Amazon Timestream for LiveAnalytics に類似した機能をご希望の場合は Amazon Timestream for InfluxDB をご検討ください。リアルタイム分析に適した、シンプルなデータインジェストと 1 桁ミリ秒のクエリ応答時間を特徴としています。詳細については、こちらを参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon Timestream でのデータアクセスの最適化
Timestream パーティショニングスキームまたはデータ整理手法を使用して、Amazon Timestream のデータアクセスパターンを最適化できます。
Timestream パーティショニングスキーム
Amazon Timestream は、スケーラビリティに優れたパーティショニングスキームを使用します。各 Timestream テーブルには、数百、数千、さらには数百万の独立したパーティションを含めることができます。可用性の高いパーティション追跡およびインデックス作成サービスで、パーティショニングを管理し、障害の影響を最小限に抑え、システムの回復力を向上させます。
データの整理
Timestream は、取り込む各データポイントを単一のパーティションに保存します。Timestream テーブルにデータを取り込むと、Timestream はデータ内のタイムスタンプ、パーティションキー、およびその他のコンテキスト属性に基づいてパーティションを自動的に作成します。Timestream は、データを時間どおりにパーティショニングする (時間パーティショニング) だけでなく、選択したパーティショニングキーやその他のディメンション (空間パーティショニング) に基づいてデータをパーティショニングします。このアプローチは、書き込みトラフィックを分散し、クエリのデータを効果的にプルーニングできるように設計されています。
クエリインサイト機能は、クエリのプルーニング効率に関する貴重なインサイトを提供します。これには、クエリ空間カバレッジとクエリ時間カバレッジが含まれます。
QuerySpatialCoverage
QuerySpatialCoverage メトリクスは、実行されたクエリの空間カバレッジと最も非効率的な空間プルーニングのテーブルに関するインサイトを提供します。この情報は、空間プルーニングを強化するためのパーティショニング戦略の改善領域を特定するのに役立ちます。QuerySpatialCoverage メトリクスの値は 0~1 の範囲です。メトリクスの値が低いほど、空間軸でのクエリプルーニングが適切になります。例えば、値 0.1 は、クエリが空間軸の 10% をスキャンすることを示します。値 1 は、クエリが空間軸の 100% をスキャンすることを示します。
例クエリインサイトを使用してクエリの空間カバレッジを分析する
気象データを保存する Timestream データベースがあるとします。米国のさまざまな州にある気象観測所から気温が毎時記録されると想定します。ユーザー定義のパーティショニングキー (CDPK) として State を選択し、州ごとにデータをパーティション化するとします。
クエリを実行して、特定の日の午後 2 時~午後 4 時の間、カリフォルニア州の気象観測所すべての平均気温を取得するとします。このシナリオのクエリは、次の例のようになります。
SELECT AVG(temperature) FROM "weather_data"."hourly_weather" WHERE time >= '2024-10-01 14:00:00' AND time < '2024-10-01 16:00:00' AND state = 'CA';
クエリインサイト機能を使用すると、クエリの空間カバレッジを分析できます。QuerySpatialCoverage メトリクスが 0.02 の値を返すとします。つまり、クエリは空間軸の 2% しかスキャンせず、効率的です。この場合、クエリは空間範囲を効果的にプルーニングでき、カリフォルニアからのデータのみを取得し、他の州からのデータは無視します。
反対に、QuerySpatialCoverage のメトリクスが 0.8 の値を返した場合、クエリが空間軸の 80% をスキャンしたことを示し、効率は低くなります。これは、パーティショニング戦略を見直して空間プルーニングを改善する必要があることを示唆している可能性があります。例えば、パーティションキーを州ではなく都市またはリージョンとして選択できます。QuerySpatialCoverage メトリクスを分析することで、パーティショニング戦略を最適化し、クエリのパフォーマンスを向上させる機会を特定できます。
次の画像は、空間プルーニングが不十分なことを示しています。
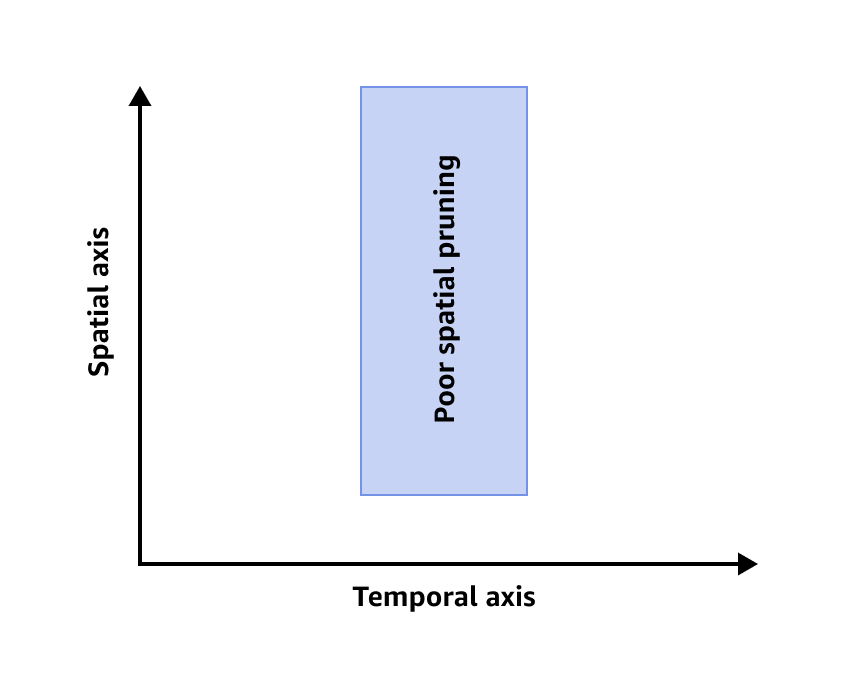
空間プルーニングの効率を高めるには、次のいずれかまたは両方を実行します。
-
デフォルトのパーティションキーである
measure_nameを追加するか、クエリで CDPK 述語を使用します。 -
前のポイントで説明した属性を既に追加している場合は、これらの属性または句に関する関数を削除します (
LIKEなど)。
QueryTemporalCoverage
QueryTemporalCoverage メトリクスは、スキャンされた時間範囲が最も大きいテーブルなど、実行されたクエリによってスキャンされた時間範囲に関するインサイトを提供します。QueryTemporalCoverage メトリクスの値は、ナノ秒単位で表される時間範囲です。このメトリクスの値が小さいほど、時間範囲のクエリプルーニングがより適切になります。例えば、過去数分間のデータをスキャンするクエリは、テーブルの時間範囲全体をスキャンするクエリよりもパフォーマンスが高くなります。
例
IoT センサーデータを保存する Timestream データベースがあり、製造工場にあるデバイスから毎分測定されているとします。device_ID でデータをパーティション化したとします。
クエリを実行して、特定のデバイスにおける過去 30 分間の平均センサー測定値を取得するとします。このシナリオのクエリは、次の例のようになります。
SELECT AVG(sensor_reading) FROM "sensor_data"."factory_1" WHERE device_id = 'DEV_123' AND time >= NOW() - INTERVAL 30 MINUTE and time < NOW();
クエリインサイト機能を使用すると、クエリによってスキャンされた時間範囲を分析できます。QueryTemporalCoverage メトリクスが 1800000000000 ナノ秒 (30 分) の値を返すとします。これは、クエリが過去 30 分間のデータのみをスキャンしたことを意味します。これは比較的狭い時間範囲です。クエリが時間パーティショニングを効果的にプルーニングし、リクエストされたデータのみを取得できたことを示しており、これは良い兆候です。
反対に、QueryTemporalCoverage メトリクスが 1 年の値をナノ秒単位で返した場合、クエリがテーブル内の 1 年間の時間範囲をスキャンしたことを示しており、効率は低くなります。この場合、クエリが時間プルーニング用に最適化されていないことを示唆しており、時間フィルターを追加することでクエリを改善できる可能性があります。
次の画像は、時間プルーニングが不十分なことを示しています。
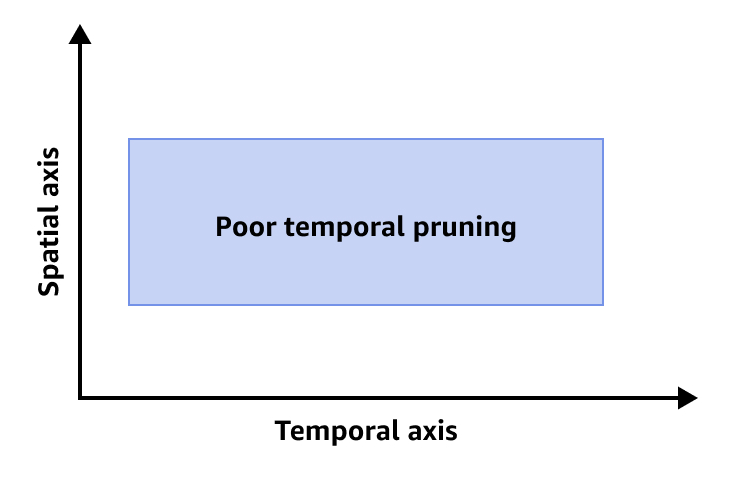
時間プルーニングを改善するには、次のいずれかまたはすべてを実行することをお勧めします。
-
欠落している時間の述語をクエリに追加し、時間の述語が目的の時間枠をプルーニングしていることを確認します。
-
時間の述語に関する
MAX()などの関数を削除します。 -
すべてのサブクエリに時間の述語を追加します。これは、サブクエリが大きなテーブルを結合している場合や、複雑なオペレーションを実行している場合に重要です。
