기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Braket Hybrid Jobs 작업
Amazon Braket Hybrid Jobs는 클래식 AWS 리소스와 양자 처리 장치(QPUs)가 모두 필요한 하이브리드 양자 클래식 알고리즘을 실행할 수 있는 방법을 제공합니다. 하이브리드 작업은 요청된 고전적 리소스를 구동하고 알고리즘을 실행하며 완료 후 인스턴스를 해제하도록 설계되었으므로 사용한 만큼만 비용을 지불하면 됩니다.
하이브리드 작업은 고전 컴퓨팅 리소스와 양자 컴퓨팅 리소스를 모두 사용하는 장기 실행 반복 알고리즘에 적합합니다. 하이브리드 작업에서는 실행할 알고리즘을 제출하고 나면, Braket이 확장 가능하고 컨테이너화된 환경에서 해당 알고리즘을 실행합니다. 알고리즘이 완료되면 결과를 검색할 수 있습니다.
또한 하이브리드 작업에서 생성된 양자 작업은 대상 QPU 디바이스에 대한 대기열에서 더 높은 우선순위로 지정되는 이점을 누릴 수 있습니다. 이러한 우선순위 지정 덕분에 대기열에 있는 다른 작업들보다 양자 계산이 먼저 처리되고 실행됩니다. 이는 하나의 양자 작업의 결과가 이전 양자 작업의 결과에 따라 달라지는 반복 하이브리드 알고리즘에 특히 유용합니다. 이러한 알고리즘의 예로는 양자 근사 최적화 알고리즘(Quantum Approximate Optimization Algorithm, QAOA)
다음을 사용하여 Braket에서 하이브리드 작업에 액세스할 수 있습니다.
-
Amazon Braket API
이 섹션의 내용:
Amazon Braket Hybrid Jobs를 사용해야 하는 시점
Amazon Braket Hybrid Jobs를 사용하면 변분 양자 고유해석기(Variational Quantum Eigensolver, VQE) 및 양자 근사 최적화 알고리즘(Quantum Approximate Optimization Algorithm, QAOA)과 같은 하이브리드 양자-고전 알고리즘을 실행하여 고전 컴퓨팅 리소스를 양자 컴퓨팅 디바이스와 결합해 오늘날 양자 시스템의 성능을 최적화할 수 있습니다. Amazon Braket Hybrid Jobs는 다음과 같은 세 가지 주요 이점을 제공합니다.
-
성능: Amazon Braket Hybrid Jobs는 자체 환경에서 하이브리드 알고리즘을 실행하는 것보다 더 나은 성능을 제공합니다. 작업이 실행되는 동안 선택한 대상 QPU에 우선적으로 액세스할 수 있습니다. 따라서 해당 양자 작업의 작업이 디바이스에 대기 중인 다른 작업보다 먼저 실행됩니다. 따라서 하이브리드 알고리즘의 런타임이 단축되고 예측 가능성은 더 높아집니다. Amazon Braket Hybrid Jobs는 파라메트릭 컴파일도 지원합니다. 자유 파라미터를 사용하여 회로를 제출할 수 있으며 Braket은 동일한 회로에 대한 후속 파라미터 업데이트를 위해 다시 컴파일할 필요 없이 회로를 한 번 컴파일하므로 런타임이 훨씬 빨라집니다.
-
편의성: Amazon Braket Hybrid Jobs는 컴퓨팅 환경 설정 및 관리를 간소화하고 하이브리드 알고리즘이 실행되는 동안 환경을 계속 가동 상태로 유지합니다. 알고리즘 스크립트를 제공하고 실행할 양자 디바이스(양자 처리 장치 또는 시뮬레이터)를 선택하면 됩니다. Amazon Braket은 대상 디바이스가 사용 가능 상태가 될 때까지 대기하고 고전 리소스를 구동하며 사전 빌드된 컨테이너 환경에서 워크로드를 실행하고 결과를 Amazon Simple Storage Service(Amazon S3)에 반환한 다음 컴퓨팅 리소스를 해제합니다.
-
지표: Amazon Braket Hybrid Jobs는 실행 중인 알고리즘에 대한 즉각적인 인사이트를 제공하고 사용자 지정 가능한 알고리즘 지표를 거의 실시간으로 Amazon CloudWatch 및 Amazon Braket 콘솔에 전달하여 알고리즘의 진행 상황을 추적할 수 있게 합니다.
Amazon Braket Hybrid Jobs를 사용한 하이브리드 작업 실행
Amazon Braket Hybrid Jobs로 하이브리드 작업을 실행하려면 먼저 알고리즘을 정의해야 합니다. Amazon Braket Python SDK
어느 경우든, 다음으로 Amazon Braket API를 사용하여 하이브리드 작업을 생성합니다. 여기서 알고리즘 스크립트 또는 컨테이너를 제공하고 하이브리드 작업이 사용할 대상 양자 디바이스를 선택한 다음 다양한 옵션 설정 중에서 선택합니다. 이러한 옵션 설정에 제공된 기본값은 대부분의 사용 사례에 적합합니다. 대상 디바이스에서 하이브리드 작업을 실행하려면 QPU, 온디맨드 시뮬레이터(예: SV1 또는 DM1) 또는 클래식 하이브리드 작업 인스턴스 자체 중에서 선택할 수 있습니다. 온디맨드 시뮬레이터 또는 QPU를 사용하면 하이브리드 작업 컨테이너가 원격 디바이스에 대한 API 직접 호출을 수행합니다. 임베디드 시뮬레이터를 사용하면, 시뮬레이터가 알고리즘 스크립트와 동일한 컨테이너에 임베디드됩니다. PennyLane의 라이트닝 시뮬레이터
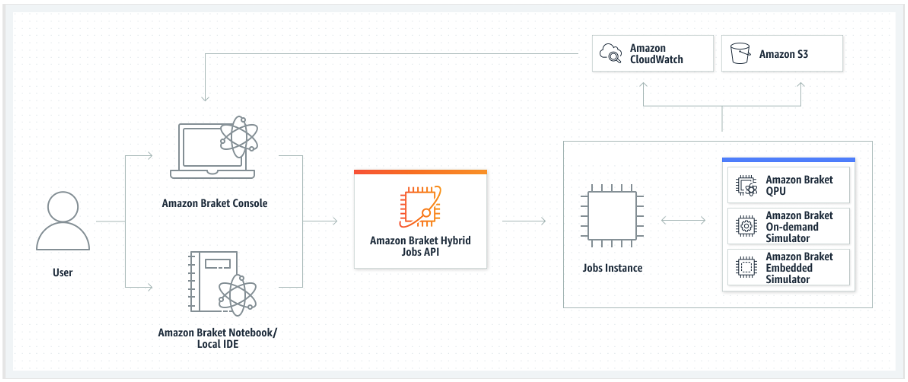
대상 디바이스가 온디맨드 또는 임베디드 시뮬레이터인 경우 Amazon Braket은 하이브리드 작업을 즉시 실행하기 시작합니다. 하이브리드 작업 인스턴스를 구동하고(API 직접 호출 시 인스턴스 유형을 사용자 지정할 수 있음) 알고리즘을 실행하며 Amazon S3에 결과를 쓰고 리소스를 해제합니다. 이러한 리소스 해제 방식 덕분에 사용한 만큼만 비용을 지불하면 됩니다.
QPU당 동시 하이브리드 작업의 총 수는 제한됩니다. 현재 QPU에서는 한 번에 하나의 하이브리드 작업만 실행할 수 있습니다. 대기열은 허용된 제한을 초과하지 않도록 실행이 허용되는 하이브리드 작업의 수를 제어하는 데 사용됩니다. 대상 디바이스가 QPU인 경우 하이브리드 작업은 먼저 선택한 QPU의 작업 대기열에 들어갑니다. Amazon Braket은 필요한 하이브리드 작업 인스턴스를 구동하고 디바이스에서 하이브리드 작업을 실행합니다. 알고리즘 실행 기간 동안에는 하이브리드 작업이 우선적으로 처리됩니다. 즉, 하이브리드 작업의 양자 작업이 디바이스에 대기 중인 다른 Braket 양자 작업보다 먼저 실행됩니다. 단, 하이브리드 작업의 양자 작업은 몇 분 간격으로 QPU에 제출되어야 합니다. 하이브리드 작업이 완료되면 리소스가 해제되므로, 사용한 만큼만 비용을 지불하면 됩니다.
참고
디바이스는 리전별이며 하이브리드 작업은 기본 디바이스 AWS 리전 와 동일한에서 실행됩니다.
시뮬레이터 및 QPU 대상 시나리오 모두에서 알고리즘의 일부로 해밀토니안의 에너지와 같은 사용자 지정 알고리즘 지표를 정의할 수 있는 옵션이 있습니다. 이러한 지표는 Amazon CloudWatch에 자동으로 보고되며 거기서 Amazon Braket 콘솔에 거의 실시간으로 표시됩니다.
참고
GPU 기반 인스턴스를 사용하려면 Braket의 임베디드 시뮬레이터와 함께 사용할 수 있는 GPU 기반 시뮬레이터 중 하나를 사용해야 합니다(예: lightning.gpu). CPU 기반 임베디드 시뮬레이터(예: lightning.qubit또는 braket:default-simulator) 중 하나를 선택하면 GPU가 사용되지 않으므로 불필요한 비용이 발생할 수 있습니다.
