Amazon Timestream for LiveAnalytics に類似した機能をご希望の場合は Amazon Timestream for InfluxDB をご検討ください。リアルタイム分析に適した、シンプルなデータインジェストと 1 桁ミリ秒のクエリ応答時間を特徴としています。詳細については、こちらを参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Timestream for InfluxDB とは
Amazon Timestream for InfluxDB は、アプリケーションデベロッパーや DevOps チームが、オープンソース API を使用してリアルタイムの時系列アプリケーション AWS 用に InfluxDB データベースを簡単に で実行できるようにするマネージド時系列データベースエンジンです。 APIs Amazon Timestream for InfluxDB を使えば、時系列ワークロードを簡単に設定、運用、スケールでき、1 桁ミリ秒の応答時間でクエリに応答できます。
Amazon Timestream for InfluxDB では、2.x ブランチの、使い慣れたオープンソース版の InfluxDB の機能を利用できます。つまり、現在、既存の InfluxDB オープンソースデータベースで使用しているコード、アプリケーション、ツールは、Amazon Timestream for InfluxDB とシームレスに連携するはずです。Amazon Timestream for InfluxDB は、データベースを自動的にバックアップし、データベースのソフトウェアを最新のバージョンによって更新された状態に保ちます。さらに、Amazon Timestream for InfluxDB では、レプリケーションを使って簡単にデータベースの可用性を高めたりデータの耐久性を向上させたりできます。すべての AWS サービスと同様に、前払いの投資は必要なく、使用したリソースに対してのみお支払いいただきます。
DB インスタンス
DB インスタンスはクラウドで実行される独立したデータベース環境です。これは Amazon Timestream for InfluxDB の基本要素です。DB インスタンスには、ユーザーが作成した複数のデータベース (InfluxDB 2.x データベースの場合は組織とバケット) を含めることができ、スタンドアロンのセルフマネージド InfluxDB インスタンスにアクセスする場合と同じクライアントツールおよびアプリケーションを使用して、アクセスすることが可能です。DB インスタンスは、 AWS コマンドラインツール、Amazon Timestream InfluxDB API オペレーション、または AWS マネジメントコンソールを使用して簡単に作成、変更できます。
注記
Amazon Timestream for InfluxDB は、Influx API のオペレーションと Influx UI を使用したデータベースへのアクセスをサポートしています。Amazon Timestream for InfluxDB では、ホストへの直接アクセスは許可されません。
最大 40 の Amazon Timestream for InfluxDB インスタンスを設定できます。
各 DB インスタンスに、DB インスタンス ID があります。このサービスで生成された名前は、Amazon Timestream for InfluxDB API および CLI コマンドを操作するときに DB インスタンスを一意に識別 AWS します。DB インスタンス ID は、 AWS リージョンの顧客に対して一意です。
DB インスタンス ID は、Timestream for InfluxDB によってインスタンスに割り当てられる DNS ホスト名の一部を構成します。例えば、DB インスタンス名として influxdb1 を指定し、サービスがインスタンス ID c5vasdqn0b を生成した場合、Timestream は自動的に DNS エンドポイントをインスタンスに割り当てます。エンドポイントの一例が c5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws です。この場合、c5vasdqn0b がインスタンス ID です。2024 年 12 月 9 日以前に作成されたインスタンスでは、引き続き influxdb1-3ksj4dla5nfjhi.us-east-1.timestream-influxdb.amazonaws.com のようなエンドポイントを持つ古い構造が使用されます。ここでは influxdb1 がインスタンス名です。
エンドポイント の例ではc5vasdqn0b-3ksj4dla5nfjhi.timestream-influxdb.us-east-1.on.aws、文字列3ksj4dla5nfjhiは によって生成された一意のアカウント識別子です AWS。この例の識別子 3ksj4dla5nfjhi は、特定のリージョンにある指定されたアカウントでは変更されません。したがって、このアカウントが作成したすべての DB インスタンスは、このリージョンにおける同一の固定識別子を共有します。固定識別子の以下の特徴を考えてみましょう。
-
現在、Timestream for InfluxDB は DB インスタンスの名前変更をサポートしていません。
-
2024 年 12 月 9 日以降に作成されたインスタンスについては、同じ DB インスタンス名を使って DB インスタンスを削除し再作成すると、そのインスタンスに新しいインスタンス ID が割り当てられるため、エンドポイントは変更されます。上記の日付よりも前に作成されたインスタンスは、インスタンス名に基づいて同じエンドポイントが割り当てられます。
-
同じアカウントを使用して別のリージョンに DB インスタンスを作成した場合、内部で生成される識別子は異なります。これは、
zxlasoonhvd.4a3j5du5ks7md2.timestream-influxdb.us-east-1.on.awsにあるようにリージョンが異なるためです。
各 DB インスタンスは、1 つの Timestream for InfluxDB データベースエンジンのみをサポートします。
DB インスタンスを作成するときは、InfluxDB で組織名を指定する必要があります。DB インスタンスは、複数の組織と、各組織に関連付けられた複数のバケットをホストできます。
Amazon Timestream for InfluxDB は、作成プロセスの一環としてユーザーに DB インスタンスのマスターユーザーアカウントとパスワードを作成することを許可します。このマスターユーザーには、組織やバケットを作成したり、データに対して読み取り、書き込み、削除、アップサート操作を実行したりできるアクセス許可が付与されます。また、最初のログイン時に InfluxUI にアクセスしてオペレータートークンを取得することもできます。そこからすべてのアクセストークンを管理することも可能です。DB インスタンスを作成するときはマスターユーザーパスワードを設定する必要がありますが、このパスワードは、Influx API、Influx CLI、InfluxUI を使っていつでも変更できます。
DB インスタンスクラス
DB インスタンスクラスは、Amazon Timestream for InfluxDB DB インスタンスの計算とメモリの容量を決定します。必要な DB インスタンスクラスは、処理能力とメモリの要件によって異なります。
DB インスタンスクラスは、DB インスタンスクラスタイプとサイズの両方で構成されます。例えば db.influx は、InfluxDB ワークロードの実行に関連する高性能なメモリ要件に適した、メモリ最適化 DB インスタンスクラスタイプです。db.influx インスタンスクラスタイプ内の db.influx.2xlarge は、DB インスタンスクラスです。このクラスのサイズは 2xlarge です。
インスタンスクラスの料金の詳細については、Amazon Timestream for InfluxDB の料金
DB インスタンスクラスタイプ
Amazon Timestream for InfluxDB は、InfluxDB のユースケースに最適化された以下のユースケースの DB インスタンスクラスをサポートしています。
-
db.influx– このインスタンスクラスは、オープンソースの InfluxDB データベースでメモリ負荷の高いワークロードを実行するのに適しています。
DB インスタンスクラスのハードウェア仕様
以下は、DB インスタンスクラスのハードウェア仕様に関する用語をまとめた用語集です。
-
vCPU
仮想中央演算装置 (CPU) の数。仮想 CPU は、DB インスタンスクラスの比較に使用できる容量の単位です。
-
メモリ (GiB)
DB インスタンスに割り当てられる RAM (ギガバイナリバイト単位)。通常、メモリと vCPU の比率は一定です。例として db.influx インスタンスクラスを使います。こちらの memory-to-vCPU 比率は、EC2 r7g インスタンスクラスと同様です。
-
Influx 最適化
DB インスタンスは、最適化された設定スタックを使用し、I/O 用に専用の容量を追加で提供します。このように最適化することで、I/O と、インスタンスからのその他のトラフィックとの間の競合を最小に抑え、最高のパフォーマンスを実現します。
-
ネットワーク帯域幅
他の DB インスタンスクラスとの相対的なネットワーク速度。以下の表は、Amazon Timestream for InfluxDB インスタンスクラスに関するハードウェアの詳細を示したものです。
| インスタンスクラス | vCPU | メモリ (GiB) | ストレージタイプ | ネットワーク帯域幅 (Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | Influx IOPS 込み | 10 |
| db.influx.large | 2 | 16 | Influx IOPS 込み | 10 |
| db.influx.xlarge | 4 | 32 | Influx IOPS 込み | 10 |
| db.influx.2xlarge | 8 | 64 | Influx IOPS 込み | 10 |
| db.influx.4xlarge | 16 | 128 | Influx IOPS 込み | 10 |
| db.influx.8xlarge | 32 | 256 | Influx IOPS 込み | 12 |
| db.influx.12xlarge | 48 | 384 | Influx IOPS 込み | 20 |
| db.influx.16xlarge | 64 | 512 | Influx IOPS 込み | 25 |
| db.influx.24xlarge | 96 | 768 | Influx IOPS 込み | 40 |
InfluxDB インスタンスストレージ
Amazon Timestream for InfluxDB の DB インスタンスは、データベースとログストレージに Influx IOPS 込みボリュームを使用します。
場合によっては、データベースワークロードは、プロビジョニングした IOPS を 100% 到達できません。詳細については、「ストレージのパフォーマンスに影響する要因」を参照してください。Timestream for InfluxDB ストレージの料金の詳細については、Amazon Timestream の料金
Amazon Timestream for InfluxDB ストレージタイプ
Amazon Timestream for InfluxDB は、単一のストレージタイプ「Influx IOPS 込み」をサポートしています。最大で 16 テビバイト (TiB) のストレージの Timestream for InfluxDB インスタンスを作成できます。
使用可能なストレージタイプについて、以下で簡単に説明します。
-
Influx IO 込みストレージ: ストレージパフォーマンスは、秒あたりの I/O オペレーション (IOPS) と、ストレージボリュームが読み取りと書き込みを実行できる速度 (ストレージスループット) とを組み合わせたものです。Influx IOPS 込みのストレージボリュームでは、Amazon Timestream for InfluxDB には、さまざまな種類のワークロードに必要な、最適な IOPS とスループットが事前設定された 3 つのストレージ階層が用意されています。
InfluxDB インスタンスのサイジング
Timestream for InfluxDB インスタンスの最適な設定は、さまざまな要因 (取り込みレート、バッチサイズ、時系列カーディナリティ、同時クエリ、クエリタイプなど) によって変わってきます。推奨されるサイジングを特定するため、以下の特性を持つ代表的なワークロードについて考えてみましょう。
-
データは、データセンターから、システム、CPU、メモリ、ディスク、IO その他を集める Telegraf エージェントフリートによって収集され書き込まれます。
書き込みリクエストにはそれぞれ 5,000 行が含まれます。
-
システムで実行されるクエリは、「複雑さが中程度」のクエリとして分類され、以下の特性を持っています。
-
複数の関数および 1 つまたは 2 つの正規表現を持ちます。
-
group by 句が含まれていたり、複数週にわたる時間範囲をサンプリングしたりすることがあります。
-
通常、実行には数百ミリ秒~数千ミリ秒かかります。
-
CPU は主としてクエリパフォーマンスを優先します。
-
| 時系列の最大数 | 書き込み (秒あたりの行数) | 読み取り (秒あたりのクエリ数) | インスタンスクラス | ストレージタイプ |
|---|---|---|---|---|
| <10 万 | 約 50,000 | <10 | db.influx.large | Influx IO 込み 3K |
| <100 万 | 約 150,000 | <25 | db.influx.2xlarge | Influx IO 込み 3K |
| 約 100 万 | 約 200,000 | 約 25 | db.influx.4xlarge | Influx IO 込み 3K |
| <500 万 | 約 250,000 | 約 35 | db.influx.4xlarge | Influx IO 込み 12K |
| <1,000 万 | 約 500,000 | 約 50 | db.influx.8xlarge | Influx IO 込み 12K |
| 約 1,000 万 | <750,000 | <100 | db.influx.12xlarge | Influx IO 込み 12K |
AWS リージョン および アベイラビリティーゾーン
Amazon クラウドコンピューティングリソースは、世界各地の多くの場所でホストされています。これらの場所は、 AWS リージョン と で構成されます。各 AWS リージョンは個別の地理的領域です。各 AWS リージョンには、アベイラビリティーゾーンと呼ばれる複数の独立した場所があります。
注記
AWS リージョンの を検索する方法については、「Amazon EC2 ユーザーガイド」の「リージョンとゾーン」を参照してください。 Amazon EC2
Amazon Timestream for InfluxDB を使用すると、DB インスタンスなどのリソースやデータを複数の場所に配置できます。
Amazon は、アベイラビリティーの高い最新のデータセンターを運用しています。ただし、非常にまれですが、同じ場所にある DB インスタンスすべての可用性に影響する障害が発生することもあります。すべての DB インスタンスを 1 か所でホストしている場合、そのような障害が起きた際に DB インスタンスがすべて利用できなくなります。
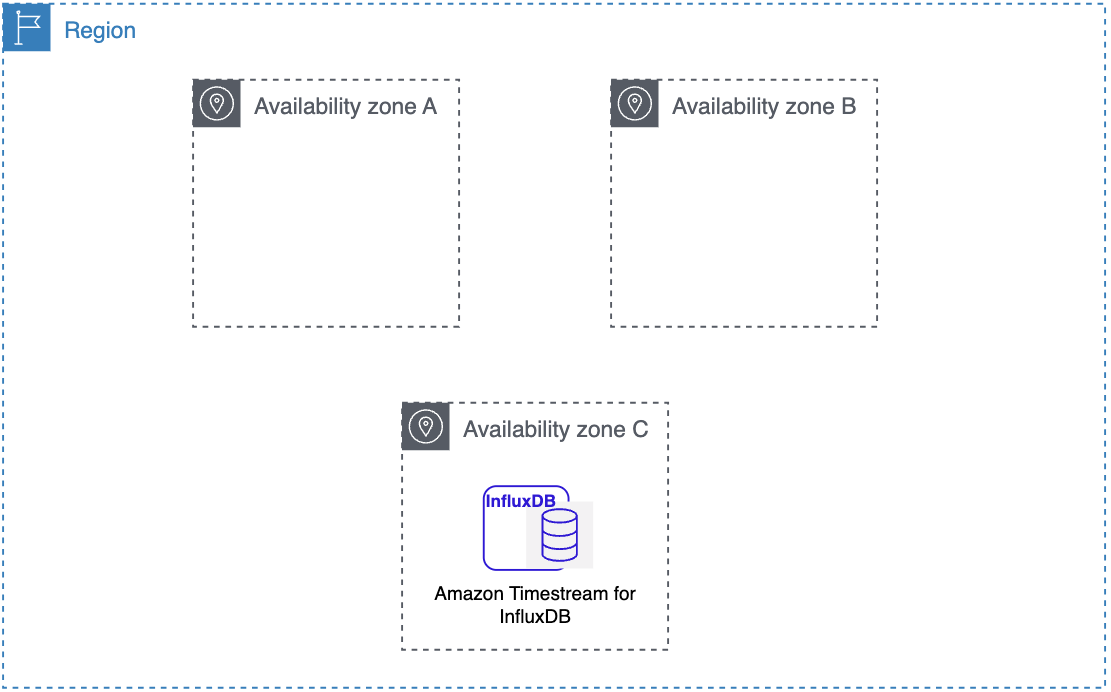
各 AWS リージョンは完全に独立していることを覚えておくことが重要です。開始した Amazon Timestream for InfluxDB アクティビティ (データベースインスタンスの作成や使用可能なデータベースインスタンスの一覧表示など) は、現在のデフォルト AWS リージョンでのみ実行されます。デフォルトの AWS リージョンは、コンソールで変更するか、環境変数 AWS_DEFAULT_REGION を設定することにより変更できます。または、 AWS Command Line Interface () で --regionパラメータを使用して上書きすることもできますAWS CLI。詳細については、「 の設定 AWS Command Line Interface」、特に環境変数とコマンドラインオプションに関するセクションを参照してください。
特定の AWS リージョンの Amazon Timestream for InfluxDB DB インスタンスを作成または操作するには、対応するリージョンのサービスエンドポイントを使用します。
AWS リージョンの可用性
次の表は、Amazon Timestream for InfluxDB が現在利用可能な AWS リージョンと、各リージョンのエンドポイントを示しています。
| AWS リージョン名 | リージョン | エンドポイント | プロトコル |
|---|---|---|---|
| 米国東部 (バージニア北部) | us-east-1 | timestream-influxdb.us-east-1.amazonaws.com | HTTPS |
| 米国東部 (オハイオ) | us-east-2 | timestream-influxdb.us-east-2.amazonaws.com | HTTPS |
| 米国西部 (オレゴン) | us-west-2 | timestream-influxdb.us-west-2.amazonaws.com | HTTPS |
| アジアパシフィック (ムンバイ) | ap-south-1 | timestream-influxdb.ap-south-1.amazonaws.com | HTTPS |
| アジアパシフィック (シンガポール) | ap-southeast-1 | timestream-influxdb.ap-southeast-1.amazonaws.com | HTTPS |
| アジアパシフィック (シドニー) | ap-southeast-2 | timestream-influxdb.ap-southeast-2.amazonaws.com | HTTPS |
| アジアパシフィック (東京) | ap-northeast-1 | timestream-influxdb.ap-northeast-1.amazonaws.com | HTTPS |
| 欧州 (フランクフルト) | eu-central-1 | timestream-influxdb.eu-central-1.amazonaws.com | HTTPS |
| 欧州 (アイルランド) | eu-west-1 | timestream-influxdb.eu-west-1.amazonaws.com | HTTPS |
| 欧州 (ストックホルム) | eu-north-1 | timestream-influxdb.eu-north-1.amazonaws.com | HTTPS |
| カナダ (中部) | ca-central-1 | timestream-influxdb.ca-central-1.amazonaws.com | HTTPS |
| 欧州 (ロンドン) | eu-west-2 | timestream-influxdb.eu-west-2.amazonaws.com | HTTPS |
| 欧州 (パリ) | eu-west-3 | timestream-influxdb.eu-west-3.amazonaws.com | HTTPS |
| アジアパシフィック (ジャカルタ) | ap-southeast-3 | timestream-influxdb.ap-southeast-3.amazonaws.com | HTTPS |
| ヨーロッパ (ミラノ) | eu-south-1 | timestream-influxdb.eu-south-1.amazonaws.com | HTTPS |
| 欧州 (スペイン) | eu-south-2 | timestream-influxdb.eu-south-2.amazonaws.com | HTTPS |
| 中東 (UAE) | me-central-1 | timestream-influxdb.me-central-1.amazonaws.com | HTTPS |
| 中国 (北京) | cn-north-1 | timestream-influxdb---cn-north-1---on.amazonwebservices.com.rproxy.govskope.ca.cn | HTTPS |
| 中国 (寧夏) | cn-northwest-1 | timestream-influxdb---cn-northwest-1---on.amazonwebservices.com.rproxy.govskope.ca.cn | HTTPS |
Amazon Timestream for InfluxDB が現在利用可能な AWS リージョンと各リージョンのエンドポイントの詳細については、「Amazon Timestream エンドポイントとクォータ」を参照してください。
AWS リージョン設計
各 AWS リージョンは、他の AWS リージョンから分離されるように設計されています。この設計により、最大限の耐障害性と安定性が達成されます。
リソースを表示すると、指定した AWS リージョンに関連付けられているリソースのみが表示されます。これは、 AWS リージョンが互いに分離されており、 AWS リージョン間でリソースを自動的にレプリケートしないためです。
AWS アベイラビリティーゾーン
DB インスタンスを作成すると、Amazon Timestream for InfluxDB は、サブネットの設定に基づき、ユーザーに代わってインスタンスをランダムに選択します。アベイラビリティーゾーンは、 AWS リージョンコードに続けて文字識別子 ( などus-east-1a) で表されます。
次のように describe-availability-zones Amazon EC2 コマンドを使用して、お使いのアカウントで有効な、指定されたリージョン内のアベイラビリティーゾーンを記述します。
aws ec2 describe-availability-zones --region region-name
例えば、アカウントで有効になっている米国東部 (バージニア北部) リージョン (us-east-1) 内のアベイラビリティーゾーンを記述するときは、次のコマンドを実行します。
aws ec2 describe-availability-zones --regionus-east-1
プライマリ DB インスタンスとセカンダリ DB インスタンスのアベイラビリティーゾーンを、マルチ AZ DB 配置で選択することはできません。Amazon Timestream for InfluxDB はユーザーに代わってそれらをランダムに選択します。マルチ AZ 配置については、「マルチ AZ 配置の設定と管理」を参照してください。
Amazon Timestream for InfluxDB の DB インスタンスの請求
Amazon Timestream for InfluxDB インスタンスは、以下の要素に基づいて課金されます。
-
DB インスタンス時間 (1 時間あたり) – DB インスタンスの DB インスタンスクラス (db.influx.large など) に基づきます。料金は 1 時間単位で表示されますが、請求の計算方法には秒単位が適用され、時間は 10 進形式で表示されます。Amazon Timestream for InfluxDB の使用料は 1 秒ごとに課金され、10 分未満の場合は 10 分の料金が発生します。詳細については、「DB インスタンスクラス」を参照してください。
-
ストレージ (月あたりの GiB) – DB インスタンスにプロビジョニングしたストレージ容量。詳細については、「InfluxDB インスタンスストレージ」を参照してください。
-
データ転送 (GB あたり) — インターネットや他の AWS リージョンとの間で DB インスタンスとの間で送受信されるデータ転送。
Amazon Timestream for InfluxDB の料金情報については、Amazon Timestream for InfluxDB の料金ページ
Amazon Timestream for InfluxDB のセットアップ
Amazon Timestream for InfluxDB を初めて使用するときは、先に次のタスクを完了させてください。
AWS アカウントが既にある場合は、Amazon Timestream for InfluxDB の要件を把握し、IAM および Amazon VPC のデフォルトを使用することを希望しますTimestream for InfluxDB の開始方法。
AWS アカウントにサインアップする
AWS アカウントがない場合は、次の手順を実行してアカウントを作成します。
AWS アカウントにサインアップするには
-
AWS サインイン
ページに移動します。 -
[新しいアカウントを作成] を選択し、表示された指示に従います。
注記
サインアップ手順の一環として、通話呼び出しを受け取り、電話キーパッドで検証コードを入力するように求められます。
AWS アカウントにサインアップすると、 AWS アカウントのルートユーザーが作成されます。ルートユーザーは、アカウント内のすべての AWS サービスとリソースにアクセスできます。セキュリティのベストプラクティスとして、管理ユーザーに管理アクセスを割り当て、ルートユーザーアクセスが必要なタスクを実行する場合にのみ、ルートユーザーを使用してください。
AWS サインアッププロセスが完了すると、 から確認メールが送信されます。https://aws.amazon.com/
ユーザー管理
管理ユーザーを作成する
管理ユーザーの作成
AWS アカウントにサインアップしたら、日常的なタスクにルートユーザーを使用しないように管理ユーザーを作成します。
AWS アカウントのルートユーザーを保護する
ルートユーザーを選択し、アカウントの E メールアドレスを入力して、 AWS アカウント所有者 AWS マネジメントコンソール として にサインインします。次のページでパスワードを入力します。ルートユーザーを使用してサインインする方法についてのヘルプは、「AWS サインインユーザーガイド」の「AWS マネジメントコンソールにサインインします。」を参照してください。
ルートユーザーの多要素認証 (MFA) を有効にします。手順については、IAM ユーザーガイドの AWS 「アカウントルートユーザー (コンソール) の仮想 MFA デバイスを有効にする」を参照してください。
プログラムによるアクセスの付与
ユーザーが の AWS 外部で を操作する場合は、プログラムによるアクセスが必要です AWS マネジメントコンソール。プログラムによるアクセス権を付与する方法は、 AWSにアクセスしているユーザーのタイプによって異なります。
ユーザーにプログラムによるアクセスを許可するには、以下のうちいずれかの方法を選択します。
| プログラムによるアクセス権を必要とするユーザー | 目的 | 方法 |
|---|---|---|
| ワークフォースアイデンティティ (IAM アイデンティティセンターが管理しているユーザー) | 一時的な認証情報を使用して、CLI、 AWS SDKs、または API AWS へのプログラムによるリクエストに署名します。 AWS APIs |
使用するインターフェイスの指示に従ってください。 については AWS CLI、「 AWS Command Line Interface ユーザーガイド」の「 を使用した IAM アイデンティティセンター認証の設定 AWS CLI」を参照してください。 AWS SDKs、ツール、API については、 AWS APIsAWS 「 SDK とツールリファレンスガイド」の「IAM Identity Center を使用して SDK とツールを認証AWS SDKs」を参照してください。 |
| IAM | 一時的な認証情報を使用して、CLI、SDKs、API AWS APIs。 | 「 ユーザーガイド」の「 AWS リソースで一時的な認証情報を使用する」の手順に従います。 AWS Identity and Access Management |
| IAM | (非推奨) 長期的な認証情報を使用して、 AWS CLI、SDK、API へのプログラムによるリクエストに署名します。 |
使用するインターフェイスの指示に従ってください。 については AWS CLI、「 AWS Command Line Interface ユーザーガイド」の「 の IAM ユーザー認証情報を使用した認証 AWS CLI」を参照してください。 AWS SDKs「 SDK とツールリファレンスガイド AWS SDKs 」の「長期的な認証情報を使用して SDK とツールを認証する」を参照してください。 AWS SDKs API AWS APIsAWS Identity and Access Management 「 ユーザーガイド」の「IAM ユーザーのアクセスキーの管理」を参照してください。 |
要件の確認
Amazon Timestream for InfluxDB の基本要素となるのが DB インスタンスです。ユーザーは、DB インスタンス内で自分のバケットを作成します。DB インスタンスは、エンドポイントというネットワークアドレスを提供します。アプリケーションでは、このエンドポイントを使用して DB インスタンスに接続します。また InfluxUI にもお使いのブラウザから同じエンドポイントを使ってアクセスします。DB インスタンスを作成するときに、ストレージ、メモリ、データベースエンジンとバージョン、ネットワーク構成、セキュリティといった詳細を指定します。DB インスタンスへのネットワークアクセスは、セキュリティグループを通じて制御します。
DB インスタンスとセキュリティグループを作成する前に、DB インスタンスとネットワークに関する要件を理解しておく必要があります。重要な留意事項を以下に示します。
-
リソース要件 – ご自分のアプリケーションまたはサービスにはどのようなメモリ要件とプロセッサ要件がありますか? これらの設定を使用すると、使用する DB インスタンスクラスを判断するのに役立ちます。DB インスタンスクラスの仕様については、「DB インスタンスクラス」を参照してください。
-
VPC とセキュリティグループ – DB インスタンスがある可能性が最も高いのは仮想プライベートクラウド (VPC) です。DB インスタンスに接続するには、セキュリティグループルールを設定する必要があります。これらのルールは、使用する VPC の種類と使用方法に応じて設定が異なります。例えば、デフォルト VPC またはユーザー定義の VPC を使用できます。
各 VPC オプションに関するルールを次に説明します。
-
デフォルト VPC — AWS アカウントに現在の AWS リージョンにデフォルト VPC がある場合、その VPC は DB インスタンスをサポートするように設定されています。DB インスタンスを作成する際にデフォルトの VPC を指定する場合は、必ず、アプリケーションまたはサービスから Amazon Timestream for InfluxDB DB インスタンスへの接続を許可する VPC セキュリティグループを作成します。VPC コンソールまたは CLI AWS のセキュリティグループオプションを使用して、VPC セキュリティグループを作成します。詳細については、「ステップ 3: VPC セキュリティグループを作成する」を参照してください。
-
-
ユーザー定義の VPC – DB インスタンスを作成する際にユーザー定義の VPC を指定する場合は、以下の点に注意します。
-
必ず、アプリケーションやサービスから Amazon Timestream for InfluxDB の DB インスタンスへの接続を許可する VPC セキュリティグループを作成します。VPC コンソールまたは CLI AWS のセキュリティグループオプションを使用して、VPC セキュリティグループを作成します。詳細は「ステップ 3: VPC セキュリティグループを作成する」を参照してください。
-
DB インスタンスをホストするには、VPC は特定の要件 (2 つ以上のサブネットを保持しており、各サブネットは個別のアベイラビリティーゾーン内にあることなど) を満たす必要があります。詳細は、「Amazon VPC と Amazon RDS」を参照してください。
-
-
高可用性 – フェイルオーバーのサポートは必要ですか? Amazon Timestream for InfluxDB では、マルチ AZ 配置により、プライマリ DB インスタンスとセカンダリスタンバイ DB インスタンスを別個のアベイラビリティーゾーンに作成することで、フェイルオーバーをサポートしています。本番稼働用のワークロードには、高可用性を維持するためにマルチ AZ 配置をお勧めします。開発およびテストの目的では、マルチ AZ 配置以外のデプロイを使用できます。詳細については、「マルチAZ DB インスタンスのデプロイ」を参照してください。
-
IAM ポリシー — AWS アカウントには、Amazon Timestream for InfluxDB オペレーションの実行に必要なアクセス許可を付与するポリシーがありますか? IAM 認証情報 AWS を使用して に接続する場合、IAM アカウントには、Amazon Timestream for InfluxDB コントロールプレーンオペレーションの実行に必要なアクセス許可を付与する IAM ポリシーが必要です。詳細については、「Amazon Timestream for InfluxDB 向けの Identity and Access Management」を参照してください。
-
開いているポート – データベースでリッスンする TCP/IP ポートはどれですか? 一部の企業のファイアウォールでは、データベースエンジン用のデフォルトポートへの接続がブロックされる場合があります。Timestream for InfluxDB のデフォルトは 8086 です。
-
AWS リージョン — データベースをどの AWS リージョンに配置しますか? アプリケーションやウェブサービスの近くにデータベースを配置すると、ネットワークレイテンシーを低減できます。詳細については、「AWS リージョン および アベイラビリティーゾーン」を参照してください。
-
DB ディスクサブシステム – どのようなストレージ要件がありますか? Amazon Timestream for InfluxDB には、Influx IOPS 込みのストレージタイプ向けに次の 3 つの設定が用意されています。
-
Influx IO 込み 3k IOPS (SSD)
-
Influx IO 込み 12k IOPS (SSD)
-
Influx IO 込み 16k IOPS (SSD)
Amazon Timestream for InfluxDB のストレージの詳細については、「Amazon Timestream for InfluxDB DB インスタンスストレージ」を参照してください。セキュリティグループと DB インスタンスの作成に必要な情報を把握したら、次のステップに進みます。
-
セキュリティグループを作成して VPC 内の DB インスタンスへのアクセスを提供する
VPC セキュリティグループは、VPC 内の DB インスタンスへのアクセスを提供します。セキュリティグループは、関連付けられた DB インスタンスのファイアウォールとして動作し、インバウンドトラフィックとアウトバウンドトラフィックの両方を DB インスタンスレベルで制御します。DB インスタンスはデフォルトでファイアウォールによって作成され、DB インスタンスを保護するデフォルトのセキュリティグループとなります。
DB インスタンスに接続する前に、接続を可能にするルールをセキュリティグループに追加する必要があります。ネットワークと設定に関する情報を使用して、DB インスタンスへのアクセスを許可するルールを作成します。
例えば、アプリケーションから VPC 内にある DB インスタンスのデータベースにアクセスするとします。この場合、カスタム TCP ルールを追加し、アプリケーションからデータベースにアクセスするためのポート範囲と IP アドレスを指定する必要があります。アプリケーションが Amazon EC2 インスタンスにある場合は、Amazon EC2 インスタンスに設定したセキュリティグループを使用できます。
VPC アクセス用セキュリティグループの作成
VPC セキュリティグループを作成するには、 にサインイン AWS マネジメントコンソール し、VPC を選択します。
注記
Amazon Timesteam for InfluxDB のコンソールではなく、必ず VPC のコンソールにサインインします。
-
の右上で AWS マネジメントコンソール、VPC セキュリティグループと DB インスタンスを作成するAWS リージョンを選択します。その AWS リージョンの Amazon VPC リソースのリストには、少なくとも 1 つの VPC と複数のサブネットが表示されます。そうでない場合、その AWS リージョンにデフォルトの VPC はありません。
-
ナビゲーションペインで、[Security Groups] を選択してください。
-
[セキュリティグループの作成] を選択してください。
-
セキュリティグループのページの [基本的な詳細] セクションで、[セキュリティグループ名] と [説明] を入力します。[VPC] で、DB インスタンスの作成先となる VPC を選択します。
-
[Inbound rules] (インバウンドルール) で、[Add rule] (ルールを追加) を選択します。
-
[タイプ] で [カスタム TCP] を選択します。
-
[ソース] でセキュリティグループ名を選択するか、DB インスタンスにアクセスする IP アドレスの範囲 (CIDR 値) を入力します。[マイ IP] を選択すると、ブラウザで検出された IP アドレスから DB インスタンスにアクセスできます。
[Source] (ソース) で、セキュリティグループ名を選択するか、DB インスタンスにアクセスする IP アドレスの範囲 (CIDR 値) を入力します。[マイ IP] を選択すると、ブラウザで検出された IP アドレスから DB インスタンスにアクセスできます。
-
-
(オプション) [Outbound rules] (アウトバウンドルール) で、アウトバウンドトラフィックのルールを追加します。デフォルトではすべてのアウトバウンドトラフィックが許可されます。
-
[セキュリティグループの作成] を選択します。
この VPC セキュリティグループは、DB インスタンスを作成するときにセキュリティグループとして使用できます。
注記
デフォルトの VPC を使用する場合は、すべての VPC のサブネットにまたがるデフォルトのサブネットグループが自動で作成されます。DB インスタンスを作成する場合は、デフォルトの eiifccntf VPC を選択して、DB サブネットグループのデフォルトを選択します。
セットアップに必要なステップが完了したら、ユーザーの要件とセキュリティグループを利用して、DB インスタンスを作成できます。これを行うには、「DB インスタンスの作成」の手順に従います。
Timestream for InfluxDB のセキュリティのベストプラクティス
InfluxDB への書き込みを最適化する
他の時系列データベースと同様に、InfluxDB はデータをリアルタイムで取り込み、処理できるように構築されています。システムのパフォーマンスを最大に保つために、InfluxDB にデータを書き込むときに次の最適化を行うことが推奨されます。
バッチ書き込み: InfluxDB にデータを書き込むときは、データをバッチで書き込んで、すべての書き込みリクエストに関連するネットワークオーバーヘッドを最小限に抑えるようにします。最適なバッチサイズは、書き込みリクエストごとに 5000 行のラインプロトコルです。1 回のリクエストで複数の行を書き込むときは、各行のラインプロトコルを新しい行 (\n) で区切る必要があります。
タグをキーでソートする: InfluxDB にデータポイントを書き込むときは、事前にキーでタグを辞書順にソートします。
measurement,tagC=therefore,tagE=am,tagA=i,tagD=i,tagB=think fieldKey=fieldValue 1562020262 # Optimized line protocol example with tags sorted by key measurement,tagA=i,tagB=think,tagC=therefore,tagD=i,tagE=am fieldKey=fieldValue 1562020262可能な限り最も粗い時間精度を使用する: InfluxDB はナノ秒の精度でデータを書き込みますが、データをナノ秒で収集していない場合はその精度で書き込む必要はありません。パフォーマンスを向上させるには、タイムスタンプに可能な限り最も粗い精度を使用します。書き込み精度は、次の場合に指定できます。
SDK を使用するときは、ポイントの時間属性を設定するときに WritePrecision を指定します。InfluxDB クライアントライブラリの詳細については、InfluxDB ドキュメント
を参照してください。 Telegraf を使用するときは、Telegraf のエージェント設定で時間精度を設定します。精度は、整数と単位 (0s、10ms、2us、4s など) で間隔として指定します。有効な時間単位は、「ns」「us」「ms」「s」です。
[agent] interval ="10s" metric_batch_size="5000" precision = "0s"
gzip 圧縮を使用する: gzip 圧縮を使用して InfluxDB への書き込みを高速化し、ネットワーク帯域幅を減らします。ベンチマークでは、データを圧縮することで速度を最大 5 倍速められることが証明されています。
Telegraf を使用するときは、telegraf.conf の Influxdb_v2 出力プラグイン設定で content_encoding オプションを gzip に設定します。
[[outputs.influxdb_v2]] urls = ["http://localhost:8086"] # ... content_encoding = "gzip"クライアントライブラリを使用するときは、各 InfluxDB クライアントライブラリ
に書き込みリクエストを圧縮するオプションが用意されているか、デフォルトで圧縮が適用されます。圧縮を有効にする方法はライブラリごとに異なります。具体的な手順については、InfluxDB ドキュメント を参照してください。 InfluxDB API
/api/v2/writeエンドポイントを使用してデータを書き込むときは、データを gzip で圧縮し、Content-Encoding ヘッダーを gzip に設定します。
パフォーマンスを考慮して設計する
よりシンプルでパフォーマンスの高いクエリを実現するようにスキーマを設計します。以下のガイドラインに従うことで、スキーマを簡単にクエリできるようになり、クエリのパフォーマンスを最大化できます。
クエリに適した設計: クエリを容易にするメジャーメント
、タグキー 、フィールドキー を選択します。これを達成するには、次の原則に従います。 名前が単純でスキーマを正確に説明しているメジャーメントを使用します。
タグキーとフィールドキーに、予約済みの Flux キーワード
と特殊文字を使用しないようにします。 タグは、フィールドを説明していて多くのデータポイントに共通するメタデータを保存します。
フィールドには、一意のデータまたは非常に変わりやすいデータ、通常は数値のデータポイントが保存されます。
メジャーメントとキーにはデータを含めることはできませんが、データを集約または説明するために使用されます。データはタグ値とフィールド値に保存されます。
時系列カーディナリティをコントロールする: 系列カーディナリティが高いことは、InfluxDB の書き込みおよび読み取りパフォーマンスを低下させる主な原因となります。InfluxDB の文脈では、高カーディナリティとは一意のタグ値が非常に多く存在することを意味します。タグ値は InfluxDB でインデックス化されます。つまり、一意の値の数が非常に多いと、より大きなインデックスが生成され、データインジェストおよびクエリのパフォーマンスが低下する可能性があります。
高カーディナリティに関連する潜在的問題を深く理解して解決するには、次のステップに従います。
高カーディナリティの原因を理解する
バケットのカーディナリティを測定する
高カーディナリティの対応策をとる
系列カーディナリティが高くなる原因: InfluxDB は、メジャーメントとタグに基づいてデータのインデックスを作成し、データの読み取りを高速化します。インデックス付きのデータ要素のセットは、それぞれ系列キー
を構成します。一意の ID、ハッシュ、ランダム文字列といった非常に変わりやすい情報を含むタグ は、多数の系列 、つまり高い系列カーディナリティ を引き起こす原因となります。系列カーディナリティが高いことは、InfluxDB のメモリ使用率が増加する主な要因です。 系列カーディナリティの測定: Timestream for InfluxDB インスタンスでパフォーマンスが低下したり、メモリ使用率が増加し続けたりしている場合は、バケットの系列カーディナリティを測定することが推奨されます。
InfluxDB には、Flux と InfluxQL の両方で系列カーディナリティを測定できる関数が用意されています。
Flux では関数
influxdb.cardinality()を使用FluxQL では
SHOW SERIES CARDINALITYコマンドを使用
どちらの場合も、エンジンはデータ内に存在する一意の系列キーの数を返します。1,000 万を超える系列キーを持つことはいずれの Timestream for InfluxDB インスタンスにも推奨されません。
系列カーディナリティが高くなる原因: いずれかのバケットのカーディナリティが高い場合は、いくつかの是正措置を取ることで修正できます。
タグを確認する: ワークロードによって、ほとんどのエントリでタグに一意の値があるケースが生成されていないことを確認します。これは、一意のタグ値の数が時間の経過とともに増加するケースや、ログタイプのメッセージがデータベースに書き込まれ、すべてのメッセージにタイムスタンプやタグなどの一意の組み合わせが含まれている場合に起きる可能性があります。次の Flux コードは、どのタグが、カーディナリティが高くなる問題の一番の原因となっているかを突き止めるのに役立ちます。
// Count unique values for each tag in a bucketimport "influxdata/influxdb/schema" cardinalityByTag = (bucket) => schema.tagKeys(bucket: bucket) |> map( fn: (r) => ({ tag: r._value, _value: if contains(set: ["_stop", "_start"], value: r._value) then 0 else (schema.tagValues(bucket: bucket, tag: r._value) |> count() |> findRecord(fn: (key) => true, idx: 0))._value, }), ) |> group(columns: ["tag"]) |> sum() cardinalityByTag(bucket: "amzn-s3-demo-bucket")カーディナリティが非常に高い場合、上記のクエリがタイムアウトすることがあります。タイムアウトが発生した場合は、次のクエリを一度に 1 つずつ実行します。
タグのリストを生成します。
// Generate a list of tagsimport "influxdata/influxdb/schema" schema.tagKeys(bucket: "amzn-s3-demo-bucket")各タグの一意のタグ値をカウントします。
// Run the following for each tag to count the number of unique tag valuesimport "influxdata/influxdb/schema" tag = "example-tag-key" schema.tagValues(bucket: "amzn-s3-demo-bucket1", tag: tag) |> count()これらを異なる時点で実行し、増えるスピードが最も速いタグはどれかを突き止めることが推奨されます。
スキーマを改善する: 「Timestream for InfluxDB のセキュリティのベストプラクティス」で説明したモデリングの推奨事項に従います。
古いデータを削除または集計してカーディナリティを減らす: カーディナリティが高くなる原因となっているデータのすべてが、ユースケースに必要かどうか検討します。データがもはや不要だったり、あるいは頻繁にアクセスしたりしている場合は、集約または削除するか、長期保存および分析を行うために Timestream for LiveAnalytics などの別のエンジンにエクスポートします。
