기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
하이브리드 작업 생성
이 섹션에서는 Python 스크립트를 사용하여 하이브리드 작업을 생성하는 방법을 보여줍니다. 또는 선호하는 통합 개발 환경(IDE)이나 Braket 노트북 같은 로컬 Python 코드에서 하이브리드 작업을 생성하려면 로컬 코드를 하이브리드 작업으로 실행을 참조하세요.
생성 및 실행
하이브리드 작업을 실행할 권한이 있는 역할이 있으면 바로 진행할 수 있습니다. 첫 번째 Braket 하이브리드 작업의 핵심은 알고리즘 스크립트입니다. 실행하려는 알고리즘을 정의하고 알고리즘의 일부인 고전 논리 및 양자 작업을 포함합니다. 알고리즘 스크립트 외에도 다른 종속성 파일을 제공할 수 있습니다. 알고리즘 스크립트와 해당 종속성을 합쳐서 소스 모듈이라고 합니다. 진입점은 하이브리드 작업이 시작될 때 소스 모듈에서 실행할 첫 번째 파일 또는 함수를 정의합니다.
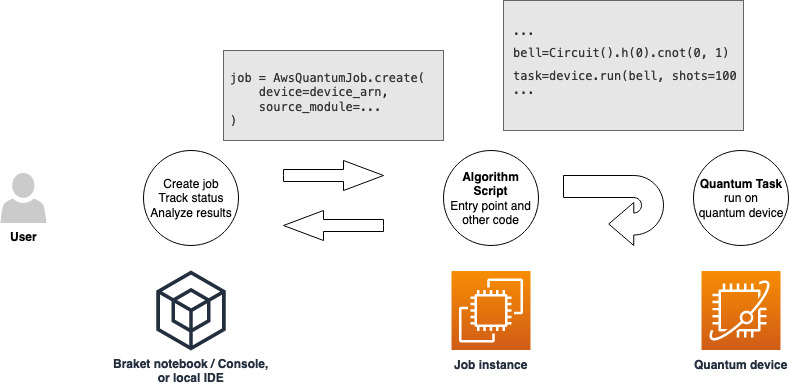
먼저 5개의 벨 상태를 생성하고 해당 측정 결과를 출력하는 알고리즘 스크립트의 다음 기본 예제를 살펴보세요.
import os from braket.aws import AwsDevice from braket.circuits import Circuit def start_here(): print("Test job started!") # Use the device declared in the job script device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test job completed!")
이 파일을 Braket 노트북 또는 로컬 환경의 현재 작업 디렉터리에 algorithm_script.py라는 이름으로 저장합니다. algorithm_script.py 파일은 start_here()를 계획된 진입점으로 사용합니다.
그런 다음 algorithm_script.py 파일과 동일한 디렉터리에 Python 파일 또는 Python 노트북을 생성합니다. 이 스크립트는 하이브리드 작업을 시작하고 상태나 관심 대상 주요 결과 출력과 같은 모든 비동기 처리를 해결합니다. 최소한 이 스크립트는 하이브리드 작업 스크립트와 기본 디바이스를 지정해야 합니다.
참고
노트북과 동일한 디렉터리에 Braket 노트북을 생성하거나 algorithm_script.py 파일과 같은 파일을 업로드하는 방법에 대한 자세한 내용은 Amazon Braket Python SDK를 사용하여 첫 번째 회로 실행을 참조하세요.
이 기본적인 첫 번째 사례의 경우 시뮬레이터를 대상으로 합니다. 대상 양자 디바이스 유형, 시뮬레이터 또는 실제 QPU에 관계없이 다음 스크립트에서 device로 지정하는 디바이스는 하이브리드 작업을 예약하는 데 사용되며 알고리즘 스크립트에서 환경 변수 AMZN_BRAKET_DEVICE_ARN으로 사용할 수 있습니다.
참고
하이브리드 작업 AWS 리전 의에서 사용할 수 있는 디바이스만 사용할 수 있습니다. Amazon Braket SDK는 이 AWS 리전을 자동으로 선택합니다. 예를 들어 us-east-1의 하이브리드 작업은 , IonQ SV1및 DM1 디바이스를 사용할 수 있지만 Rigetti 디바이스는 사용할 수 없습니다.
시뮬레이터 대신 양자 컴퓨터를 선택하면, Braket은 하이브리드 작업을 예약하여 모든 양자 작업을 우선적으로 실행하도록 합니다.
from braket.aws import AwsQuantumJob from braket.devices import Devices job = AwsQuantumJob.create( Devices.Amazon.SV1, source_module="algorithm_script.py", entry_point="algorithm_script:start_here", wait_until_complete=True )
파라미터 wait_until_complete=True는 작업이 실행 중인 실제 작업의 출력을 인쇄하도록 자세한 정보 표시 모드를 설정합니다. 다음 예제와 유사한 출력이 표시됩니다.
Initializing Braket Job: arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 Job queue position: 1 Job queue position: 1 Job queue position: 1 .............. . . . Beginning Setup Checking for Additional Requirements Additional Requirements Check Finished Running Code As Process Test job started! Counter({'00': 58, '11': 42}) Counter({'00': 55, '11': 45}) Counter({'11': 51, '00': 49}) Counter({'00': 56, '11': 44}) Counter({'11': 56, '00': 44}) Test job completed! Code Run Finished 2025-09-24 23:13:40,962 sagemaker-training-toolkit INFO Reporting training SUCCESS
참고
위치(로컬 디렉터리 또는 파일의 경로, 또는 tar.gz 파일의 S3 URI)를 전달하여 AwsQuantumJob.create
결과 모니터링
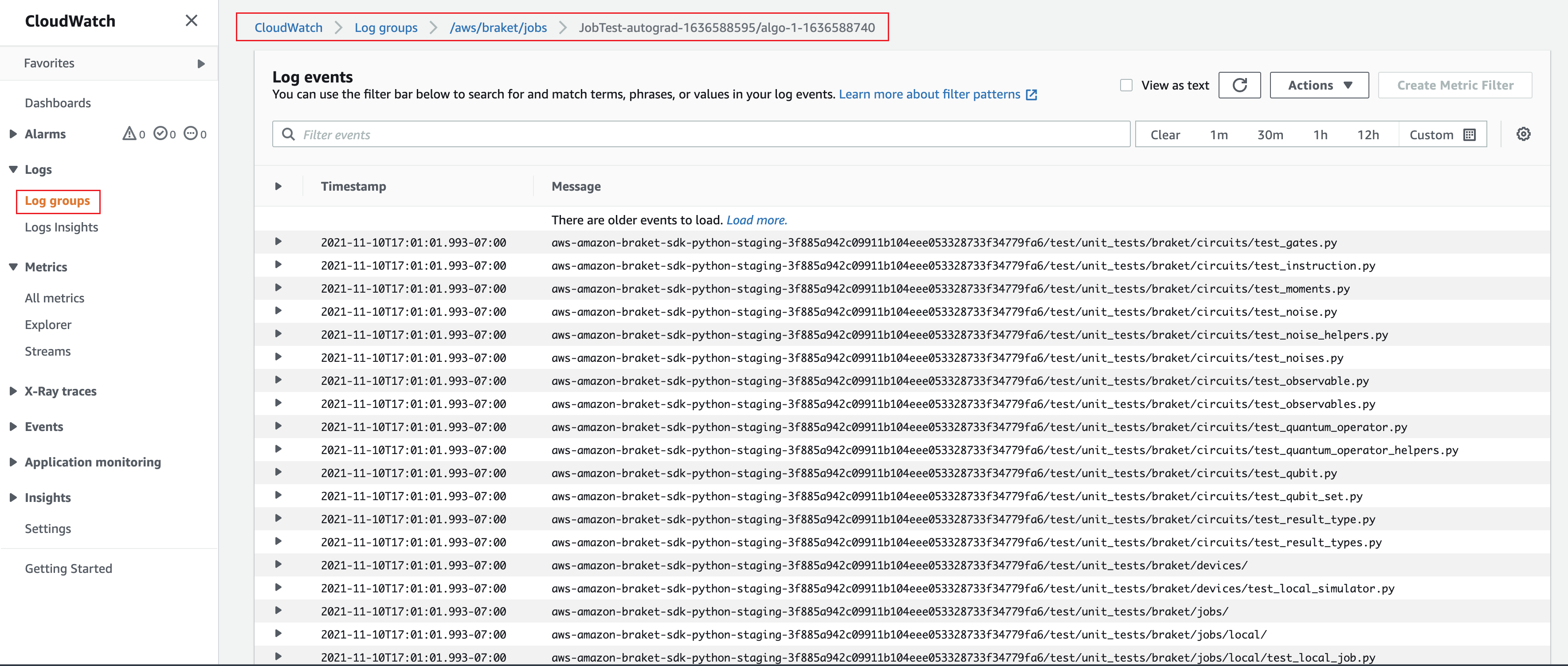
또는, Amazon CloudWatch의 로그 출력에 액세스할 수 있습니다. 이렇게 하려면 작업 세부 정보 페이지의 왼쪽 메뉴에 있는 로그 그룹 탭으로 이동하여 로그 그룹 aws/braket/jobs를 선택한 다음, 작업 이름이 포함된 로그 스트림을 선택합니다. 위 예제에서는 braket-job-default-1631915042705/algo-1-1631915190입니다.
하이브리드 작업 페이지를 선택한 다음 설정을 선택하여 콘솔에서 하이브리드 작업의 상태를 볼 수도 있습니다.
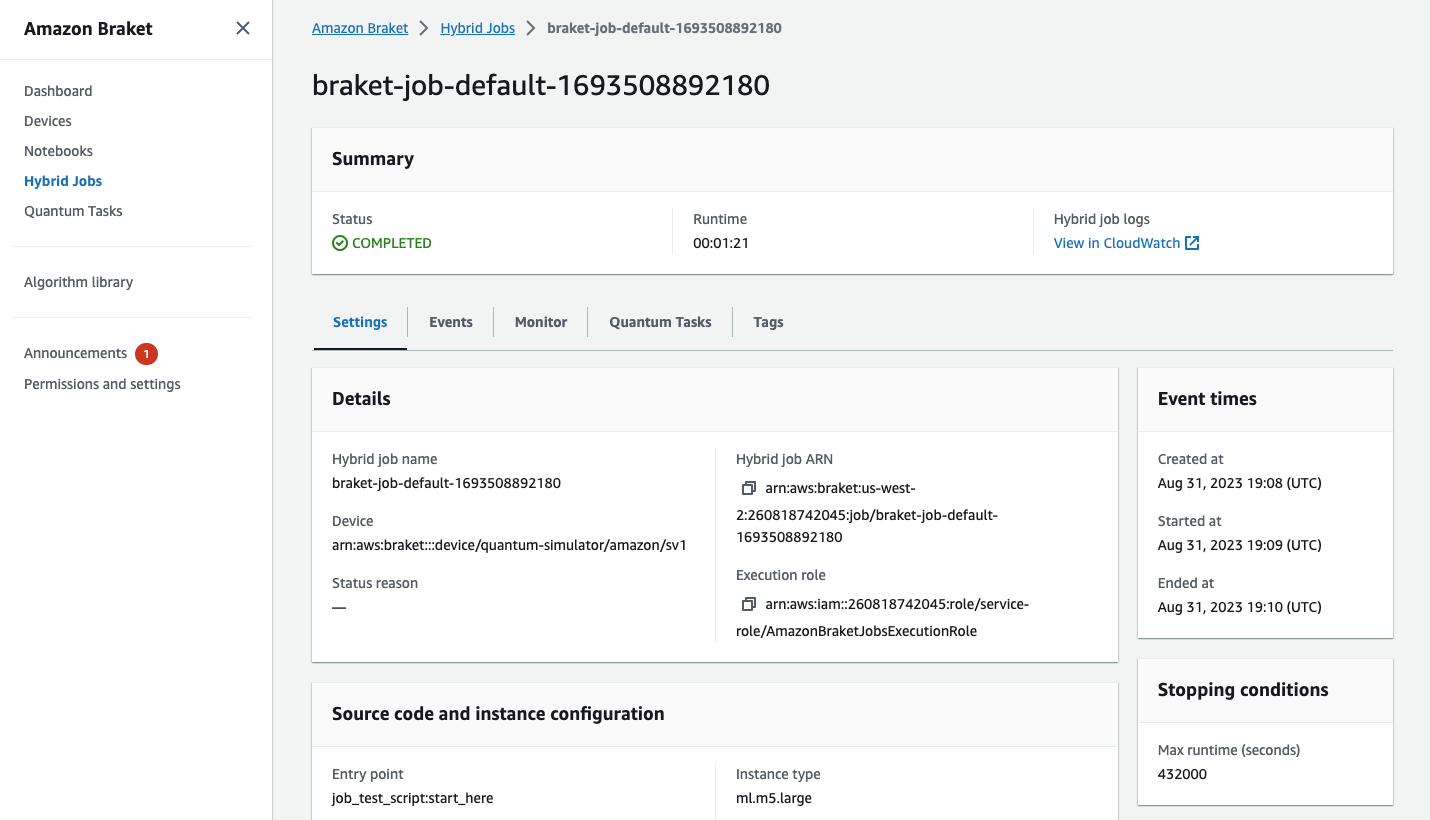
하이브리드 작업은 실행되는 동안 Amazon S3에서 일부 아티팩트를 생성합니다. 기본 S3 버킷 이름은 amazon-braket-<region>-<accountid>이고 콘텐츠는 jobs/<jobname>/<timestamp> 디렉터리에 있습니다. Braket Python SDK를 사용하여 하이브리드 작업을 생성할 때 다른 code_location을 지정하여 이러한 아티팩트가 저장되는 S3 위치를 구성할 수 있습니다.
참고
이 S3 버킷은 작업 스크립트 AWS 리전 와 동일한에 있어야 합니다.
jobs/<jobname>/<timestamp> 디렉터리에는 model.tar.gz 파일에 담긴 진입점 스크립트의 출력이 있는 하위 폴더가 포함되어 있습니다. 또한 source.tar.gz 파일에 알고리즘 스크립트 아티팩트가 포함된 script라고 하는 디렉터리도 있습니다. 실제 양자 작업의 결과는 jobs/<jobname>/tasks라는 디렉터리에 있습니다.
결과 저장
하이브리드 작업 스크립트의 하이브리드 작업 객체와 Amazon S3의 출력 폴더(model.tar.gz라는 이름의 tar-zipped 파일)에서 사용할 수 있도록 알고리즘 스크립트에서 생성된 결과를 저장할 수 있습니다.
출력은 JavaScript Object Notation(JSON) 형식을 사용하여 파일에 저장해야 합니다. 넘파이 배열의 경우처럼 데이터가 텍스트로 쉽게 직렬화될 수 없는 경우, 피클링된 데이터 형식을 사용하여 직렬화하는 옵션을 전달할 수 있습니다. 자세한 내용은 braket.jobs.data_persistence 모듈
하이브리드 작업의 결과를 저장하려면 #ADD로 주석이 달린 다음 줄을 algorithm_script.py 파일에 추가합니다.
import os from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_result # ADD def start_here(): print("Test job started!") device = AwsDevice(os.environ['AMZN_BRAKET_DEVICE_ARN']) results = [] # ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) results.append(task.result().measurement_counts) # ADD save_job_result({"measurement_counts": results}) # ADD print("Test job completed!")
그런 다음 #ADD로 주석이 달린 줄 print(job.result())를 추가하여 작업 스크립트의 작업 결과를 표시할 수 있습니다.
import time from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="algorithm_script.py", entry_point="algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", ) print(job.arn) while job.state() not in AwsQuantumJob.TERMINAL_STATES: print(job.state()) time.sleep(10) print(job.state()) print(job.result()) # ADD
이 예제에서는 자세한 정보 출력을 억제하기 위해 wait_until_complete=True를 제거했습니다. 디버깅을 위해 다시 추가할 수 있습니다. 이 하이브리드 작업을 실행하면 식별자와 job-arn을 출력한 다음 하이브리드 작업이 COMPLETED 상태가 될 때까지 10초마다 하이브리드 작업의 상태를 출력한 후에 벨 회로의 결과가 보여줍니다. 다음 예제를 참조하세요.
arn:aws:braket:us-west-2:111122223333:job/braket-job-default-123456789012 INITIALIZED RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING RUNNING ... RUNNING RUNNING COMPLETED {'measurement_counts': [{'11': 53, '00': 47},..., {'00': 51, '11': 49}]}
체크포인트 사용
체크포인트를 사용하여 하이브리드 작업의 중간 반복을 저장할 수 있습니다. 이전 섹션의 알고리즘 스크립트 예제에서 체크포인트 파일을 생성하려면 #ADD로 주석이 달린 다음 줄을 추가하면 됩니다.
from braket.aws import AwsDevice from braket.circuits import Circuit from braket.jobs import save_job_checkpoint # ADD import os def start_here(): print("Test job starts!") device = AwsDevice(os.environ["AMZN_BRAKET_DEVICE_ARN"]) # ADD the following code job_name = os.environ["AMZN_BRAKET_JOB_NAME"] save_job_checkpoint(checkpoint_data={"data": f"data for checkpoint from {job_name}"}, checkpoint_file_suffix="checkpoint-1") # End of ADD bell = Circuit().h(0).cnot(0, 1) for count in range(5): task = device.run(bell, shots=100) print(task.result().measurement_counts) print("Test hybrid job completed!")
하이브리드 작업을 실행하면 기본 /opt/jobs/checkpoints 경로의 체크포인트 디렉터리 내 하이브리드 작업 아티팩트에 <jobname>-checkpoint-1.json 파일이 생성됩니다. 이 기본 경로를 변경하지 않는 한 하이브리드 작업 스크립트는 변경되지 않습니다.
이전 하이브리드 작업에서 생성된 체크포인트에서 하이브리드 작업을 로드하려는 경우 알고리즘 스크립트는 from braket.jobs import load_job_checkpoint를 사용합니다. 알고리즘 스크립트에 로드할 논리는 다음과 같습니다.
from braket.jobs import load_job_checkpoint checkpoint_1 = load_job_checkpoint( "previous_job_name", checkpoint_file_suffix="checkpoint-1", )
이 체크포인트를 로드한 후 checkpoint-1에 로드된 콘텐츠를 기반으로 논리를 계속 진행할 수 있습니다.
참고
checkpoint_file_suffix는 체크포인트 생성 시 이전에 지정한 접미사와 일치해야 합니다.
오케스트레이션 스크립트는 #ADD로 주석이 달린 줄로 이전 하이브리드 작업의 job-arn을 지정해야 합니다.
from braket.aws import AwsQuantumJob job = AwsQuantumJob.create( source_module="source_dir", entry_point="source_dir.algorithm_script:start_here", device="arn:aws:braket:::device/quantum-simulator/amazon/sv1", copy_checkpoints_from_job="<previous-job-ARN>", #ADD )
