다. |
| is_adherence_tracked | 부울 | 교대 근무 활동이 준수 추적을 위해 구성된 경우 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| is_paid | 부울 | 교대 근무 활동이 유급으로 구성된 경우 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| is_deleted | 부울 | 교대 근무 활동이 삭제되면 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| last_updated_timestamp | 타임스탬프 | 교대 근무 활동이 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
교대 근무 프로필
테이블 이름: shift_profiles
복합 프라이머리 키:{instance_id, shift_profile_arn,
shift_profile_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| shift_profile_arn | 문자열 | 교대 근무 프로파일의 ARN입니다. |
| shift_profile_version | bigint | 교대 근무 프로필 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| shift_profile_name | 문자열 | 교대 근무 프로파일의 이름입니다. |
| is_deleted | 부울 | 교대 근무 프로파일이 삭제되면 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| last_updated_timestamp | 타임스탬프 | 교대 근무 프로파일이 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
인력 배치 그룹
테이블 이름: staffing_groups
복합 프라이머리 키:{instance_id, staffing_group_arn,
staffing_group_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| staffing_group_arn | 문자열 | 인력 배치 그룹의 ARN입니다. |
| staffing_group_version | bigint | 인력 배치 그룹 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| staffing_group_name | 문자열 | 인력 그룹의 이름입니다. |
| is_deleted | 부울 | 인력 배치 그룹이 삭제되면 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| last_updated_timestamp | 타임스탬프 | 인력 그룹이 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
인력 그룹 - 예측 그룹
테이블 이름: staffing_group_forecast_groups
복합 프라이머리 키:{instance_id, staffing_group_arn,
staffing_group_version, forecast_group_arn}
이 테이블은 staffing_group_arn 및 staffing_group_version의 staffing_groups 테이블과 조인하여 쿼리해야 합니다.
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| staffing_group_arn | 문자열 | 인력 배치 그룹의 ARN입니다. |
| staffing_group_version | bigint | 인력 배치 그룹 버전입니다. |
| forecast_group_arn | 문자열 | 인력 배치 그룹과 연결된 예측 그룹의 ARN입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| is_deleted | 부울 | StaffingGroup-ForecastGroup 연결이 유효한 경우 False로 설정합니다. |
| last_updated_timestamp | 타임스탬프 | 인력 그룹이 생성/업데이트된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
인력 그룹 - 감독자
테이블 이름: staffing_group_supervisors
복합 프라이머리 키:{instance_id, staffing_group_arn,
staffing_group_version, supervisor_arn}
이 테이블은 staffing_group_arn 및 staffing_group_version의 staffing_groups 테이블과 조인하여 쿼리해야 합니다.
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| staffing_group_arn | 문자열 | 인력 배치 그룹의 ARN입니다. |
| staffing_group_version | bigint | 인력 배치 그룹 버전입니다. |
| supervisor_arn | 문자열 | 인력 그룹과 연결된 감독자의 에이전트 ARN입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| is_deleted | 부울 | StaffingGroup-ForecastGroup 연결이 유효한 경우 False로 설정합니다. |
| last_updated_timestamp | 타임스탬프 | 인력 그룹이 생성/업데이트된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 교대 근무
테이블 이름: staff_shifts
복합 프라이머리 키:{instance_id, shift_id, shift_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| shift_id | 문자열 | 교대 근무의 ID입니다. |
| shift_version | bigint | 교대 근무 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| agent_arn | 문자열 | 에이전트의 ARN입니다. |
| shift_start_timestamp | 타임스탬프 | 교대 근무 시작 시 타임스탬프입니다. |
| shift_end_timestamp | 타임스탬프 | 교대 근무가 종료 시 타임스탬프입니다. |
| created_timestamp | 타임스탬프 | 교대 근무가 생성될 때의 타임스탬프입니다. |
| is_deleted | 부울 | 교대 근무가 삭제되면 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| last_updated_timestamp | 타임스탬프 | 교대 근무가 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 교대 근무 활동
테이블 이름: staff_shift_activities
복합 프라이머리 키:{instance_id, shift_id, shift_version,
activity_id}
이 테이블은 shift_id 및 shift_version의 staff_shifts 테이블과 조인하여 쿼리해야 합니다.
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| shift_id | 문자열 | 교대 근무의 ID입니다. |
| shift_version | bigint | 교대 근무 버전입니다. |
| activity_id | 문자열 | 활동의 ID입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| activity_start_timestamp | 타임스탬프 | 활동이 시작될 때의 타임스탬프입니다. |
| activity_end_timestamp | 타임스탬프 | 활동이 종료될 때의 타임스탬프입니다. |
| shift_activity_arn | 문자열 | 교대 근무 활동의 ARN입니다. shift_activity_arn이 null이면 '작업' 활동을 나타냅니다. |
| activity_status | 문자열 | 활동 상태입니다. 활동이 휴가와 겹치는 경우 비활성으로 설정됩니다. |
| is_overtime | 부울 | 활동이 초과 근무의 일부인 경우 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| is_deleted | 부울 | 교대 근무 활동이 유효하면 False로 설정합니다. |
| last_updated_timestamp | 타임스탬프 | 교대 근무가 생성/업데이트된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 잔여 휴가 변경
테이블 이름: staff_timeoff_balance_changes
복합 프라이머리 키:{instance_id, agent_arn, shift_activity_arn,
timeoff_balance_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| account_id | 문자열 | AWS 계정의 ID입니다. |
| agent_arn | 문자열 | 에이전트의 ARN입니다. |
| shift_activity_arn | 문자열 | 이 잔여 휴가가 할당된 교대 근무 활동의 ARN입니다. |
| timeoff_balance_version | bigint | 잔여 휴가 버전은 변경 순서를 나타내는 증분 숫자입니다. |
| balance_update_소스 | 문자열 | 잔액 업데이트의 소스입니다. 가능한 값은 TIME_OFF_BALANCE_UPLOAD, CONNECT_TIME_OFF_REQUEST, SCHEDULE_PUBLISH, CSV_TIME_OFF_BALANCE_DELETION, TIME_OFF_BALANCE_BACKFILL, SYSTEM_UPDATE입니다. |
| timeoff_id | 문자열 | 이 잔여 휴가가 있는 경우 이 잔여 휴가를 변경한 휴가의 ID입니다. |
| last_updated_by | 문자열 | 이 잔여 휴가를 유발한 에이전트의 ARN이 있는 경우 변경됩니다. |
| balance_change_in_hours | double | 이 시간 변경을 통해 업데이트된 잔여 휴가 금액입니다. 이 값이 양수이면 이 변경으로 잔여 휴가가 누적됩니다. 이 값이 음수이면 이 변경으로 잔여 휴가가 공제됩니다. 이 값은 밸런스 업로드 및 삭제 이벤트에 대해 정의되지 않습니다. |
| remaining_balance_in_hours | double | 이 변경 이벤트 후 남은 잔여 휴가 시간입니다. 이 값은 잔여 휴가 삭제 이벤트에 대해 정의되지 않습니다. |
| last_created_timestamp | 타임스탬프 | 잔여 휴가 변경 레코드가 생성된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 휴가
테이블 이름: staff_timeoffs
복합 프라이머리 키:{instance_id, timeoff_id, agent_arn,
timeoff_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| timeoff_id | 문자열 | 휴가의 ID입니다. |
| agent_arn | 문자열 | 에이전트의 ARN입니다. |
| timeoff_version | bigint | 휴가의 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| timeoff_type | 문자열 | 휴가의 유형입니다. 가능한 값은 TIME_OFF 및 VOLUNTARY_TIME_OFF입니다. |
| timeoff_start_timestamp | 타임스탬프 | 휴가가 시작될 때의 타임스탬프입니다. |
| timeoff_end_timestamp | 타임스탬프 | 휴가가 종료될 때의 타임스탬프입니다. |
| timeoff_status | 문자열 | 휴가 상태입니다. 가능한 값은 PENDING_CREATE, PENDING_UPDATE, PENDING_CANCEL, PENDING_ACCEPT, PENDING_APPROVE, PENDING_DECLINE, APPROVED, ACCEPTED, REJECTED, CANCELLED, WAITING_ACCEPT, WAITING_APPROVE입니다. 대기 중 상태는 휴가가 사용자 작업을 기다리고 있음을 나타냅니다. 대기 중 상태는 휴가가 사용자 작업의 시스템 처리를 기다리고 있음을 나타냅니다. |
| shift_activity_arn | 문자열 | 휴가에 사용되는 교대 근무 활동의 ARN입니다. |
| effective_timeoff_hours | double | 총 유효 휴가 시간입니다. 유효 휴가 시간은 휴가 공제 로직을 기반으로 계산됩니다. 이는 TIME_OFF 유형에 대해서만 설정됩니다. |
| last_updated_timestamp | 타임스탬프 | 휴가가 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 휴가 간격
테이블 이름: staff_timeoff_intervals
복합 프라이머리 키:{instance_id, timeoff_id, timeoff_version,
interval_id}
이 테이블은 timeoff_id 및 timeoff_version의 staff_timeoffs 테이블과 조인하여 쿼리해야 합니다.
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| timeoff_id | 문자열 | 휴가의 ID입니다. |
| timeoff_version | bigint | 휴가의 버전입니다. |
| interval_id | 문자열 | 휴가 간격의 ID입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| timeoff_interval_start_timestamp | 타임스탬프 | 휴가의 특정 간격이 시작될 때의 타임스탬프입니다. |
| timeoff_interval_end_timestamp | 타임스탬프 | 휴가의 특정 간격이 끝날 때의 타임스탬프입니다. |
| interval_effective_timeoff_hours | double | 이 특정 휴가 간격의 유효 휴가 시간입니다. 유효 휴가 시간은 휴가 공제 로직을 기반으로 계산됩니다. |
| last_updated_timestamp | 타임스탬프 | 휴가가 생성/업데이트/삭제된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 수요 그룹
테이블 이름: staff_demand_group
복합 프라이머리 키:{instance_id, agent_arn, demand_group_arn, staff_demand_group_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| agent_arn | 문자열 | 에이전트의 ARN입니다. |
| demand_group_arn | 문자열 | 수요 그룹의 ARN입니다. |
| staff_demand_group_version | Long | 이 에이전트가 그룹 연결을 요구하기 위한 버전 |
| priority | 문자열 | 이 에이전트에 대한 수요 그룹의 우선 순위입니다. LOW, MEDIUM 또는 HIGH일 수 있습니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| is_override | 부울 | 에이전트-디맨드 그룹 연결이 에이전트 수준 재정의인 경우 'true'로 설정합니다. |
| is_deleted | 부울 | 에이전트와 수요 그룹 연결이 삭제되면 true로 설정합니다. |
| last_updated_timestamp | 타임스탬프 | 에이전트-수요 그룹 연결이 생성/업데이트된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
인력 배치 그룹 수요 그룹
테이블 이름: staffing_group_demand_group
복합 프라이머리 키:{instance_id, staffing_group_arn, demand_group_arn,
staffing_group_demand_group_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| staffing_group_arn | 문자열 | 인력 배치 그룹의 ARN입니다. |
| demand_group_arn | 문자열 | 수요 그룹의 ARN입니다. |
| 인력 배치_group_demand_group_version | Long | 이 인력 배치 그룹과 Demand 그룹 연결의 버전 |
| priority | 문자열 | 이 인력 배치 그룹에 대한 수요 그룹의 우선 순위입니다. LOW, MEDIUM 또는 HIGH일 수 있습니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| is_deleted | 부울 | 수요 그룹 연결에 대한 인력 배치 그룹이 삭제되면 true로 설정합니다. |
| last_updated_timestamp | 타임스탬프 | 인력 배치 그룹의 수요 그룹 연결이 created/updated/deleted 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
직원 교대 근무 활동 할당
테이블 이름: staff_shift_activity_allocations
복합 프라이머리 키:{instance_id, shift_id, shift_version, activity_id, demand_group_arn}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| shift_id | 문자열 | 교대 근무의 ID입니다. |
| shift_version | Long | 교대 근무 버전입니다. |
| activity_id | 문자열 | 활동의 ID입니다. |
| demand_group_arn | 문자열 | 수요 그룹의 ARN입니다. |
| foecast_group_arn | 문자열 | 예측 그룹의 ARN입니다. |
| 할당_백분율 | double | Demand Group에 대한 활동 할당 비율입니다. |
| is_deleted | 부울 | StaffingGroup-ForecastGroupassociation이 유효한 경우 False로 설정합니다. |
| last_updated_timestamp | 타임스탬프 | 인력 그룹이 생성/업데이트된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
스케줄 지표
테이블 이름: schedule_metrics
복합 프라이머리 키:{instance_id, metric_id, interval_start_timestamp}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Amazon Connect 인스턴스의 ARN입니다. |
| instance_arn | 문자열 | Amazon Connect 인스턴스의 ID입니다. |
| metric_id | 문자열 | 지표 값의 고유 식별자 |
| aws_account_id | 문자열 | AWS 계정의 ID입니다. |
| entity_type | 문자열 | 지표가 예측 그룹 또는 수요 그룹에 대한 지표인지 여부를 나타냅니다. |
| entity_arn | 문자열 | 예측 그룹 또는 수요 그룹의 Arn |
| 채널 | 문자열 | 음성, 채팅과 같은 미디어 채널을 나타냅니다. 행에 채널 수준이 아닌 지표가 포함된 경우 모두로 채워집니다. |
| interval_start_timestamp | timestamp | 간격의 시작을 나타내는 타임스탬프 |
| required_agent_count | 실수 | 예상 에이전트 수를 나타냅니다. |
| 예약된_에이전트_수 | 실수 | 일정 에이전트 수를 나타냅니다. |
| scheduled_occupancy | 실수 | 점유율을 나타냅니다. |
| 예약_서비스_레벨_백분율 | 실수 | 일정 서비스 수준 백분율을 나타냅니다. |
| service_level_초 | 정수 | 서비스 수준 초를 나타냅니다. |
| 예약된_평균_응답 속도 | 실수 | 평균 응답 속도를 나타냅니다. |
| is_deleted | 부울 | 지표 삭제 여부를 나타냅니다. |
| last_updated_timestamp | timestamp | 지표 레코드가 생성된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | timestamp | 타임스탬프 - 데이터 레이크가 레코드를 마지막으로 처리한 시간을 표시합니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
목표 예약
테이블 이름: schedule_goals
복합 프라이머리 키:{instance_id, goal_id}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Amazon Connect 인스턴스의 ARN입니다. |
| instance_arn | 문자열 | Amazon Connect 인스턴스의 ID입니다. |
| goal_id | 문자열 | 목표 값의 고유 식별자 |
| aws_account_id | 문자열 | AWS 계정의 ID입니다. |
| entity_type | 문자열 | 목표가 예측 그룹인지 수요 그룹인지 나타냅니다. |
| entity_arn | 문자열 | 예측 그룹 또는 수요 그룹의 Arn |
| 채널 | 문자열 | 음성, 채팅과 같은 미디어 채널을 나타냅니다. |
| start_date_timestamp | timestamp | 목표의 시작을 나타내는 타임스탬프 |
| end_date_timestamp | timestamp | 목표의 끝을 나타내는 타임스탬프 |
| goal_service_level_percentage | 실수 | 목표 서비스 수준 백분율을 나타냅니다. |
| goal_service_level_seconds | 정수 | 서비스 수준 초를 나타냅니다. |
| goal_average_speed_of_answer | 실수 | 평균 응답 속도를 나타냅니다. |
| is_deleted | 부울 | 목표 삭제 여부를 나타냅니다. |
| last_updated_timestamp | timestamp | 목표 레코드가 생성된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | timestamp | 타임스탬프 - 데이터 레이크가 레코드를 마지막으로 처리한 시간을 표시합니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
교대 근무 교체 패턴
테이블 이름: shift_rotation_patterns
복합 프라이머리 키:{instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version}
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| 교대_회전_패턴_arn | 문자열 | 교대 근무 교체 패턴의 ARN입니다. |
| 교대_회전_패턴_버전 | bigint | 교대 근무 교체 패턴 버전입니다. |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| shift_rotation_패턴_이름 | 문자열 | 교대 근무 교체 패턴의 이름입니다. |
| start_date | 문자열 | yyyy-mm-dd 형식으로 된 교대 근무 교체 패턴의 시작 날짜입니다. |
| is_deleted | 부울 | 교대 근무 교체 패턴이 삭제되면 True로 설정합니다. 그렇지 않으면 False로 설정됩니다. |
| last_updated_by | 문자열 | 교대 근무 교체 패턴을 created/updated/deleted 사용자의 ARN입니다. |
| last_updated_timestamp | 타임스탬프 | 교대 근무 교체 패턴이 created/updated/deleted 때의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
교대 근무 교체 단계
테이블 이름: shift_rotation_steps
복합 프라이머리 키:{instance_id, shift_rotation_pattern_arn,
shift_rotation_pattern_version, step_id}
이 테이블은 shift_rotation_pattern_arn 및 shift_rotation_pattern_version의 shift_rotation_patterns 테이블과 조인하여 쿼리해야 합니다.
| 열 | 유형 | 설명 |
|---|---|---|
| instance-id | 문자열 | Connect Customer 인스턴스의 ID입니다. |
| 교대_회전_패턴_arn | 문자열 | 교대 근무 교체 패턴의 ARN입니다. |
| 교대_회전_패턴_버전 | bigint | 교대 근무 교체 패턴 버전입니다. |
| step_id | bigint | 교대 근무 교체 패턴 내 단계의 ID입니다. 단계는 순차적으로 번호가 매겨집니다(1, 2, 3, ... 최대 52). |
| instance_arn | 문자열 | Connect Customer 인스턴스의 ARN입니다. |
| shift_profile_arn | 문자열 | 교체 단계와 연결된 Shift Profile의 ARN입니다. |
| duration | bigint | 교체 단계의 주 단위 지속 시간입니다. |
| is_deleted | 부울 | 교대 근무 교체 단계가 유효하면 False로 설정합니다. |
| last_updated_by | 문자열 | 교대 근무 교체 패턴을 생성/업데이트한 사용자의 ARN입니다. |
| last_updated_timestamp | 타임스탬프 | 교대 근무 교체 패턴이 생성/업데이트된 시점의 타임스탬프입니다. |
| data_lake_last_processed_timestamp | 타임스탬프 | 레코드가 데이터 레이크와 마지막으로 접촉한 시간을 보여 주는 타임스탬프입니다. 여기에는 변환 및 채우기가 포함될 수 있습니다. 이 필드는 데이터 신선도를 안정적으로 결정하는 데 사용할 수 없습니다. |
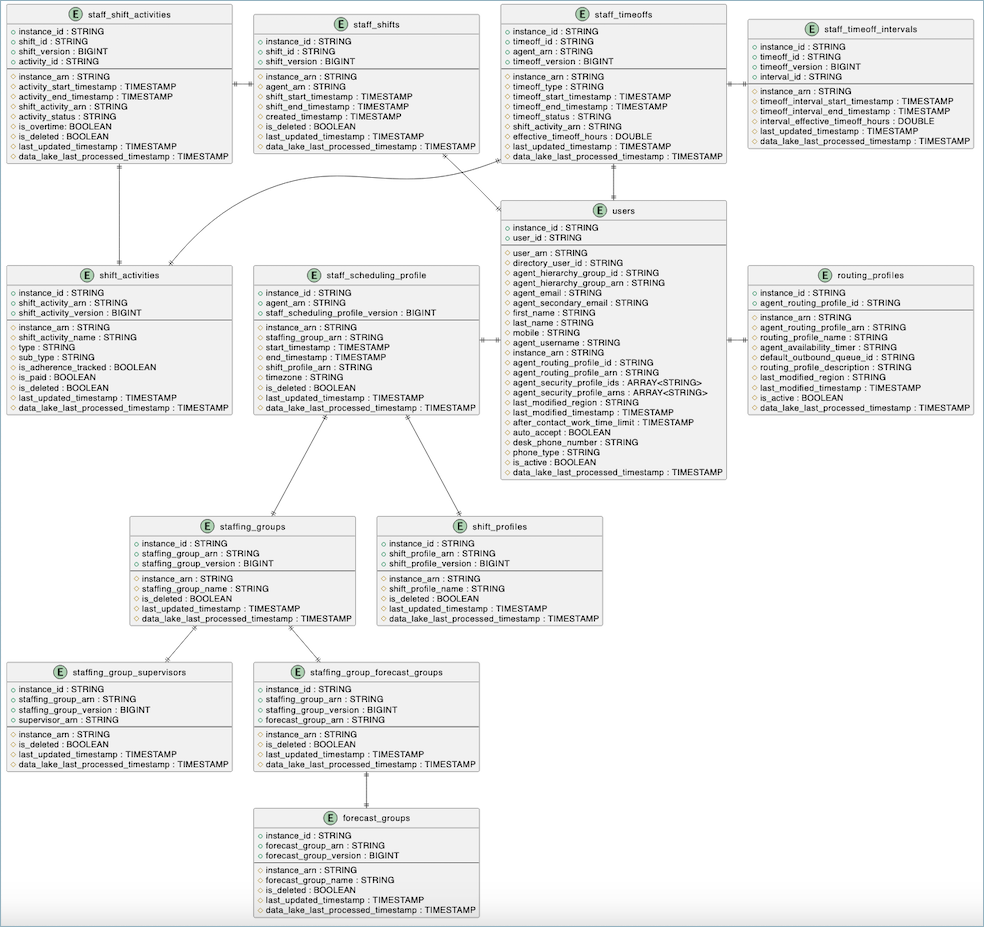
데이터 스키마
다음은 Connect Customer 데이터 레이크에서 테이블 예약 간의 구조와 관계를 보여주는 엔터티 관계 다이어그램입니다.
각 테이블에는 프라이머리 키와 속성이 데이터 유형과 함께 표시됩니다. 다이어그램은 이러한 테이블이 외래 키 관계를 통해 서로 어떻게 연관되는지 보여 주며, 예약 데이터 모델에 대한 포괄적인 보기를 제공합니다.
샘플 쿼리
1. 쿼리를 통해 특정 예측 그룹에서 작업하는 에이전트의 모든 예약된 교대 근무 활동 가져오기
SELECT * FROM agent_scheduled_shift_activities_view
where forecast_group_name = 'AnyDepartmentForecastGroup'
다음 단계를 완료하여 위에서 언급한 agent_scheduled_shift_activities_view를 생성합니다.
1단계: 감독자 이름을 가져올 뷰 생성
CREATE OR REPLACE VIEW "latest_supervisor_names_view" AS SELECT staffing_group_arn , array_agg(supervisor_name ORDER BY supervisor_name ASC) supervisor_names FROM ( SELECT s.staffing_group_arn , CONCAT(u.first_name, ' ', u.last_name) supervisor_name FROM (( SELECT staffing_group_arn , supervisor_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_supervisors WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) s INNER JOIN USERS u ON (s.supervisor_arn = u.user_arn)) ) GROUP BY staffing_group_arn
2단계: 에이전트와 연결된 인력 배치 그룹 및 예측 그룹을 가져오는 뷰 생성
CREATE OR REPLACE VIEW "latest_agent_staffing_group_forecast_group_view" AS WITH latest_staff_scheduling_profile AS ( SELECT agent_arn , staffing_group_arn , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY agent_arn ORDER BY staff_scheduling_profile_version DESC) recency FROM staff_scheduling_profile WHERE ((instance_id = 'YourAmazonConnectInstanceId') AND (is_deleted = false)) ) t WHERE (recency = 1) ) , latest_staffing_groups AS ( SELECT staffing_group_name , staffing_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_forecast_groups AS ( SELECT forecast_group_arn , forecast_group_name FROM ( SELECT * , RANK() OVER (PARTITION BY forecast_group_arn ORDER BY forecast_group_version DESC) recency FROM forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) , latest_staffing_group_forecast_groups AS ( SELECT staffing_group_arn , forecast_group_arn FROM ( SELECT * , RANK() OVER (PARTITION BY staffing_group_arn ORDER BY staffing_group_version DESC) recency FROM staffing_group_forecast_groups WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1) ) SELECT ssp.agent_arn , U.agent_username AS username , U.agent_routing_profile_id AS routing_profile_id , CONCAT(u.first_name, ' ', u.last_name) agent_name , fg.forecast_group_arn , fg.forecast_group_name , sg.staffing_group_arn , sg.staffing_group_name FROM latest_staff_scheduling_profile ssp INNER JOIN latest_staffing_groups sg ON ssp.staffing_group_arn = sg.staffing_group_arn INNER JOIN latest_staffing_group_forecast_groups sgfg ON ssp.staffing_group_arn = sgfg.staffing_group_arn INNER JOIN latest_forecast_groups fg ON fg.forecast_group_arn = sgfg.forecast_group_arn INNER JOIN USERS u ON ssp.agent_arn = u.user_arn
3단계: 최신 교대 근무 활동 가져오기
CREATE OR REPLACE VIEW "latest_shift_activities_view" AS SELECT shift_activity_arn , shift_activity_name , shift_activity_version , type , sub_type , is_adherence_tracked , is_paid , last_updated_timestamp FROM ( SELECT * , RANK() OVER (PARTITION BY shift_activity_arn ORDER BY shift_activity_version DESC) recency FROM shift_activities WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE (recency = 1)
4단계: 에이전트가 교대 근무 활동을 예약하도록 뷰 생성
CREATE OR REPLACE VIEW "agent_scheduled_shift_activities_view" AS WITH latest_staff_shifts AS ( SELECT agent_arn , shift_id , shift_version , shift_start_timestamp , shift_end_timestamp , created_timestamp , last_updated_timestamp , data_lake_last_processed_timestamp , recency FROM ( SELECT RANK() OVER (PARTITION BY shift_id ORDER BY shift_version DESC) recency , * FROM staff_shifts sa WHERE (instance_id = 'YourAmazonConnectInstanceId') ) t WHERE ((recency = 1) AND (is_deleted = false)) ) SELECT asgfg.forecast_group_name , array_join(sn.supervisor_names, ',') supervisor_names , s.agent_arn , u.first_name , u.last_name , asgfg.staffing_group_name , ssa.activity_id , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.shift_activity_name, 'Work') ELSE sa.shift_activity_name END) shift_activity_name , s.shift_start_timestamp , s.shift_end_timestamp , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.type, 'PRODUCTIVE') ELSE sa.type END) type , (CASE WHEN (ssa.shift_activity_arn IS NULL) THEN COALESCE(sa.is_paid, true) ELSE sa.is_paid END) is_paid , ssa.activity_start_timestamp , ssa.activity_end_timestamp , ssa.last_updated_timestamp , ssa.data_lake_last_processed_timestamp , u.agent_username as username , u.agent_routing_profile_id as routing_profile_id FROM staff_shift_activities ssa INNER JOIN latest_staff_shifts s ON s.shift_id = ssa.shift_id AND s.shift_version = ssa.shift_version INNER JOIN USERS u ON s.agent_arn = u.user_arn INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON s.agent_arn = asgfg.agent_arn LEFT JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = ssa.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn WHERE (ssa.is_deleted = false) AND (COALESCE(ssa.activity_status, ' ') <> 'INACTIVE') AND (ssa.instance_id = 'YourAmazonConnectInstanceId')
2. 쿼리를 통해 특정 예측 그룹에 있는 에이전트의 모든 휴가 요청 가져오기
SELECT * FROM agent_timeoff_report_view where forecast_group_name =
'AnyDepartmentForecastGroup'
다음 쿼리를 사용하여 위에서 언급한 agent_timeoff_report_view를 생성합니다.
CREATE OR REPLACE VIEW "agent_timeoff_report_view" AS WITH latest_staff_timeoffs AS ( SELECT t1.*, CAST((t1.effective_timeoff_hours * 60) AS INT) total_effective_timeoff_minutes FROM ( SELECT RANK() OVER ( PARTITION BY timeoff_id ORDER BY timeoff_version DESC ) recency, agent_arn, timeoff_id, shift_activity_arn, timeoff_status, timeoff_version, effective_timeoff_hours, timeoff_start_timestamp, timeoff_end_timestamp, last_updated_timestamp, data_lake_last_processed_timestamp FROM staff_timeoffs WHERE ( instance_id = 'YourAmazonConnectInstanceId' ) ) t1 WHERE (recency = 1) ) SELECT asgfg.forecast_group_name, to.agent_arn, asgfg.agent_name, asgfg.staffing_group_name, asgfg.username, sa.shift_activity_name, to.timeoff_start_timestamp, to.timeoff_end_timestamp, to.timeoff_status, array_join(sn.supervisor_names, ',') AS supervisor_names, sa.is_paid, to.last_updated_timestamp, to.data_lake_last_processed_timestamp, u.agent_routing_profile_id AS routing_profile_id, to.timeoff_id, to.shift_activity_arn, to.total_effective_timeoff_minutes FROM latest_staff_timeoffs to INNER JOIN latest_agent_staffing_group_forecast_group_view asgfg ON asgfg.agent_arn = to.agent_arn INNER JOIN latest_shift_activities_view sa ON sa.shift_activity_arn = to.shift_activity_arn INNER JOIN latest_supervisor_names_view sn ON sn.staffing_group_arn = asgfg.staffing_group_arn INNER JOIN users u ON u.user_arn = to.agent_arn
