序章
セキュリティは AWS の最優先事項です。AWS のお客様は、最もセキュリティを重視する組織のニーズをサポートするために構築されたデータセンターとネットワークアーキテクチャのメリットが得られます。AWS が使用する責任共有モデルでは、AWS はクラウドのセキュリティを管理し、お客様はクラウド内のセキュリティに責任を負います。つまり、セキュリティ目標の達成に役立つ複数のツールやサービスへのアクセスを含め、セキュリティの実装を完全に制御できます。これらの機能は、AWS クラウドで実行されているアプリケーションのセキュリティベースラインを確立するのに役立ちます。
設定ミスや外部要因の変更など、ベースラインからの逸脱が発生した場合は、対応して調査する必要があります。これを成功させるには、AWS 環境内のセキュリティインシデント対応の基本概念と、セキュリティ問題が発生する前にクラウドチームの準備、教育、トレーニングを行うための要件を理解する必要があります。使用できるコントロールと機能を把握し、潜在的な問題を解決するために現在問題となっている例を確認し、自動化を使用して対応速度と一貫性を向上させる修復方法を特定することが重要です。さらに、これらの要件を満たすためのセキュリティインシデント対応プログラムの構築に関連するコンプライアンス要件や規制要件を理解する必要があります。
セキュリティインシデント対応は複雑な場合があるため、反復的アプローチを実装することをお勧めします。つまり、まずコアセキュリティサービスから開始し、基本的な検出機能と対応機能を構築し、その後プレイブックを作成してインシデント対応メカニズムの初期ライブラリを作成し、これを反復して改善していきます。
[開始する前に]
AWS でのセキュリティイベントのインシデント対応について学習する前に、AWS のセキュリティおよびインシデント対応に関連する標準およびフレームワークを理解しましょう。これらの基礎は、このガイドで説明されている概念とベストプラクティスを理解するのに役立ちます。
AWS のセキュリティ標準とフレームワーク
まず、「セキュリティ、アイデンティティ、コンプライアンスに関するベストプラクティス」、「セキュリティの柱 - AWS Well-Architected フレームワーク
AWS CAF は、クラウドに移行する組織の各所での調整をサポートするガイダンスを提供します。AWS CAF ガイダンスは、クラウドベースの IT システムの構築に関連する、パースペクティブと呼ばれるいくつかの重点分野に分かれています。セキュリティパースペクティブは、ワークストリーム全体にセキュリティプログラムを実装する方法について説明するもので、その 1 つがインシデント対応です。本書は、お客様と連携し、効果的かつ効率的なセキュリティインシデント対応プログラムと各種機能の構築を支援してきた当社の経験の成果です。
業界のインシデント対応標準とフレームワーク
このホワイトペーパーは、米国国立標準技術研究所 (NIST) が作成した「コンピュータセキュリティインシデント対応ガイド 800-61 r3
AWS インシデント対応の概要
まず、クラウドにおけるセキュリティオペレーションとインシデント対応の違いを理解することが重要です。AWS で効果的な対応機能を構築するには、従来のオンプレミス対応からの違いと、インシデント対応プログラムに対するその影響を理解する必要があります。これらの各違いと、AWS インシデント対応の主要な設計原則について、このセクションで詳しく説明します。
AWS におけるインシデント対応の諸側面
組織内のすべての AWS ユーザーは、セキュリティインシデント対応プロセスの基本を理解している必要があり、セキュリティ担当者はセキュリティ問題への対応方法を理解している必要があります。教育、トレーニング、経験は、クラウドインシデント対応プログラムを成功させるために不可欠であり、起こり得るセキュリティインシデントに対処する前に十分な余裕を持って実施するのが理想的です。クラウドでのインシデント対応プログラムの成功基盤は、準備、オペレーション、インシデント後アクティビティです。
これらの各側面を理解するには、以下の説明を参考にしてください。
-
準備 – 検出制御を有効にし、必要なツールやクラウドサービスへの適切なアクセスを検証することで、インシデント対応チームが AWS 内のインシデントを検出して対応できるように準備します。さらに、信頼性の高い一貫した応答を検証するために、手動と自動の両方で必要なプレイブックを準備します。
-
オペレーション – NIST のインシデント対応フェーズ (検出、分析、封じ込め、根絶、復旧) に従って、セキュリティイベントと潜在的なインシデントに対処します。
-
インシデント後アクティビティ – セキュリティイベントとシミュレーションの結果を反復することで、対応の有効性を改善し、対応と調査から得られる価値を高め、リスクをさらに軽減します。インシデントから学び、改善活動に対する強いオーナーシップを持つ必要があります。
これらの各側面については、本書で詳しく説明します。下図は、前述の NIST のインシデント対応ライフサイクルに沿った、これらの側面のフローを示しています。ここでの業務には、検出と分析に加えて、封じ込め、根絶、復旧が含まれています。
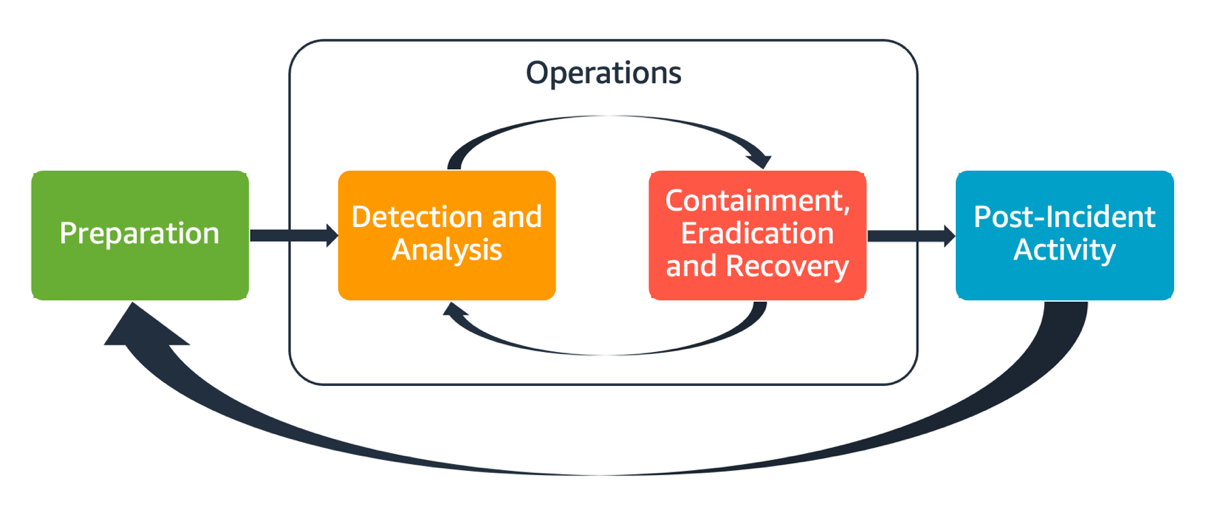
AWS インシデント対応の諸側面
AWS インシデント対応の原則と設計目標
「NIST SP 800-61 コンピュータセキュリティインシデント対応ガイド
-
対応目標の確立 – ステークホルダー、法律顧問、組織のリーダーと協力してインシデント対応の目標を決定します。共通の目標には、問題の封じ込めと緩和、影響を受けたリソースの復旧、フォレンジック用のデータの保全、既知の安全な運用への復帰、そして最終的にはインシデントからの学習などがあります。
-
クラウドを使用して対応する – イベントとデータが発生するクラウド内に対応パターンを実装します。
-
持っているものと必要なものを知る – ログ、リソース、スナップショット、その他の証拠は、対応専用の一元化されたクラウドアカウントにコピーして保存します。管理ポリシーを適用するタグ、メタデータ、メカニズムを使用します。使用しているサービスを把握し、それらのサービスを調査するための要件を特定する必要があります。環境を理解しやすくするために、タグ付けを使用することもできます。タグ付けについては、本書の「タグ付け戦略を策定し、実装する」セクションで後述します。
-
再デプロイメカニズムを使用する – セキュリティの異常が設定ミスに起因する場合は、適切な設定でリソースを再デプロイして差異を取り除くだけで解決できる場合があります。セキュリティ侵害の可能性が見つかった場合は、根本原因に対する適切で検証済みの緩和策が再デプロイに含まれていることを確認します。
-
可能な場合は自動化する – 問題が発生したり、インシデントが繰り返されたりした場合は、一般的なイベントをプログラムで優先順位付けして対応するメカニズムを構築します。自動化が不十分で、特殊かつ複雑、または機密性の高いインシデントには、人手で対応します。
-
スケーラブルなソリューションを選択する – 組織のアプローチのスケーラビリティがクラウドコンピューティングと適合しているように努めます。環境全体にスケールできる検出および対応のメカニズムを実装して、検出から対応までの時間を効果的に短縮します。
-
プロセスを学び、改善する – プロセス、ツール、人員におけるギャップを積極的に特定し、それらを修正する計画を実施します。シミュレーションは、ギャップを見つけてプロセスを改善する安全な方法です。プロセスを反復的に実行する方法の詳細については、本書の「インシデント後のアクティビティ」セクションを参照してください。
これらの設計目標は、インシデント対応と脅威検知の両方を実施する能力について、アーキテクチャの実装を確認することを促すものです。クラウドの実装を計画するときは、インシデントへの対応を検討します。フォレンジックに基づいた対応方法論を使用するのが理想的です。これは、場合によっては、このような対応タスク用に複数の組織、アカウント、ツールを特別に設定することを意味します。これらのツールと機能は、デプロイパイプラインによってインシデント対応担当者が利用できるようにする必要があります。リスクを大きくする可能性があるため、静的な状態のままにしないでください。
クラウドセキュリティインシデントのドメイン
AWS 環境内のセキュリティイベントに効果的に備え、対応するには、クラウドセキュリティインシデントの一般的なタイプを理解する必要があります。セキュリティインシデントが発生する可能性があるのは、サービス、インフラストラクチャ、アプリケーションの 3 つのドメインで、これらはお客様の責任の範囲内にあります。ドメインごとに異なる知識、ツール、対応プロセスが必要です。以下のドメインについて考えてください。
-
サービスドメイン – サービスドメイン内のインシデントは、AWS アカウント、AWS Identity and Access Management
(IAM) アクセス許可、リソースメタデータ、請求、またはその他の領域に影響する可能性があります。サービスドメインのイベントは、AWS API メカニズムでのみ対応するか、設定またはリソースのアクセス許可に関連する根本原因があり、関連するサービス指向のログ記録がある可能性があるイベントです。 -
インフラストラクチャドメイン – インフラストラクチャドメイン内のインシデントには、Amazon Elastic Compute Cloud
(Amazon EC2) インスタンス上のプロセスやデータ、仮想プライベートクラウド (VPC) 内の Amazon EC2 インスタンスへのトラフィック、コンテナやその他の将来のサービスといったその他の領域など、データまたはネットワーク関連のアクティビティが含まれます。インフラストラクチャドメインのイベントへの対応には、多くの場合、フォレンジック分析のためのインシデント関連データの取得が含まれます。これには、インスタンスのオペレーティングシステムとのやり取りが含まれる可能性が高く、さまざまなケースで AWS API メカニズムが含まれる場合もあります。インフラストラクチャドメインでは、フォレンジック分析と調査を実行する専用の Amazon EC2 インスタンスなど、ゲストオペレーティングシステム内で AWS API とデジタルフォレンジック/インシデントレスポンス (DFIR) ツールの組み合わせを使用できます。インフラストラクチャドメインのインシデントには、ネットワークパケットキャプチャ、Amazon Elastic Block Store (Amazon EBS) ボリュームのディスクブロック、またはインスタンスから取得した揮発性メモリの分析が含まれる場合があります。 -
アプリケーションドメイン – アプリケーションドメイン内のインシデントは、アプリケーションコードや、サービスまたはインフラストラクチャにデプロイされたソフトウェアで発生します。このドメインは、クラウドの脅威の検出と対応プレイブックに含める必要があり、インフラストラクチャドメイン内のインシデントと同様の対応を組み込むことができます。適切で十分に検討されたアプリケーションアーキテクチャでは、自動取得、復旧、デプロイメントを使用して、クラウドツールでこのドメインを管理できます。
これらのドメインでは、AWS アカウント、リソース、またはデータに対して行動を起こすアクターについて検討してください。内部のリスクか外部のリスクかにかかわらず、リスクフレームワークを使用して組織に対する特定のリスクを判断し、それに応じて準備します。さらに、インシデント対応計画の立案や十分に検討されたアーキテクチャの構築に役立つ脅威モデルを開発する必要があります。
AWS でのインシデント対応の主な違い
インシデント対応は、オンプレミスまたはクラウドにおけるサイバーセキュリティ戦略に不可欠な要素です。最小特権や多層防御などのセキュリティ原則は、オンプレミスとクラウドの両方でデータの機密性、完全性、可用性を保護することを目的としています。これらのセキュリティ原則をサポートするいくつかのインシデント対応パターンには、ログ保持、脅威モデリングから派生したアラート選択、プレイブック作成、セキュリティ情報およびイベント管理 (SIEM) の統合が含まれます。お客様がクラウドでこれらのパターンの設計とエンジニアリングを開始するときから違いが生じます。以下は、AWS でのインシデント対応の主な相違点です。
相違点 #1: 責任共有としてのセキュリティ
セキュリティとコンプライアンスの責任は、AWS とお客様の間で共有されます。この共有責任モデルにより、お客様の運用の負担が軽減されます。これは、ホストオペレーティングシステムや仮想化レイヤーからサービスが運用されている施設の物理的なセキュリティに至るまで、さまざまなコンポーネントを AWS が運用、管理、制御するためです。責任共有モデルの詳細については、「責任共有モデル
クラウドにおける責任共有が変更されると、インシデント対応のオプションも変わります。これらのトレードオフを計画して理解し、ガバナンスのニーズと一致させることは、インシデント対応における重要なステップです。
AWS との直接的な関係以外にも、特定の責任モデルにおいて責任を持つ他のエンティティが存在する可能性があります。例えば、オペレーションの一部の側面に責任を持つ内部組織単位があるかもしれません。また、クラウドテクノロジーの一部を開発、管理、運用する他の関係者との関係があるかもしれません。
運用モデルに合った適切なインシデント対応計画と適切なプレイブックを作成し、テストすることは非常に重要です。
相違点 #2: クラウドサービスドメイン
クラウドサービスに存在するセキュリティ上の責任の違いにより、セキュリティインシデントの新しいドメインである「サービスドメイン」が導入されました。これについては、「インシデントドメイン」セクションで前述しました。サービスドメインには、お客様の AWS アカウント、IAM アクセス許可、リソースメタデータ、請求、およびその他の領域が含まれます。このドメインの相違点は、インシデント対応の方法が異なることです。サービスドメイン内の対応は通常、従来のホストベースおよびネットワークベースの対応ではなく、API コールの確認と発行によって行われます。サービスドメインでは、影響を受けるリソースのオペレーティングシステムとはやり取りしません。
次の図は、アーキテクチャのアンチパターンに基づくサービスドメインのセキュリティイベントの例を示しています。このイベントでは、権限のないユーザーが IAM ユーザーの長期的なセキュリティ認証情報を取得します。この IAM ユーザーは、Amazon Simple Storage Service
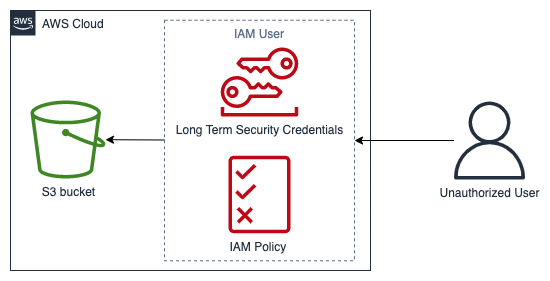
サービスドメインの例
相違点 #3: インフラストラクチャをプロビジョニングするための API
もう 1 つの相違点は、オンデマンドセルフサービスのクラウド特性
API ベースである AWS の性質上、セキュリティイベントに対応するための重要なログソースは AWS CloudTrail です。これは AWS アカウントで行われた管理 API コールを追跡し、API コールの送信元の場所に関する情報を見つけることができます。
相違点 #4: クラウドの動的な性質
クラウドは動的であり、リソースをすばやく作成および削除できます。自動スケーリングを使用すると、トラフィックの増加に基づいてリソースをスピンアップおよびスピンダウンできます。存続期間の短いインフラストラクチャとペースの速い変更により、調査対象のリソースがもはや存在しない、または変更されていることがあります。AWS リソースのエフェメラルな性質と、AWS リソースの作成と削除を追跡する方法を理解することが、インシデント分析で重要になります。AWS Config
相違点 #5: データアクセス
クラウドではデータアクセスも異なります。セキュリティ調査に必要なデータを収集するためにサーバーに接続することはできません。データは、有線および API コールを介して収集されます。この変化に備えるために、API でデータ収集を実行する方法を練習して理解し、効果的な収集とアクセスのための適切なストレージがあることを検証する必要があります。
相違点 #6: 自動化の重要性
お客様がクラウド導入のメリットを完全に実感するには、運用戦略に自動化を採用する必要があります。Infrastructure as Code (IaC) は、AWS サービスがコードを使用してデプロイ、設定、再設定、破棄される、効率に優れた自動化環境のパターンの 1 つであり、AWS CloudFormation
これらの相違点に対処する
これらの相違点に対処するには、次のセクションで説明するステップに従って、人員、プロセス、テクノロジー全体でインシデント対応プログラムが適切に準備されていることを確認します。
