Amazon Timestream for LiveAnalytics に類似した機能をご希望の場合は Amazon Timestream for InfluxDB をご検討ください。リアルタイム分析に適した、シンプルなデータインジェストと 1 桁ミリ秒のクエリ応答時間を特徴としています。詳細については、こちらを参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
スケジュールされたクエリをダッシュボード間で共有してコストを最適化する
この例では、複数のダッシュボードパネルに類似情報のバリエーション (CPU 使用率の高いホストと CPU 使用率の高いフリートの割合) が表示されるシナリオと、同じスケジュールされたクエリを使用して結果を事前計算し、複数のパネルの入力に使用する方法が示されています。この再利用により、パネルごとに異なるスケジュールされたクエリを使用する代わりに、所有者のみを使用することになり、コストがさらに最適化されます。
未加工データを含むダッシュボードパネル
マイクロサービスごとのリージョン別 CPU 使用率
最初のパネルは、リージョン、セル、サイロ、アベイラビリティーゾーン、マイクロサービス内の特定のデプロイについて、平均 CPU 使用率が上記の CPU 使用率より低いまたは高いしきい値であるインスタンスを計算します。次に、使用率の高いホストの割合が最も高いリージョンとマイクロサービスをソートします。これにより、特定のデプロイにおけるサーバーの稼働状況を特定した後、ドリルダウンして問題をより詳細に把握できます。
パネルのクエリは、一般的なテーブル式、ウィンドウ関数、結合などを使用して複雑な分析タスクを実行できる Timestream for LiveAnalytics の SQL サポートの柔軟性を示しています。

クエリ:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization) * 100.0 / COUNT(*), 0) AS percent_low_utilization_hosts FROM instances_above_threshold GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
マイクロサービスへのドリルダウンによるホットスポットの特定
次のダッシュボードでは、いずれかのマイクロサービスをより深く掘り下げて、その特定のリージョン、セル、サイロによるフリートでの CPU 使用率が高い部分を特定できます。例えば、フリート全体のダッシュボードでは上位数位にマイクロサービス demeter が表示されていたため、このダッシュボードではそのマイクロサービスをより深く掘り下げます。
このダッシュボードでは、変数を使用してドリルダウンするマイクロサービスを選択します。変数の値は、ディメンションの一意の値を使用して入力されます。マイクロサービスを選択すると、ダッシュボードの残りの部分が更新されます。
以下に示すように、最初のパネルにはデプロイ (マイクロサービスのリージョン、セル、サイロ) 内のホストの割合が経時的にプロットされます。対応するクエリは、ダッシュボードのプロットに使用されます。このプロット自体は、CPU 使用率が高くなっているホストの割合が高い特定のデプロイを識別します。

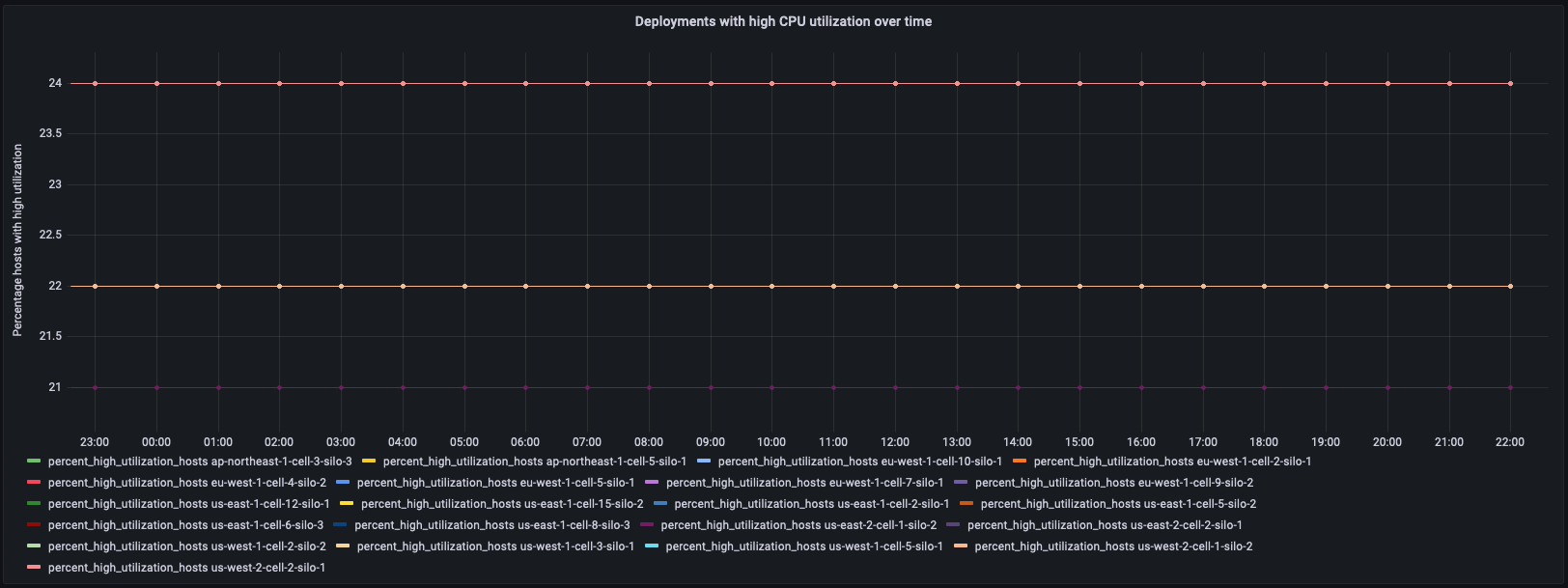
クエリ:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ), high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
再利用を可能にする単一のスケジュールされたクエリへの変換
2 つのダッシュボードの異なるパネルで類似する計算が行われることが重要です。パネルごとに、スケジュールされたクエリを個別に定義できます。ここでは、3 つのパネルすべてをレンダリングするために結果を使用できる単一のスケジュールされたクエリを定義することで、コストをさらに最適化する方法を説明します。
以下は、計算され、すべての異なるパネルに使用される集計をキャプチャするクエリです。このスケジュールされたクエリの定義には、いくつかの重要な要素があります。
-
スケジュールされたクエリでサポートされる SQL サーフェス領域の柔軟性と能力。一般的なテーブル式、結合、CASE ステートメントなどを使用できます。
-
1 つのスケジュールされたクエリを使用して、特定のダッシュボードで求められるよりも高い詳細度で、またダッシュボードがさまざまな変数に使用する可能性のあるすべての値について、統計を計算できます。例えば、リージョン、セル、サイロ、マイクロサービス全体で集計が計算されます。したがって、これらを組み合わせて、リージョンレベル (リージョン) およびマイクロサービスレベルの集計を作成できます。同様に、同じクエリですべてのリージョン、セル、サイロ、マイクロサービスの集計が計算されます。これにより、これらの列にフィルターを適用して、値のサブセットの集計を取得できます。例えば、いずれかのリージョン (us-east-1 など) やマイクロサービス (demeter など) の集計を計算したり、リージョン、セル、サイロ、マイクロサービス内の特定のデプロイにドリルダウンしたりできます。このアプローチにより、事前計算された集計のメンテナンスコストがさらに最適化されます。
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour
以下は、上のクエリのスケジュールされたクエリ定義です。スケジュール式は 30 分ごとに更新するように設定されており、再び bin(@scheduled_runtime, 1h) コンストラクトを使用して最大 1 時間前までのデータを更新します。アプリケーションの鮮度要件に応じて、設定により更新頻度を変更できます。WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h を使用することで、15 分おきに更新する場合でも、最新の 1 時間分とその前の 1 時間分、データを取得できます。
後ほど、3 つのパネルでテーブル deployment_cpu_stats_per_hr に書き込まれたこれらの集計を使用して、パネルに関連するメトリクスを視覚化する方法を説明します。
{ "Name": "MultiPT30mHighCpuDeploymentsPerHr", "QueryString": "WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/30 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "deployment_cpu_stats_per_hr", "TimeColumn": "hour", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" }, { "Name": "cell", "DimensionValueType": "VARCHAR" }, { "Name": "silo", "DimensionValueType": "VARCHAR" }, { "Name": "microservice_name", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "cpu_user", "MultiMeasureAttributeMappings": [ { "SourceColumn": "num_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "high_utilization_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "low_utilization_hosts", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
事前計算された結果のダッシュボード
CPU 使用率の高いホスト
使用率の高いホストについて、複数のパネルで deployment_cpu_stats_per_hr のデータを使用して、それぞれ異なる必要な集計を計算する方法を説明します。例えば、このパネルではリージョンレベルの情報が提供されるため、リージョンやマイクロサービスをフィルタリングすることなく、リージョン別やマイクロサービス別にグループ化された集計がレポートされます。
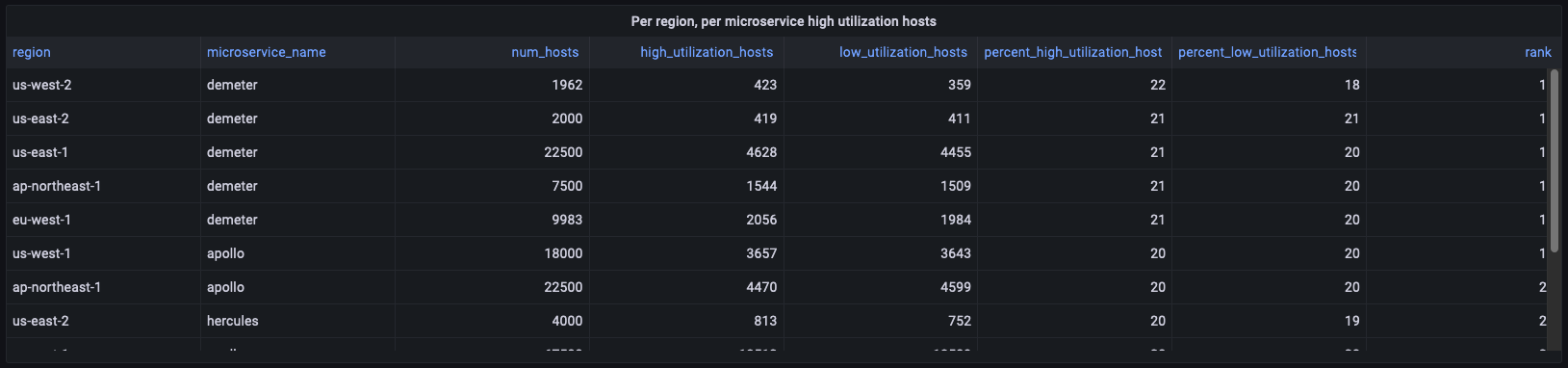
WITH per_deployment_hosts AS ( SELECT region, cell, silo, microservice_name, AVG(num_hosts) AS num_hosts, AVG(high_utilization_hosts) AS high_utilization_hosts, AVG(low_utilization_hosts) AS low_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636567785437) AND from_milliseconds(1636654185437) AND measure_name = 'cpu_user' GROUP BY region, cell, silo, microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, SUM(num_hosts) AS num_hosts, ROUND(SUM(high_utilization_hosts), 0) AS high_utilization_hosts, ROUND(SUM(low_utilization_hosts),0) AS low_utilization_hosts, ROUND(SUM(high_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_low_utilization_hosts FROM per_deployment_hosts GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
マイクロサービスへのドリルダウンによる CPU 使用率の高いデプロイの特定
次の例でも派生テーブル deployment_cpu_stats_per_hr を使用しますが、ここでは集計ダッシュボードで使用率の高いホストがレポートされたマイクロサービス demeter のフィルターを適用しています。このパネルでは、CPU 使用率の高いホストの割合を経時的に追跡しています。
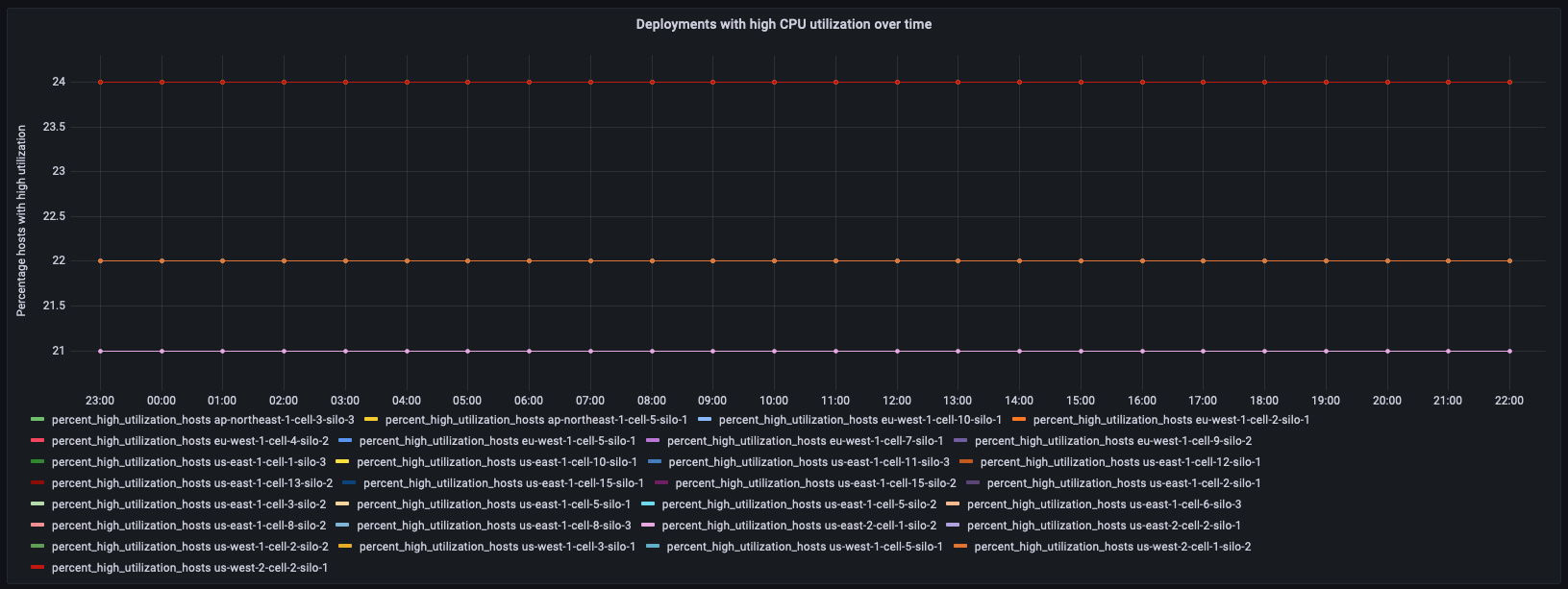
WITH high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, bin(time, 1h) AS hour, MAX(num_hosts) AS num_hosts, MAX(high_utilization_hosts) AS high_utilization_hosts, ROUND(MAX(high_utilization_hosts) * 100.0 / MAX(num_hosts)) AS percent_high_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636525800000) AND from_milliseconds(1636612200000) AND measure_name = 'cpu_user' AND microservice_name = 'demeter' GROUP BY region, cell, silo, microservice_name, bin(time, 1h) ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
