Amazon Timestream for LiveAnalytics に類似した機能をご希望の場合は Amazon Timestream for InfluxDB をご検討ください。リアルタイム分析に適した、シンプルなデータインジェストと 1 桁ミリ秒のクエリ応答時間を特徴としています。詳細については、こちらを参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
シンプルなフリートレベルの集計
この最初の例では、フリートレベルの集計を計算するシンプルな例を使用して、スケジュールされたクエリを使用する際の基本概念をいくつか説明します。この例を使用して、以下を理解します。
-
集計統計を取得してスケジュールされたクエリにマッピングするために使用されるダッシュボードクエリの取得方法。
-
Timestream for LiveAnalytics が、スケジュールされたクエリのさまざまなインスタンスの実行を管理する仕組み。
-
スケジュールされたクエリのさまざまなインスタンスの時間範囲を重複させる方法と、スケジュールされたクエリの結果を使用するダッシュボードが未加工のデータで計算された同じ集計と一致する結果を提供するように、ターゲットテーブルでデータの正確性を維持する方法。
-
スケジュールされたクエリの時間範囲と更新間隔の設定方法。
-
スケジュールされたクエリの結果をセルフサービスで追跡して調整し、クエリインスタンスの実行レイテンシーをダッシュボード更新の許容可能な遅延内に収める方法。
ソーステーブルからの集計
この例では、特定のリージョン内のサーバーから発行される 1 分ごとのメトリクスの数を追跡しています。下のグラフは、us-east-1 リージョンにおけるこの時系列のプロット例です。
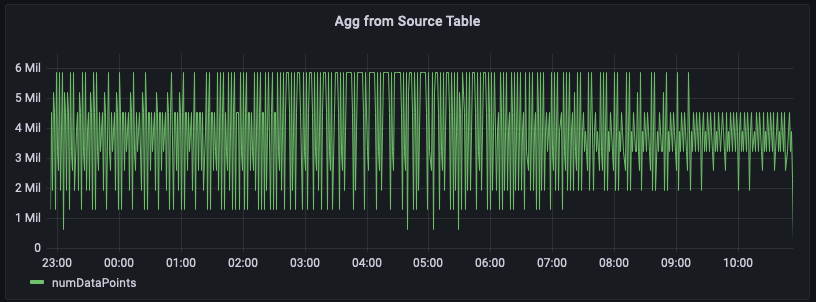
以下は、未加工のデータからこの集計を計算するクエリの例です。us-east-1 リージョンの行をフィルタリングし、20 個のメトリクス (measure_name がメトリクスの場合) または 5 個のイベント (measure_name がイベントの場合) を織り込んで 1 分ごとの合計を計算します。この例では、発行されるメトリクスの数が 1 分あたり 150 万~600 万であることをグラフが示しています。この時系列を一定時間 (この図では過去 12 時間) プロットすると、未加工のデータに対するこのクエリでは数億行が分析されます。
WITH grouped_data AS ( SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY region, measure_name, bin(time, 1m) ) SELECT minute, SUM(numDataPoints) AS numDataPoints FROM grouped_data GROUP BY minute ORDER BY 1 desc, 2 desc
スケジュールされたクエリによる集計の事前計算
ダッシュボードを最適化してスキャンするデータを減らすことでロードを高速化し、コストを削減するために、スケジュールされたクエリを使用してこれらの集計を事前計算できます。Timestream for LiveAnalytics のスケジュールされたクエリでは、これらの事前計算を別の Timestream for LiveAnalytics テーブルでマテリアライズし、後でダッシュボードに使用できます。
スケジュールされたクエリを作成するための最初のステップは、事前計算するクエリの特定です。前述のダッシュボードは、us-east-1 リージョン用に作成されました。ただし、別のユーザーが us-west-2 や eu-west-1 などの別のリージョンで同じ集計を必要とする場合があります。スケジュールされたクエリがこのようなクエリごとに作成されないようにするため、各リージョンの集計を事前に計算し、リージョンごとの集計を別の Timestream for LiveAnalytics テーブルにマテリアライズできます。
以下のクエリは、対応する事前計算の例を示しています。ご覧のように、これは未加工のデータのクエリで使用される一般的なテーブル式 grouped_data に似ていますが、違いが 2 つあります。1) リージョン述語を使用しないため、1 つのクエリをすべてのリージョンの事前計算に使用できます。2) パラメータ化された時間述語と、以下で詳しく説明する特別なパラメータ @scheduled_runtime を使用します。
SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region
上のクエリは、次の仕様を使用してスケジュールされたクエリに変換できます。スケジュールされたクエリには、わかりやすいニーモニックである名前が割り当てられます。これには QueryString と、cron 式 の ScheduleConfiguration が含まれます。これにより、クエリ結果を Timestream for LiveAnalytics の送信先テーブルにマッピングする TargetConfiguration が指定されます。最後に、その他多くの設定が指定されます。これには、クエリの個々の実行に対して通知が送信される NotificationConfiguration、クエリでエラーが発生した場合にレポートが書き込まれる ErrorReportConfiguration、スケジュールされたクエリのオペレーションを実行するために使用されるロールである ScheduledQueryExecutionRoleArn などが含まれます。
{ "Name": "MultiPT5mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/5 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt5m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
この例では、ScheduleExpression cron(0/5 * * ? *) は、クエリが毎日 5 分ごと (各時の 5 分、10 分、15 分、以下同様) に 1 回実行されることを意味します。当該クエリの特定のインスタンスがトリガーされる時点を示すこれらのタイムスタンプは、クエリで使用される @scheduled_runtime パラメータに変換されます。例えば、2021-12-01 00:00:00 にこのスケジュールされたクエリのインスタンスを実行するとします。この場合、クエリを呼び出すと、@scheduled_runtime パラメータはタイムスタンプ 2021-12-01 00:00:00 に初期化されます。したがって、このインスタンスはタイムスタンプ 2021-12-01 00:00:00 に実行され、時間範囲 2021-11-30 23:50:00~2021-12-01 00:01:00 の毎分の集計を計算します。同様に、当該クエリの次のインスタンスがタイムスタンプ 2021-12-01 00:05:00 にトリガーされると、クエリは時間範囲 2021-11-30 23:55:00~2021-12-01 00:06:00 の毎分の集計を計算します。そのため、@scheduled_runtime パラメータは、クエリの呼び出し時間を使用して、設定された時間範囲の集計を事前計算するスケジュールされたクエリを提供します。
クエリの 2 つの後続インスタンスは、時間範囲が重複します。これを要件に基づいて制御できます。この場合、この重複により、これらのクエリでは到着がわずかに (この例では最大 5 分) 遅延したデータに基づいて集計を更新できます。マテリアライズされたクエリの正確性を確保するために、Timestream for LiveAnalytics は、2021-12-01 00:00:00 のクエリが完了した後にのみ 2021-12-01 00:05:00 のクエリが実行され、後者のクエリの結果は新しい値が生成された場合に事前にマテリアライズされた集計を更新できるようにします。例えば、2021-12-01 00:00:00 のクエリの実行後、2021-12-01 00:05:00 のクエリの前にタイムスタンプ 2021-11-30 23:59:00 のデータが到着した場合、2021-12-01 00:05:00 の実行によって 2021-11-30 23:59:00 の集計が再計算され、以前の集計が新たに計算された値で更新されます。スケジュールされたクエリのこれらのセマンティクスに基づいて、事前計算の更新速度と、到着が遅れたデータの適切な処理のバランスを取ることができます。更新頻度とデータ鮮度のバランスをどのように取るか、およびデータがさらに遅れて到着した場合や、スケジュールされた計算のソースによって値が更新され、集計を再計算する必要がある場合に集計をどのように更新するかについては、以下で説明しています。
スケジュールされた計算にはそれぞれ通知設定があり、Timestream for LiveAnalytics はスケジュールされた設定が実行されるたびに通知を送信します。呼び出しごとに通知を受信するよう SNS トピックを設定できます。特定のインスタンスの成功または失敗ステータスに加えて、この計算の実行にかかった時間、スキャンされた計算のバイト数、計算によって送信先テーブルに書き込まれたバイト数など、いくつかの統計も提供されます。これらの統計は、クエリのより細かい調整、設定のスケジュール、スケジュールされたクエリの支出追跡に使用できます。注意すべき統計として、インスタンスの実行時間があります。この例では、スケジュールされた計算は 5 分ごとに実行されるように設定されています。実行時間によって、事前計算が可能になる遅延が決定され、ダッシュボードで事前計算済みのデータを使用している場合の遅延も定義されます。さらに、この遅延が更新間隔よりも一貫して長い場合 (例えば、更新間隔 5 分に設定された計算の実行時間が 5 分を超える場合) は、ダッシュボードでさらなる遅延を避けるために、計算を調整して実行速度を高めることが重要です。
派生テーブルからの集計
スケジュールされたクエリを設定し、集計が事前に計算され、スケジュールされた計算のターゲット設定で指定された別の Timestream for LiveAnalytics テーブルにマテリアライズされたので、そのテーブルのデータを使用して SQL クエリを書き込み、ダッシュボードで活用できます。以下は、マテリアライズされた事前集計を使用して、us-east-1 の毎分のデータポイント数集計を生成するクエリです。
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY bin(time, 1m) ORDER BY 1 desc
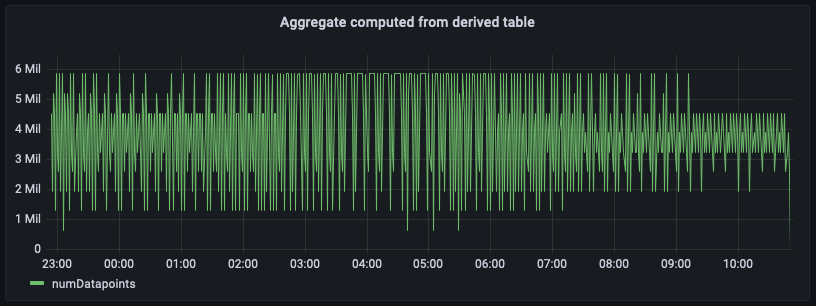
上の画像は、集計テーブルから計算された集計をプロットしたものです。このパネルを未加工のソースデータから計算されたパネルと比較すると、正確に一致しています。これらの集計は数分遅延し、スケジュールされた計算に設定した更新間隔とその実行時間によって制御されますが、その影響はありません。
事前計算されたデータに対するこのクエリは、未加工のソースデータに対して計算された集計と比較すると、スキャンするデータの量が大幅に少なくなります。集計の詳細度によっては、このデータ量の減少により、コストとクエリレイテンシーが 100 分の 1 以下になる可能性があります。このスケジュールされた計算の実行にはコストがかかります。しかし、これらのダッシュボードの更新頻度と、ロードする同時ユーザーの数によっては、これらの事前計算を使用することで全体のコストを大幅に削減できます。また、ダッシュボードのロード時間も 10 分の 1~100 分の 1 に短縮できます。
ソーステーブルと派生テーブルを組み合わせた集計
派生テーブルを使用して作成されたダッシュボードでは、遅延が生じる可能性があります。ダッシュボードで最新のデータが必要とされるアプリケーションシナリオでは、Timestream for LiveAnalytics の SQL サポートの力と柔軟性を利用して、ソーステーブルの最新データと派生テーブルの履歴集計を組み合わせ、マージされたビューを作成できます。このマージされたビューでは、SQL のユニオンセマンティクスと、ソーステーブルと派生テーブルの重複しない時間範囲が使用されます。下の例では、"derived"."per_minute_aggs_pt5m" 派生テーブルを使用しています。この派生テーブルのスケジュールされた計算は、(スケジュール式の仕様に従って) 5 分おきに更新されます。そのため、下のクエリは、ソーステーブルの最近 15 分のデータと、派生テーブルの 15 分以上経過したデータを使用し、結果を結合して、両者の長所を併せ持つマージされたビューを作成します。一方の長所は派生テーブルから事前計算された古い集計を読み取ることによる経済性と低レイテンシー、もう一方の長所はリアルタイム分析のユースケースに活用できるソーステーブルからの集計の鮮度です。
このユニオンアプローチは、派生テーブルのみをクエリする場合と比較するとクエリレイテンシーはわずかに大きく、スキャンされるデータはわずかに多くなります。これは、最新の時間間隔の未加工データをリアルタイムで集計するためです。ただし、このマージされたビューは、特に数日または数週間のデータをレンダリングするダッシュボードの場合、ソーステーブルから即時に集計するよりもはるかに高速かつ低コストです。この例の時間範囲は、アプリケーションの更新ニーズと遅延許容度に応じて調整できます。
WITH aggregated_source_data AS ( SELECT bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDatapoints FROM "raw_data"."devops" WHERE time BETWEEN bin(from_milliseconds(1636743196439), 1m) - 15m AND from_milliseconds(1636743196439) AND region = 'us-east-1' GROUP BY bin(time, 1m) ), aggregated_derived_data AS ( SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996439) AND bin(from_milliseconds(1636743196439), 1m) - 15m AND region = 'us-east-1' GROUP BY bin(time, 1m) ) SELECT minute, numDatapoints FROM ( ( SELECT * FROM aggregated_derived_data ) UNION ( SELECT * FROM aggregated_source_data ) ) ORDER BY 1 desc
下は、この統合マージビューのダッシュボードパネルです。ご覧のとおり、ダッシュボードは、右端に最新の集計がある点を除いて、派生テーブルから計算されたビューとほぼ同じです。
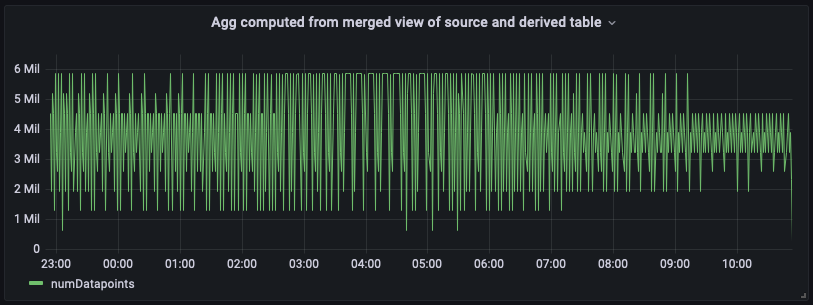
頻繁に更新されるスケジュールされた計算からの集計
ダッシュボードがロードされる頻度とダッシュボードに求めるレイテンシーによっては、ダッシュボードでより新しい結果を取得するための別のアプローチとして、スケジュールされた計算での集計の更新頻度を高めることができます。例えば、下は毎分更新される点のみが異なる同じスケジュールされた計算の設定です (スケジュール式 cron(0/1 * * * ? *))。この設定では、計算で 5 分おきの更新スケジュールが指定されたシナリオと比較して、派生テーブル per_minute_aggs_pt1m の集計の鮮度が大幅に向上します。
{ "Name": "MultiPT1mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/1 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt1m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt1m" WHERE time BETWEEN from_milliseconds(1636699996446) AND from_milliseconds(1636743196446) AND region = 'us-east-1' GROUP BY bin(time, 1m), region ORDER BY 1 desc
派生テーブルの集計がより新しくなるため、前のクエリと下のダッシュボードスナップショットからわかるように、派生テーブル per_minute_aggs_pt1m の直接クエリによってより新しい集計を取得できるようになります。
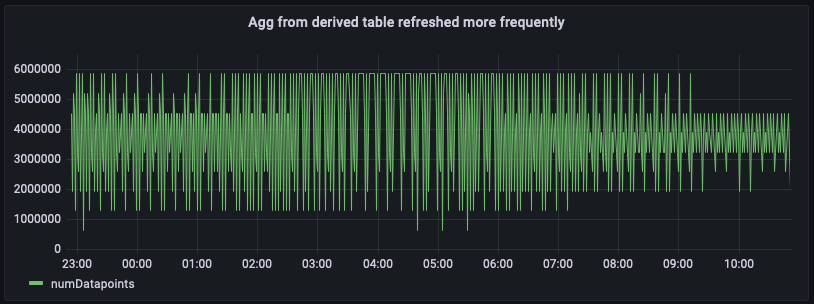
スケジュールされた計算の更新頻度を (例えば 5 分おきから 1 分おきに) 増やすと、スケジュールされた計算のメンテナンスコストが上昇することに注意してください。各計算の実行に関する通知メッセージにより、スキャンされたデータと、派生テーブルに書き込まれたデータの量の統計が提供されます。また、マージされたビューを使用して派生テーブルを結合する場合、マージされたビューのクエリコストとダッシュボードのロードレイテンシーは、派生テーブルのみをクエリする場合と比較して増大します。したがって、選択するアプローチは、ダッシュボードの更新頻度とスケジュールされたクエリのメンテナンスコストに応じて変化します。何十人ものユーザーがダッシュボードを毎分などの頻度で更新している場合、派生テーブルの更新頻度を高めると、全体的なコストが低下する可能性があります。
