Amazon Timestream for LiveAnalytics に類似した機能をご希望の場合は Amazon Timestream for InfluxDB をご検討ください。リアルタイム分析に適した、シンプルなデータインジェストと 1 桁ミリ秒のクエリ応答時間を特徴としています。詳細については、こちらを参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Timestream for InfluxDB のマルチ AZ リードレプリカクラスターの操作
リードレプリカクラスターのデプロイは、Amazon Timestream for InfluxDB の非同期のデプロイモードであり、プライマリ DB インスタンスにアタッチされたリードレプリカを設定することができます。リードレプリカクラスターには、同じ AWS リージョンにある別個のアベイラビリティーゾーンに、ライター DB インスタンスとリーダー DB インスタンスが 1 つずつあります。リードレプリカクラスターは、マルチ AZ DB インスタンス配置に比べると可用性が高く、読み取りワークロードの容量も多くなっています。
リードレプリカクラスターで利用できるインスタンスクラス
リードレプリカクラスターのデプロイは、通常の Timestream for InfluxDB インスタンスと同じインスタンスタイプでサポートされています。
| インスタンスクラス | vCPU | メモリ (GiB) | ストレージタイプ | ネットワーク帯域幅 (Gbps) |
|---|---|---|---|---|
| db.influx.medium | 1 | 8 | Influx IOPS 込み | 10 |
| db.influx.large | 2 | 16 | Influx IOPS 込み | 10 |
| db.influx.xlarge | 4 | 32 | Influx IOPS 込み | 10 |
| db.influx.2xlarge | 8 | 64 | Influx IOPS 込み | 10 |
| db.influx.4xlarge | 16 | 128 | Influx IOPS 込み | 10 |
| db.influx.8xlarge | 32 | 256 | Influx IOPS 込み | 12 |
| db.influx.12xlarge | 48 | 384 | Influx IOPS 込み | 20 |
| db.influx.16xlarge | 64 | 512 | Influx IOPS 込み | 25 |
| db.influx.24xlarge | 96 | 768 | Influx IOPS 込み | 40 |
リードレプリカクラスターのアーキテクチャ
リードレプリカクラスターでは、Amazon Timestream for InfluxDB は、InfluxData のライセンスされたリードレプリカアドオンを使用して、ライター DB インスタンスに対して行われたすべての書き込みを、すべてのリーダー DB インスタンスに自動的にレプリケートします。このレプリケーションは非同期であり、すべての書き込みは、ライターノードによってコミットされるとすぐに確認されます。すべてのリーダーノードからの確認がなくとも、書き込みは成功したとみなされます。データが書き込み DB インスタンスによってコミットされると、ほぼ瞬時にリードレプリカインスタンスにレプリケートされます。回復可能なライター障害が発生した場合、データは 1 つ以上のリーダーにレプリケートされていなければ失われます。
リードレプリカインスタンスは、ライター DB インスタンスの読み取り専用コピーです。クエリの一部または全部をアプリケーションからリードレプリカにルーティングすることで、ライター DB インスタンスの負荷を軽減できます。こうすることにより、単一 DB インスタンスの容量制約にとらわれることなく伸縮自在にスケールアウトし、読み取り負荷の高いデータベースワークロードに対応できます。
次の図は、プライマリ DB インスタンスが別のアベイラビリティーゾーンのリードレプリカにレプリケートされる様子を示しています。クライアントにはプライマリ DB インスタンスへの読み取り/書き込みアクセス権、およびレプリカへの読み取り専用アクセス権があります。
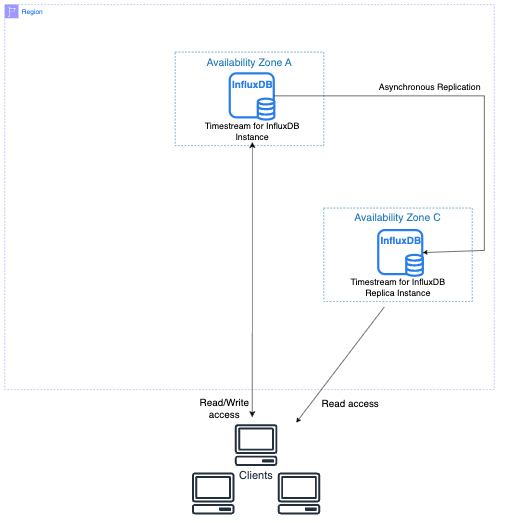
リードレプリカクラスターのパラメータグループ
リードレプリカクラスターでは、DB パラメータグループは、リードレプリカクラスター内のすべての DB インスタンスに適用される、エンジン設定値のコンテナとして機能します。デフォルトの DB パラメータグループは、DB エンジンと DB エンジンのバージョンに基づいて設定されます。DB パラメータグループの設定は、クラスター内のすべての DB インスタンスに使用されます。
マルチ AZ DB リードレプリカ用の CreateDbCluster または UpdateDbCluster を使用して特定の DB パラメータグループを渡すときは、storage-wal-max-write-delay が 1 時間以上に設定されていることを確認します。DB パラメータグループが指定されていない場合、storage-wal-max-write-delay はデフォルトで 1 時間になります。
リードレプリカクラスターのレプリカラグ
Timestream for InfluxDB のリードレプリカクラスターでは高い書き込みパフォーマンスが得られますが、エンジンベースの非同期レプリケーションの性質上、レプリカラグが発生することがあります。この遅延によりフェイルオーバーの際にデータが失われる可能性があるため、モニタリングが不可欠です。
AWS マネジメントコンソール ナビゲーションペインですべてのメトリクスを選択すると、CloudWatch からレプリカの遅延を追跡できます。[Timestream/InfluxDB] を選択し、次に [DbCluster から] を選択します。[DbClusterName] を選択し、次に [DbReaderInstanceName] を選択します。ここには、Timestream for InfluxDB のすべてのインスタンスで追跡される通常のメトリクスセット (以下のリストを参照) に加え、ミリ秒単位で表される ReplicaLag も表示されます。
CPUUtilization
MemoryUtilization
DiskUtilization
ReplicaLag (レプリカインスタンスモードの DB インスタンスのみ)
レプリカの遅延の一般的な原因
レプリカラグは一般に、書き込みと読み取りのワークロード負荷が高すぎて、リーダー DB インスタンスがトランザクションを効率的に適用できない場合に起こります。異なるワークロードでは、一時的に、または継続的にレプリカの遅延が発生する可能性があります。一般的な原因の例をいくつか次に示します。
書き込みの同時実行性が高いか、ライター DB インスタンスで大量のバッチ更新が行われるため、リーダー DB インスタンスの適用プロセスが遅れている。
1 つ以上のリーダー DB インスタンスでリソースを使用しており、読み取りワークロード負荷が高い。低速または大規模なクエリを実行すると、適用プロセスに影響し、レプリカの遅延が発生する可能性があります。
大量のデータまたは DDL ステートメントを変更するトランザクション。データベースのコミットの順序を保持する必要があるため、レプリカの遅延が一時的に増加することがあります。
レプリカの遅延が設定された時間を超過した際に CloudWatch アラームを作成する方法のチュートリアルについては、「チュートリアル: Amazon Timestream for InfluxDB 向けマルチ AZ クラスターレプリカラグ用 Amazon CloudWatch アラームの作成」を参照してください。
レプリカの遅延の軽減
Timestream for InfluxDB のリードレプリカクラスターの場合、ライター DB インスタンスの負荷を減らすことでレプリカラグを軽減できます。
可用性と耐久性
リードレプリカクラスターは、書き込みの可用性を優先するために書き込み障害が発生した場合にリーダーインスタンスのいずれかに自動的にフェイルオーバーするように設定するか、またはフェイルオーバーを回避してチップデータの損失を最小限に抑えるように設定することが可能です。チップデータとは、1 つ以上のリーダーノードにまだレプリケートされていないデータのレプリケーションギャップのことです (「リードレプリカクラスターのレプリカラグ」を参照)。リードレプリカクラスターのデフォルトの動作および推奨される動作は、書き込み障害が発生した場合に自動的にフェイルオーバーすることです。ただし、チップデータの損失がユースケースにおける書き込み可用性よりも重要である場合は、クラスターを更新することでデフォルトを上書きできます。
リードレプリカクラスターは、アベイラビリティーゾーンが停止した場合、書き込み可用性とデータ耐久性とを高めるために、クラスターのすべての DB インスタンスが 2 つ以上のアベイラビリティーゾーンに分散されるようにします。
トピック
