Amazon Timestream for LiveAnalytics に類似した機能をご希望の場合は Amazon Timestream for InfluxDB をご検討ください。リアルタイム分析に適した、シンプルなデータインジェストと 1 桁ミリ秒のクエリ応答時間を特徴としています。詳細については、こちらを参照してください。
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
アーキテクチャ
Amazon Timestream for LiveAnalytics は、時系列データを大規模に収集、保存、処理するためにゼロから設計されています。そのサーバーレスアーキテクチャは、個別にスケールできる完全に分離されたデータインジェスト、ストレージ、クエリ処理システムをサポートします。この設計により、各サブシステムが簡素化され、揺るぎない信頼性を実現し、スケーリングのボトルネックを排除し、相関するシステム障害の可能性を低下させることが容易になります。これらの各要因は、システムがスケールするにつれてより重要になります。
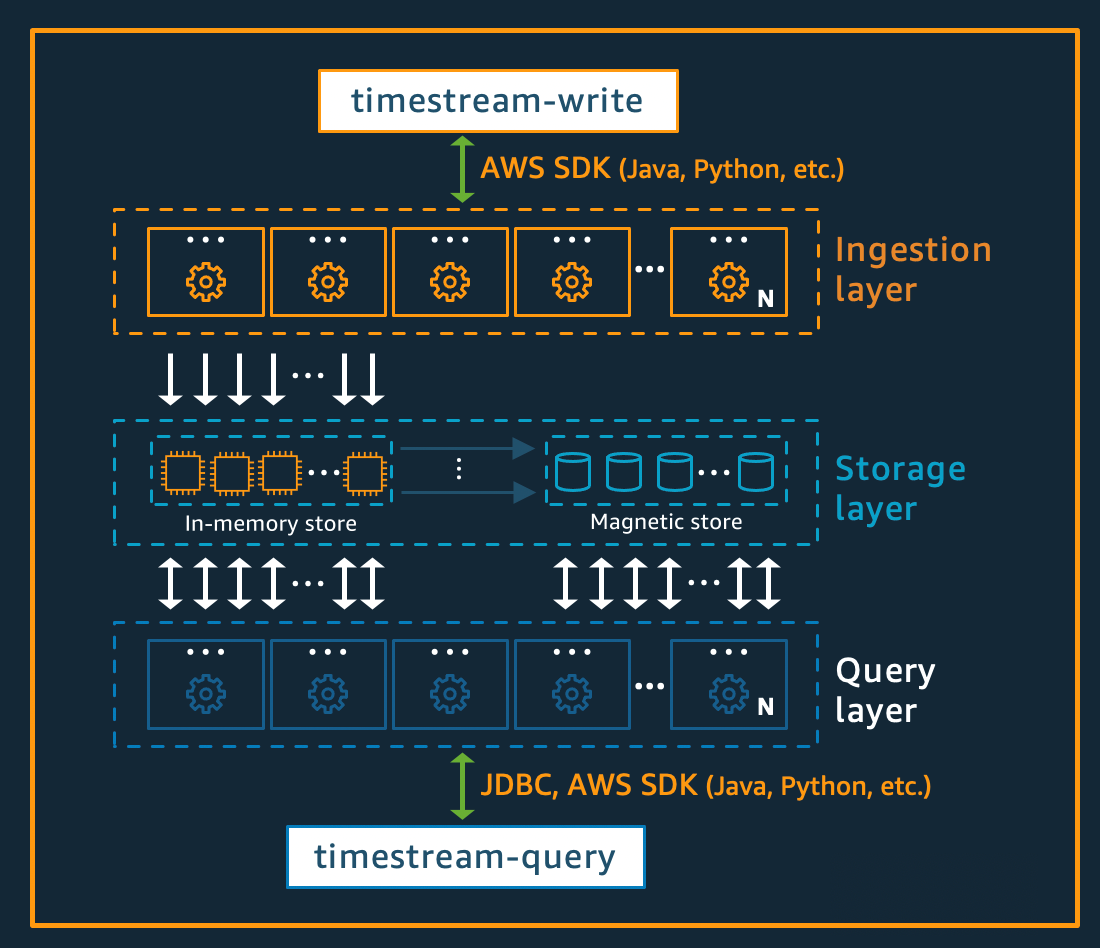
書き込みのアーキテクチャ
時系列データを書き込む場合、Amazon Timestream for LiveAnalytics は、テーブル、パーティションの書き込みを、高スループットのデータ書き込みを処理する耐障害性メモリストアインスタンスにルーティングします。メモリストアは、3 つのアベイラビリティーゾーン (AZ) にデータをレプリケートする別のストレージシステムで耐久性を実現します。レプリケーションはクォーラムベースであるため、ノードまたは AZ 全体の損失によって書き込みの可用性が損なわれることはありません。ほぼリアルタイムで、他のインメモリストレージノードはデータに同期してクエリを処理できるようにします。リーダーレプリカノードも AZ にまたがって、高い読み取り可用性を確保します。
Timestream for LiveAnalytics は、スループットの低い遅延受信データを生成するアプリケーション向けに、マグネティックストアへのデータの直接書き込みをサポートしています。遅延受信データとは、タイムスタンプが現時刻以前であるデータのことです。メモリストアの高スループット書き込みと同様に、マグネティックストアに書き込まれたデータは 3 つの AZ でレプリケーションされ、レプリケーションはクォーラムベースです。
データがメモリに書き込まれるかマグネティックストアに書き込まれるかにかかわらず、Timestream for LiveAnalytics は、ストレージに書き込む前にデータを自動的にインデックス化してパーティショニングします。1 つの Timestream for LiveAnalytics テーブルには、数百、数千、さらには数百万のパーティションが含まれる場合があります。個々のパーティションは相互に直接通信せず、データを共有しません (シェアードナッシングアーキテクチャ)。代わりに、テーブルのパーティショニングは、可用性の高いパーティション追跡およびインデックス作成サービスを通じて追跡されます。これにより、システム内の障害の影響を最小限に抑え、相関した障害が発生する可能性を大幅に低減するための特別な設計による、さらなる関心の分離が提供されます。
ストレージのアーキテクチャ
データが Timestream for LiveAnalytics に保存されると、データと共に書き込まれたコンテキスト属性に基づいて、時間順で経時的にデータが整理されます。時系列システムを大規模にスケールするには、時間に加えて「空間」を分割するパーティショニングスキームを持つことが重要です。これは、ほとんどの時系列データが現在の時刻またはその前後に書き込まれるためです。したがって、時間だけでのパーティショニングは、書き込みトラフィックを分散したり、クエリ時にデータを効果的にプルーニングしたりするのに適していません。これは極端な規模の時系列処理において重要であり、Timestream for LiveAnalytics は、現在、サーバーレス方式で他の主要なシステムよりも桁違いにスケールできます。結果のパーティションは「タイル」と呼ばれます。これは、2 次元空間の分割 (類似したサイズになるように設計されている) を表すためです。Timestream for LiveAnalytics テーブルは、単一のパーティション (タイル) として開始され、スループットに応じて空間ディメンションに分割されます。タイルが特定のサイズに達すると、データサイズが大きくなるにつれて読み取り並列性を向上させるために、時間ディメンションに分割されます。
Timestream for LiveAnalytics は、時系列データのライフサイクルを自動的に管理するように設計されています。Timestream for LiveAnalytics には、インメモリストアと費用対効果の高いマグネティックストアの 2 つのデータストアがあります。また、ストア間でデータを自動的に転送するようにテーブルレベルのポリシーを設定することもできます。受信高スループットデータ書き込みは、データが書き込み用に最適化されているメモリストアに入り、読み込みはダッシュボードとアラート型クエリの動作のために現在時刻前後に実行されます。書き込み、アラート、ダッシュボードのメイン時間枠が経過すると、データはメモリストアからマグネティックストアに自動的に流れ、コストが最適化されます。Timestream for LiveAnalytics では、この目的のためにメモリストアにデータ保持ポリシーを設定できます。遅延受信データのデータ書き込みは、マグネティックストアに直接実行されます。
データは、マグネティックストアで利用可能になると (メモリストアの保持期間が終了するため、またはマグネティックストアへの直接書き込みのため)、大量のデータ読み取りに高度に最適化された形式に再編成されます。マグネティックストアには、データが役目を終えたとする時間しきい値がある場合に設定できるデータ保持ポリシーもあります。データがマグネティックストア保持ポリシーで定義された時間範囲を超えると、自動的に削除されます。したがって、Timestream for LiveAnalytics では、一部の設定を除き、データライフサイクル管理がバックグラウンドでシームレスに行われます。
クエリのアーキテクチャ
Timestream for LiveAnalytics クエリは時系列固有のサポート (時系列固有のデータ型と関数) 用の拡張機能を持つ SQL 文法で表現されるため、SQL に既に精通している開発者は早く習得できます。その後、タイル追跡およびインデックス作成サービスのメタデータを使用して、クエリの発行時にデータストア間でシームレスにデータにアクセスしてデータを組み合わせる、適応型の分散クエリエンジンによってクエリは処理されます。これにより、複雑なプロセスの多くがシンプルで使い慣れたデータベース抽象化にまとめられるため、優れたユーザーエクスペリエンスが実現します。
クエリは複数の専用ワーカーフリートによって実行され、特定のクエリを実行するために登録されたワーカーの数はクエリの複雑さとデータサイズによって決まります。大規模なデータセットに対する複雑なクエリのパフォーマンスは、クエリランタイムフリートとシステムのストレージフリートの両方で、大規模な並列処理を通じて実現されます。大量のデータを迅速かつ効率的に分析できることは、Timestream for LiveAnalytics の最大の強みの 1 つです。テラバイト、さらにはペタバイト規模のデータに対して実行される単一のクエリでは、数千台のマシンが同時に動作する可能性があります。
セルラーアーキテクチャ
Timestream for LiveAnalytics がアプリケーションに事実上無限のスケーラビリティを提供し、同時に 99.99% の可用性を確保するために、システムはセルラーアーキテクチャも使用して設計されています。Timestream for LiveAnalytics は、システム全体をスケールするのではなく、セルと呼ばれるそれ自体の複数の小さなコピーにセグメント化します。これにより、セルをフルスケールでテストでき、いずれかのセルのシステム問題が特定のリージョンにおける他のセルのアクティビティに影響を与えるのを防ぐことができます。Timestream for LiveAnalytics はリージョンごとに複数のセルをサポートするように設計されていますが、リージョンに 2 つのセルがある次の架空のシナリオを検討してください。
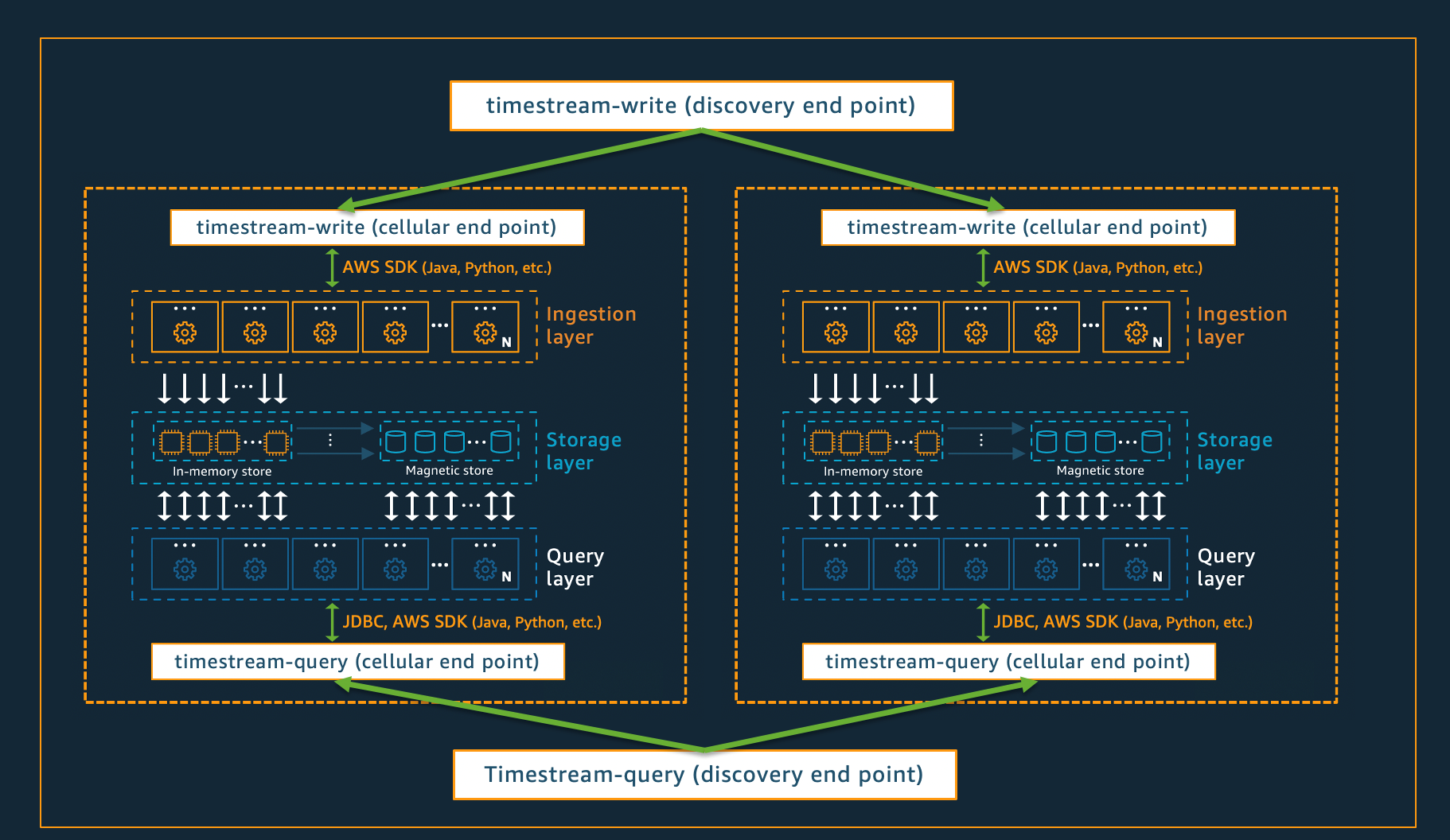
上記のシナリオでは、データインジェストリクエストとクエリリクエストは、それぞれデータインジェストとクエリの検出エンドポイントによって処理されます。次に、検出エンドポイントは顧客データを含むセルを識別し、そのセルの適切なインジェストエンドポイントまたはクエリエンドポイントにリクエストを送信します。SDK を使用する場合、これらのエンドポイント管理タスクは透過的に処理されます。
注記
Timestream for LiveAnalytics で VPC エンドポイントを使用する場合、または Timestream for LiveAnalytics の REST API オペレーションに直接アクセスする場合は、セルラーエンドポイントと直接やり取りする必要があります。これを行う方法のガイダンスについては、「VPC エンドポイント (AWS PrivateLink)」で VPC エンドポイントを設定する方法を確認してください。REST API オペレーションの直接呼び出しについては「エンドポイント検出パターン」を参照してください。
